
为什么当我继续再培训的时候,验证的准确性有了很大的提高?
为什么当我继续再培训的时候,验证的准确性有了很大的提高?
提问于 2020-07-18 06:58:44
问题:在第二次训练模型时,我的验证精度有了很大的提高。想知道为什么复制(如果可能的话)复制。
我将模型输出保存为".h5“格式。
我的验证精度徘徊在"~0.47“在过去的几百个时代,第一轮我训练的模型。以"0.6709“的精度结束。
(最后培训结果-第一次培训)

这是我模特的层次。我使用Keras-Tuner提取最佳的模型体系结构(即验证的准确性)。
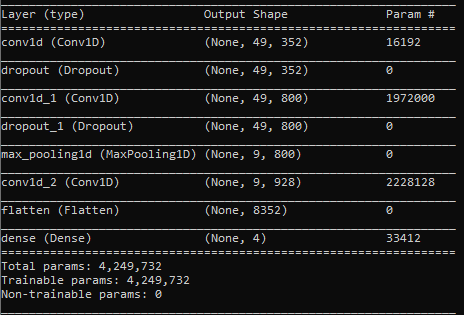
我使用的批次大小为"512“中的"~750,000”训练例子: 1/1473。
我继续对该模型进行培训(通过使用Keras模型),它开始在"0.5564“中进行培训。然而,验证的准确性一直跳到"0.6560“。提高了近20%。然后它开始向下移动。边注-重组是训练前对数据集进行预处理的一部分:
(第二次培训)
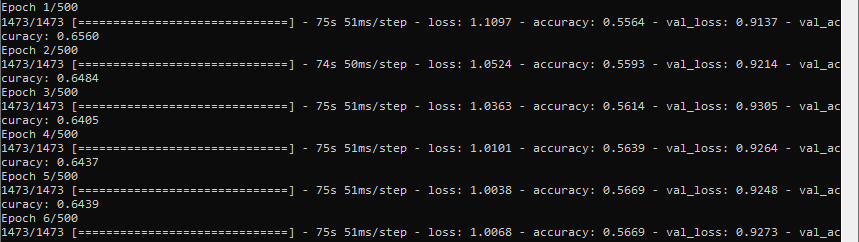
所以我有几个问题:
为什么验证精度会跳得这么高/当我重新加载模型进行再培训时--但是当训练正常通过时,当我重新训练模型时,它是否从训练精度“"0.48"?
- Why 0.6709”下降到"0.5564"?(有人告诉我,这是由于批量训练,但在512/750,000时,应该是相对较小的下降?除非它的数据reshuffling...)
)。
回答 1
Stack Overflow用户
发布于 2020-07-18 07:12:06
我将一些验证数据重组到了培训数据中。这就是跳伞的原因。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62965622
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号