
InceptionResnetV2 STEM块角的实现与原论文中的不匹配?
我一直在尝试将来自Keras实现的Keras实现模型摘要与他们的论文中指定的模型摘要进行比较,而当涉及到filter_concat块时,它似乎并没有显示出多少相似之处。
模型summary()的前几行如下所示。(就我的情况而言,输入改为512x512,但据我所知,它不影响每层过滤器的数量,因此我们也可以使用它们来跟踪纸质代码的翻译):
Model: "inception_resnet_v2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 512, 512, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 255, 255, 32) 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 255, 255, 32) 96 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 255, 255, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 253, 253, 32) 9216 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 253, 253, 32) 96 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 253, 253, 32) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 253, 253, 64) 18432 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 253, 253, 64) 192 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 253, 253, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 126, 126, 64) 0 activation_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 126, 126, 80) 5120 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 126, 126, 80) 240 conv2d_4[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 126, 126, 80) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 124, 124, 192 138240 activation_4[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 124, 124, 192 576 conv2d_5[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 124, 124, 192 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 61, 61, 192) 0 activation_5[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 61, 61, 64) 12288 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 61, 61, 64) 192 conv2d_9[0][0]
__________________________________________________________________________________________________
activation_9 (Activation) (None, 61, 61, 64) 0 batch_normalization_9[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 61, 61, 48) 9216 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 61, 61, 96) 55296 activation_9[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 61, 61, 48) 144 conv2d_7[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 61, 61, 96) 288 conv2d_10[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 61, 61, 48) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
activation_10 (Activation) (None, 61, 61, 96) 0 batch_normalization_10[0][0]
__________________________________________________________________________________________________
average_pooling2d_1 (AveragePoo (None, 61, 61, 192) 0 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
.
.
.
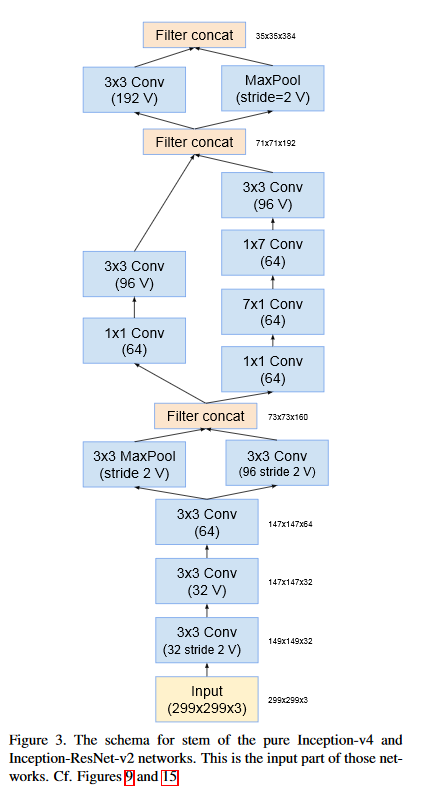
many more lines在他们的论文的图3(下面的图)中,展示了如何为InceptionV4和InceptionResnetV2形成STEM块。在图3中,STEM块中有三个过滤器级联,但在我前面向您展示的输出中,级联似乎是顺序最大池或类似的混合(第一个连接应该出现在max_pooling2d_1之后)。它增加了过滤器的数目,正如级联应该做的那样,但是没有进行连接。过滤器似乎是按顺序放置的!有人知道这个输出是怎么回事吗?它的作用和论文中描述的一样?
作为比较,我找到了一个InceptionV4 keras实现,他们似乎在concatenate_1中为STEM块中的第一个级联做了一个filter_concat。下面是summary()的第一行的输出。
Model: "inception_v4"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 512, 512, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 255, 255, 32) 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 255, 255, 32) 96 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 255, 255, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 253, 253, 32) 9216 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 253, 253, 32) 96 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 253, 253, 32) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 253, 253, 64) 18432 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 253, 253, 64) 192 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 253, 253, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 126, 126, 96) 55296 activation_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 126, 126, 96) 288 conv2d_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 126, 126, 64) 0 activation_3[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 126, 126, 96) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 126, 126, 160 0 max_pooling2d_1[0][0]
activation_4[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 126, 126, 64) 10240 concatenate_1[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 126, 126, 64) 192 conv2d_7[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 126, 126, 64) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 126, 126, 64) 28672 activation_7[0][0]
__________________________________________________________________________________________________
.
.
.
and many more lines因此,正如本文所示,这两种体系结构都应该具有相同的第一层。还是我漏掉了什么?
编辑:编辑--我发现,来自Keras的InceptionResnetV2的实现不是,而是的InceptionResnetV2块,而是的实现(图14来自他们的论文,如下所示)。在STEM块之后,它似乎很好地跟随了InceptionResnetV2的其他块。
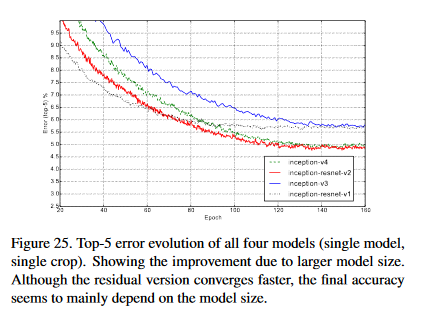
InceptionResnetV1的性能不如InceptionResnetV2 (图25),所以我对使用来自V1的块而不是从keras中的完整V2表示怀疑。我将尝试从我找到的InceptionV4中删除STEM,并将InceptionResnetV2的继续。
同样的问题在tf-模型github没有解释的情况下结束了。如果有人感兴趣,我就把它留在这里:https://github.com/tensorflow/models/issues/1235
编辑2:出于某种原因,GoogleAI (盗梦空间体系结构的创建者)在发布代码时在他们的博客中显示了“Inception RESNET-v2”的图像。但是,STEM块是来自InceptionV3的块,而不是InceptionV4块,正如本文所指定的那样。所以,要么是纸错了,要么是代码由于某种原因没有跟随论文。

回答 1
Stack Overflow用户
发布于 2020-10-26 19:27:03
实现了类似的结果。
我刚收到一封电子邮件,证实了阿莱米的错误,他是谷歌的高级研究科学家,也是关于InceptionResnetV2代码发布的博客文章的原版出版商。似乎在内部实验期间,STEM块被切换,并且释放就像这样。
引用:
丹妮·阿兹马尔 看来你是对的。不完全确定发生了什么,但代码显然是真相的来源,因为发布的检查点是为同样发布的代码提供的。当我们开发架构的时候,我们做了大量的内部实验,我想在某个时候,茎被转换了。我不确定现在是否有时间深入挖掘,但正如我所说,释放的检查点是已发布代码的检查点,因为您可以通过运行评估管道来验证自己。我同意你的观点,似乎这是在使用原始的“盗梦空间”V1干细胞。诚挚的问候, 亚历克斯·阿莱米
我将更新这篇文章中有关这一主题的变化。
UPDATE:Christian Szegedy,也是原版报纸推特的出版商
最初的实验和模型是在DistBelief中创建的,这是一个完全不同的框架,在Tensorflow之前。 信托基金的版本是一年后增加的,可能与原来的模式有出入,但确保取得类似的结果。
因此,由于它取得了类似的结果,你的实验将大致相同。
https://stackoverflow.com/questions/64488034
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号