
角星2.4。产生与2.3.1完全不同的产出
我正在尝试实现自动编码器。使用mnsit数据集,首先对图像进行编码,然后对它们进行解码。当我使用KerasVersion2.3.1时,我得到的解码图像非常接近原始图像,但是在使用Keras2.4.3和代码不改变的情况下,我得到的输出与接近垃圾的解码图像完全不同。我试图找出原因,但找不到任何原因,也没有任何关于如何从2.3.1迁移到2.4.3的文档或文章。
--这是带有Keras2.3.1的输出
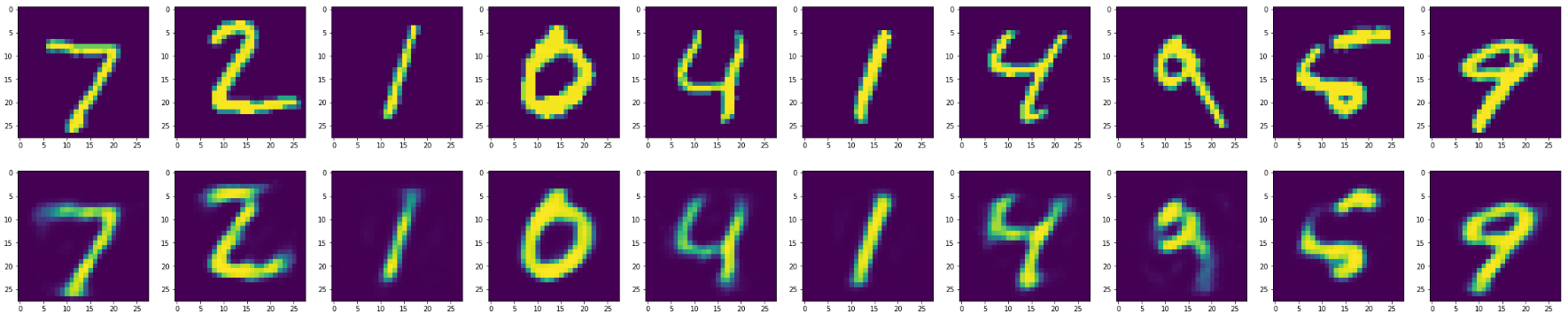
带有Keras2.4.3的输出
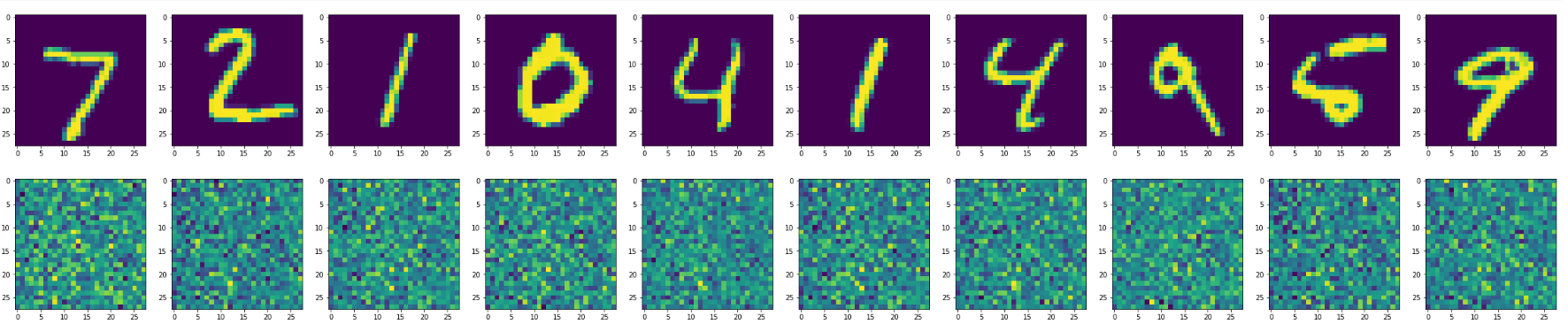
您可以在google或下面找到代码,请注意google使用Keras2.3.1
import keras
from keras.layers import Input, Dense
from keras.models import Model
import numpy as np
input_img = Input(shape=(784,)) #input layer
encoded = Dense(32, activation="relu")(input_img) # encoder
decoded = Dense(784, activation='sigmoid')(encoded) # decocer, output
# defining autoenoder model
autoencoder = Model(input_img, decoded) # autoencoder = encoder+decoder
# defining encoder model
encoder = Model(input_img, encoded) # takes input images and encoded_img
# defining decoder model
encoded_input = Input(shape=(32,))
decoded_layer = autoencoder.layers[-1](encoded_input)
decoder = Model(encoded_input, decoded_layer)
autoencoder.compile(optimizer = 'adadelta', loss='binary_crossentropy')
# Test on images
from keras.datasets import mnist
(x_train, _), (x_test, _) = mnist.load_data()
# Normalize the value between 0 and 1 and flatten 28x28 images in to vector of 784
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
# reshaping (60000, 28,28) -> (60000, 784)
x_train = x_train.reshape(len(x_train), np.prod(x_train.shape[1:]))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
autoencoder.fit(x_train, x_train, epochs=50, batch_size=200 )
encoded_img = encoder.predict(x_test)
decoded_img = decoder.predict(encoded_img)
encoded_img.shape, decoded_img.shape
# Performing Visualization
import matplotlib.pyplot as plt
n = 10
plt.figure(figsize=(40, 8))
for i in range(n):
plt.subplot(2, n, i+1)
plt.imshow(x_test[i].reshape(28, 28))
# Recontructed Imgae
plt.subplot(2, n, n+i+1)
plt.imshow(decoded_img[i].reshape(28, 28))
plt.show() 有什么建议吗?
回答 2
Stack Overflow用户
发布于 2020-07-20 16:00:17
看起来,Keras中的Adadelta优化器的默认学习速率是1.0,而在tf.keras中是0.001。当您切换到tf.keras时,Adadelta的学习速率太小,网络什么也学不到。在编译模型之前,您可以按如下方式更改学习速度,并且在tf.keras中将得到与keras中相同的行为。
opt = tf.keras.optimizers.Adadelta(learning_rate=1.0)
autoencoder.compile(optimizer = opt, loss='binary_crossentropy')Stack Overflow用户
发布于 2020-07-20 11:17:40
之所以会发生这种情况,是因为Keras2.4实际上只是tf.keras的一个包装器,所以您的代码有效地使用了tf.keras,以及它所包含的所有bug。
如果您想要“经典keras”行为(特别是如果您使用keras而不是tf.keras开发了所有代码),那么您应该使用Keras2.3.1而不是升级到较新的版本。
https://stackoverflow.com/questions/62986313
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号