
GAN训练的难点
我试着训练一个GAN来学习在一个事件中的一些特征的分布。被训练的鉴别器和生成器具有较低的损耗,但是生成的事件有不同的形状分布,但我不知道为什么。
我对GAN的定义如下:
def create_generator():
generator = Sequential()
generator.add(Dense(50,input_dim=noise_dim))
generator.add(LeakyReLU(0.2))
generator.add(Dense(25))
generator.add(LeakyReLU(0.2))
generator.add(Dense(5))
generator.add(LeakyReLU(0.2))
generator.add(Dense(len(variables), activation='tanh'))
return generator
def create_descriminator():
discriminator = Sequential()
discriminator.add(Dense(4, input_dim=len(variables)))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dense(4))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dense(4))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dense(1, activation='sigmoid'))
discriminator.compile(loss='binary_crossentropy', optimizer=optimizer)
return discriminator
discriminator = create_descriminator()
generator = create_generator()
def define_gan(generator, discriminator):
# make weights in the discriminator not trainable
discriminator.trainable = False
model = Sequential()
model.add(generator)
model.add(discriminator)
model.compile(loss = 'binary_crossentropy', optimizer=optimizer)
return model
gan = define_gan(generator, discriminator)我用这个回路训练GAN:
for epoch in range(epochs):
for batch in range(steps_per_epoch):
noise = np.random.normal(0, 1, size=(batch_size, noise_dim))
fake_x = generator.predict(noise)
real_x = x_train[np.random.randint(0, x_train.shape[0], size=batch_size)]
x = np.concatenate((real_x, fake_x))
# Real events have label 1, fake events have label 0
disc_y = np.zeros(2*batch_size)
disc_y[:batch_size] = 1
discriminator.trainable = True
d_loss = discriminator.train_on_batch(x, disc_y)
discriminator.trainable = False
y_gen = np.ones(batch_size)
g_loss = gan.train_on_batch(noise, y_gen)我的真实事件使用sklearn标准定标器进行缩放:
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)产生事件:
X_noise = np.random.normal(0, 1, size=(n_events, GAN_noise_size))
X_generated = generator.predict(X_noise)然后,当我在训练了几百到几千次之后使用经过训练的GAN生成新的事件并进行扩展,我得到的发行版如下所示:
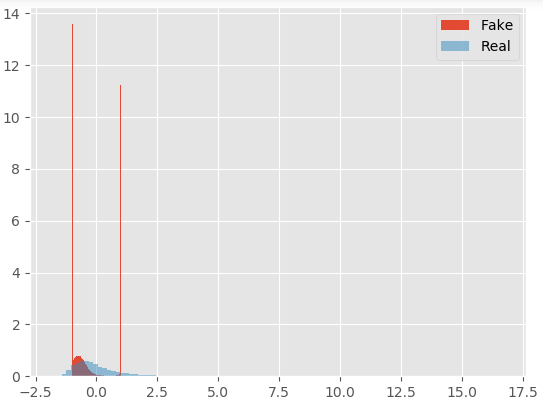
在真实和假的事件中,两种特征互相勾勒:

这看起来类似于模式崩溃,但我不认为这会导致这些极值,在这些点之后,所有的东西都被切断了。
回答 1
Stack Overflow用户
发布于 2020-03-27 03:23:29
模式崩溃导致生成器找到几个值或小范围的值,这些值在欺骗鉴别器方面做得最好。由于您生成的值范围相当窄,我相信您正在经历模式崩溃。您可以对不同的时间进行培训,并绘制结果以查看崩溃发生的时间。有时,如果你训练足够长的时间,它会修复自己,重新开始学习。关于如何训练甘斯,我有十亿条建议,我收集了一堆人,然后用蛮力通过他们,为每一个甘。您可以尝试每隔一个周期对鉴别器进行一次培训,以便给生成器一个学习机会。另外,有几个人建议不要同时对鉴别者进行真假数据的培训(我还没有这么做,所以我也说不出影响是什么)。您可能还想尝试添加一些批处理规范化层。詹森·布朗利()有一堆关于训练甘斯的好文章,你可能想从那里开始。
https://stackoverflow.com/questions/60658198
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号