
科学知识工具中纵向/面板数据的交叉验证-学习
我有一些纵向/面板数据,其形式如下(数据输入代码在问题下面)。X和y的观测是按时间和国家编制索引的(例如,美国在时间1,美国在时间2,可以在时间1)。
time x y
USA 1 5 10
USA 2 5 12
USA 3 6 13
CAN 1 2 2
CAN 2 2 3
CAN 3 4 5我正在尝试使用sklearn来预测y。对于一个可重复的例子,我们可以使用,比如说,线性回归。
为了执行简历,我不能使用test_train_split,因为这样的拆分可能会将来自time = 3的数据放入X_train中,而将来自time = 2的数据放入y_test中。这将是没有帮助的,因为在time = 2,当我们试图预测y时,我们还没有真正的time = 3数据来进行培训。
我试图使用TimeSeriesSplit来实现简历,如下图所示:
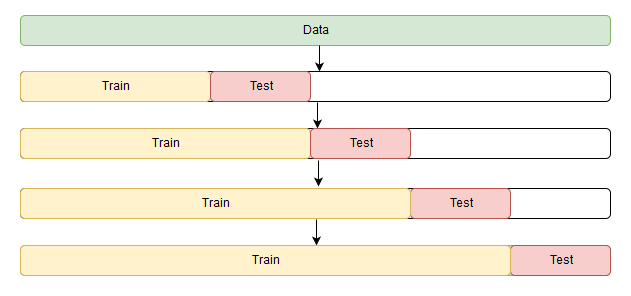
y = df.y
X = df.drop(['y'], 1)
print(y)
print(X)from sklearn.model_selection import TimeSeriesSplit
X = X.to_numpy()
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits = 2, max_train_size=3)
print(tscv)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]这与我所需要的很接近,但不完全是:
TRAIN: [0 1] TEST: [2 3]
TRAIN: [1 2 3] TEST: [4 5]- 现在如何使用
TimeSeriesSplit索引交叉验证模型?
我认为一个复杂的问题可能是我的数据不是严格的时间序列:它不仅是由time索引的,而且也是由country索引的,因此数据的纵向/面板性质。
我想要的输出是:
- 一系列测试和训练指标,使我能够“向前走”CV
例如
TRAIN: [1] TEST: [2]
TRAIN: [1 2] TEST: [3]- a
X_train,x_test,y_test,y_train,它们是根据time的值使用上面的索引分割的,或者是关于是否需要这样做的清晰性。
- 任何型号的精度分数(例如。线性回归)交叉验证使用“向前”的CV方法。
编辑:谢谢@sabacherli回答了我问题的第一部分,并修复了正在抛出的错误。
数据输入代码
import numpy as np
import pandas as pd
data = np.array([['country','time','x','y'],
['USA',1, 5, 10],
['USA',2, 5, 12],
['USA',3,6, 13],
['CAN',1,2, 2],
['CAN',2,2, 3],
['CAN',3,4, 5]],
)
df = pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:])
df回答 1
Stack Overflow用户
发布于 2020-08-20 08:13:21
TimeSeriesSplit假定您的数据集是按时间索引的,这意味着每一行都属于不同的时间步骤。那么,为什么不对数据进行unstack,这样您就只有时间作为索引,然后再拆分。拆分后,您可以再次stack数据形状,以获取基础表以进行培训。
data = np.array([['country','time','x','y'],
['USA',1, 5, 10],
['USA',2, 5, 12],
['USA',3,6, 13],
['CAN',1,2, 2],
['CAN',2,2, 3],
['CAN',3,4, 5]],
)
df = pd.DataFrame(data=data[1:,1:],
index=data[1:,0],
columns=data[0,1:])
df1 = df.reset_index().set_index(['time','index']).unstack(-1)
print(df1) x y
index CAN USA CAN USA
time
1 2 5 2 10
2 2 5 3 12
3 4 6 5 13现在,由于每一行都是按时间索引的,您可以很容易地将这些数据分成组,然后在拆分后,再次堆栈以获得X_train X_test等.
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits = 2, max_train_size=3)
X_cols = ['time', 'index', 'x']
y_cols = ['y']
for train_index, test_index in tscv.split(df1):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = df1.iloc[train_index].stack(-1).reset_index()[X_cols].to_numpy(), df1.iloc[test_index].stack(-1).reset_index()[X_cols].to_numpy()
y_train, y_test = df1.iloc[train_index].stack(-1).reset_index()[y_cols].to_numpy(), df1.iloc[test_index].stack(-1).reset_index()[y_cols].to_numpy()TRAIN: [0] TEST: [1]
TRAIN: [0 1] TEST: [2]你可以打印最新的折叠的X_train和y_train来看看发生了什么-
print('For - TRAIN: [0 1] TEST: [2]')
print(" ")
print("X_train:")
print(X_train)
print(" ")
print("X_test:")
print(X_test)
print(" ")
print("y_train:")
print(y_train)
print(" ")
print("y_test:")
print(y_test)
print("X_train:")
print(X_train)
print(" ")
print("X_test:")
print(X_test)
print(" ")
print("y_train:")
print(y_train)
print(" ")
print("y_test:")
print(y_test)For - TRAIN: [0 1] TEST: [2]
X_train:
[['1' 'CAN' '2']
['1' 'USA' '5']
['2' 'CAN' '2']
['2' 'USA' '5']]
X_test:
[['3' 'CAN' '4']
['3' 'USA' '6']]
y_train:
[['2']
['10']
['3']
['12']]
y_test:
[['5']
['13']]因此,现在您可以按时间拆分数据,并将其扩展到训练所需的形状。
https://stackoverflow.com/questions/63499684
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号