
用定量分类器识别不同的关键词
用定量分类器识别不同的关键词
提问于 2020-09-11 10:50:52
我是新的定量文本分析,我试图从一个朴素贝叶斯分类器的输出中提取与特定分类类别相关的关键字。我正在运行下面的例子(将电影评论分为积极的或消极的)。我想要两个向量,每个向量包含那些分别与正类和负类相关的关键字。我说得对吗?我应该把重点放在汇总()输出中的“估计的特征分数”上,如果是的话,我该如何解释这些?
require(quanteda)
require(quanteda.textmodels)
require(caret)
corp_movies <- data_corpus_moviereviews
summary(corp_movies, 5)
# generate 1500 numbers without replacement
set.seed(300)
id_train <- sample(1:2000, 1500, replace = FALSE)
head(id_train, 10)
# create docvar with ID
corp_movies$id_numeric <- 1:ndoc(corp_movies)
# get training set
dfmat_training <- corpus_subset(corp_movies, id_numeric %in% id_train) %>%
dfm(remove = stopwords("english"), stem = TRUE)
# get test set (documents not in id_train)
dfmat_test <- corpus_subset(corp_movies, !id_numeric %in% id_train) %>%
dfm(remove = stopwords("english"), stem = TRUE)
tmod_nb <- textmodel_nb(dfmat_training, dfmat_training$sentiment)
summary(tmod_nb) 回答 1
Stack Overflow用户
回答已采纳
发布于 2020-09-14 15:26:09
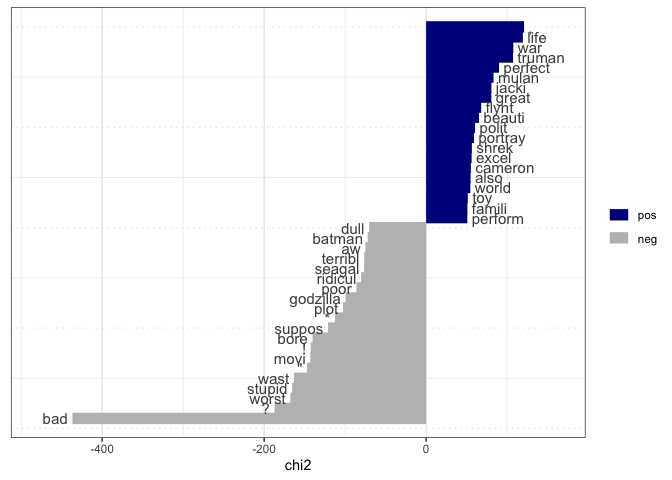
如果你只想知道最消极和最积极的词,可以考虑从整个语料库创建的dfm上的textstat_keyness(),将其划分为正面和负面的评论。这不是创建两个单词向量,而是一个单独的单词向量,其得分表示与负数或正类关联的强度。
library("quanteda", warn.conflicts = FALSE)
## Package version: 2.1.1
## Parallel computing: 2 of 12 threads used.
## See https://quanteda.io for tutorials and examples.
data("data_corpus_moviereviews", package = "quanteda.textmodels")
dfmat <- dfm(data_corpus_moviereviews,
remove = stopwords("english"), stem = TRUE,
groups = "sentiment"
)
tstat <- textstat_keyness(dfmat, target = "pos")
textplot_keyness(tstat)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63845610
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号