
Python gaussian.mixture如何获取每个集群中的样本/点
Python gaussian.mixture如何获取每个集群中的样本/点
提问于 2020-04-07 16:21:43
我使用GMM将我的数据集聚成K组,我的模型运行良好,但是没有办法从每个集群中获取原始数据,你们能给我一些解决这个问题的想法吗?非常感谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-04-08 01:50:48
您可以这样做(看看d0、d1和d2)。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import DataFrame
from sklearn import datasets
from sklearn.mixture import GaussianMixture
# load the iris dataset
iris = datasets.load_iris()
# select first two columns
X = iris.data[:, 0:2]
# turn it into a dataframe
d = pd.DataFrame(X)
# plot the data
plt.scatter(d[0], d[1])
gmm = GaussianMixture(n_components = 3)
# Fit the GMM model for the dataset
# which expresses the dataset as a
# mixture of 3 Gaussian Distribution
gmm.fit(d)
# Assign a label to each sample
labels = gmm.predict(d)
d['labels']= labels
d0 = d[d['labels']== 0]
d1 = d[d['labels']== 1]
d2 = d[d['labels']== 2]
# here is a possible solution for you:
d0
d1
d2
# plot three clusters in same plot
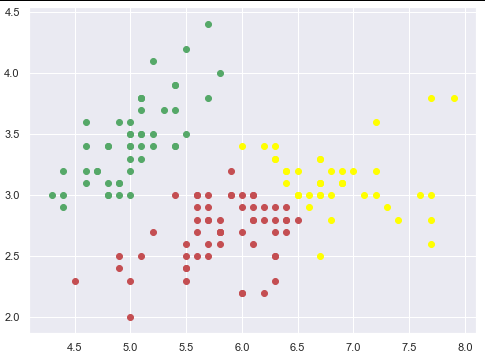
plt.scatter(d0[0], d0[1], c ='r')
plt.scatter(d1[0], d1[1], c ='yellow')
plt.scatter(d2[0], d2[1], c ='g')
# print the converged log-likelihood value
print(gmm.lower_bound_)
# print the number of iterations needed
# for the log-likelihood value to converge
print(gmm.n_iter_)
# it needed 8 iterations for the log-likelihood to converge.页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61084665
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号