
查准率及召回1
查准率及召回1
提问于 2020-08-17 22:34:03
我正在用DNN解决一个问题。有两个输入变量(包括范畴变量)和一个目标变量(二进制变量)。试验数据的准确度为99.95%。我做了交叉验证(10倍),其准确性为99.96 (+- 0.05)。
在我的结果中,我看到了1.0的精确性和回忆性。我在这里附上了混淆矩阵和分类报告的图片。
Q1。这种行为可以吗?
Q2。当我在相同的参数下再次运行相同的模型时,每次得到不同的混淆矩阵,但精度总是接近99。
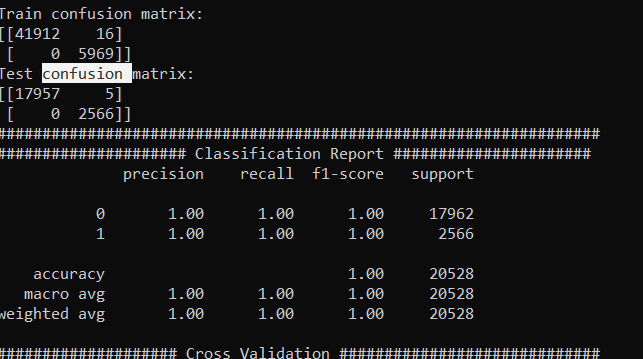
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-17 22:47:52
首先,您没有一个纯的1.00 查准率与召回;这只是报告的数字,它被四舍五入到小数点后两位。正如您已经说过的,您的测试精度和交叉验证的准确性都远远超过99.5%,这一阈值为1.00。在2000年,当你的实验错误率低于一个部分时,你就会得到这个结果。
这就引出了这样一个问题:一个受过训练的模型是否有理由拥有如此高的精确度:是的,是的。潜在的准确性取决于数据集中的信息可分离性:是否可能为给定的数据提取一个可分离的空间?只要输出是输入的一个(确定性)函数,您的模型就可以达到100%的精度。您只是有一个数据集,其中(几乎)是可能的。
清楚了吗?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63459503
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号