
ValueError:预测新价值观时的维度失配情绪分析
ValueError:预测新价值观时的维度失配情绪分析
提问于 2020-03-14 19:03:18
我对机器学习这门学科还比较陌生。我试着做情绪分析预测。
类型列包括推特的情绪(pos、neg或中性为0、1和2)。Tweet列包括Tweet。
我试图预测新的推特的情绪为0,1和2。
当我编写这里给出的代码时,我得到了维数不匹配错误。
import pandas as pd
train_tweets = pd.read_csv("tweets_type.csv")
from sklearn.model_selection import train_test_split
y = train_tweets.Type
X= train_tweets.Tweet
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=1)
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
vect.fit(train_X)
train_X_dtm = vect.transform(train_X)
test_X_dtm = vect.transform(test_X)
test_X_dtm
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
%time nb.fit(train_X_dtm, train_y)
# make class predictions for X_test_dtm
y_pred_class = nb.predict(test_X_dtm)
# calculate accuracy of class predictions
from sklearn import metrics
from sklearn.metrics import classification_report, confusion_matrix
metrics.accuracy_score(test_y, y_pred_class)
march_tweets = pd.read_csv("march_data.csv")
X=march_tweets.Tweet
vect.fit(X)
train_new_dtm = vect.transform(X)
new_pred_class = nb.predict(train_new_dtm)我所犯的错误是:
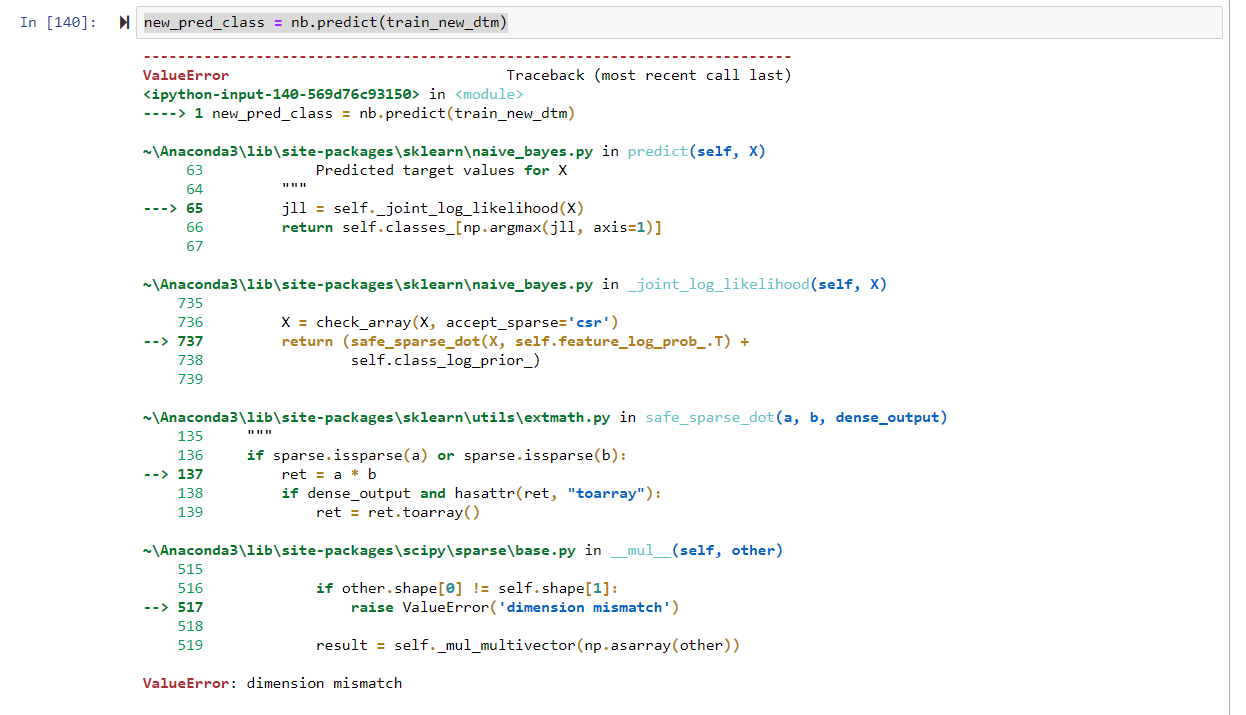
如果你能帮我的话会很高兴的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-03-15 04:33:16
在我安装了train_X之后,我似乎犯了一个错误,我发现一旦你安装了模型,就没有必要重复这样做了。所以我做的是去掉这条线,它工作得很好。
vect.fit(X)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60686336
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号