
OoM: tensorflow模型上Talos优化超参数过程中的内存错误
当我在Talos的帮助下为我的AlexNet寻找最优的超参数时,我的内存错误消失了。它总是发生在同一个时代(32/240),即使我稍微改变了参数(排除原因是一个不利的星座)。
错误消息:
ResourceExhaustedError: OOM when allocating tensor with shape[32,96,26,26] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node max_pooling2d_1/MaxPool (defined at D:\anaconda\envs\tf_ks\lib\site-packages\keras\backend\tensorflow_backend.py:3009) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[Op:__inference_keras_scratch_graph_246047]
Function call stack:
keras_scratch_graph这是我的密码:
会话配置:
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth=True
config.gpu_options.per_process_gpu_memory_fraction = 0.99
sess = tf.compat.v1.Session(config = config)
K.set_session(sess)配置与AlexNet:的拟合
def alexnet(x_train, y_train, x_val, y_val, params):
K.clear_session()
if params['activation'] == 'leakyrelu':
activation_layer = LeakyReLU(alpha = params['leaky_alpha'])
elif params['activation'] == 'relu':
activation_layer = ReLU()
model = Sequential([
Conv2D(filters=96, kernel_size=(11,11), strides=(4,4), activation='relu', input_shape=(224,224,Global.num_image_channels)),
BatchNormalization(),
MaxPooling2D(pool_size=(3,3), strides=(2,2)),
Conv2D(filters=256, kernel_size=(5,5), strides=(1,1), activation='relu', padding="same"),
BatchNormalization(),
MaxPooling2D(pool_size=(3,3), strides=(2,2)),
Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), activation='relu', padding="same"),
BatchNormalization(),
Conv2D(filters=384, kernel_size=(1,1), strides=(1,1), activation='relu', padding="same"),
BatchNormalization(),
Conv2D(filters=256, kernel_size=(1,1), strides=(1,1), activation='relu', padding="same"),
BatchNormalization(),
MaxPooling2D(pool_size=(3,3), strides=(2,2)),
Flatten(),
Dense(4096, activation=activation_layer),
Dropout(0.5),#todo
Dense(4096, activation=activation_layer),
Dropout(0.5),#todo
Dense(units = 2, activation=activation_layer)
#Dense(10, activation='softmax')
])
model.compile(
optimizer = params['optimizer'](lr = lr_normalizer(params['lr'], params['optimizer'])),
loss = Global.loss_funktion,
metrics = get_reduction_metric(Global.reduction_metric)
)
train_generator, valid_generator = create_data_pipline(params['batch_size'], params['samples'])
tg_steps_per_epoch = train_generator.n // train_generator.batch_size
vg_validation_steps = valid_generator.n // valid_generator.batch_size
print('Steps per Epoch: {}, Validation Steps: {}'.format(tg_steps_per_epoch, vg_validation_steps))
startTime = datetime.now()
out = model.fit(
x = train_generator,
epochs = params['epochs'],
validation_data = valid_generator,
steps_per_epoch = tg_steps_per_epoch,
validation_steps = vg_validation_steps,
#callbacks = [checkpointer]
workers = 8
)
print("Time taken:", datetime.now() - startTime)
return out, model超参数列表:
hyper_parameter = {
'samples': [20000],
'epochs': [1],
'batch_size': [32, 64],
'optimizer': [Adam],
'lr': [1, 2],
'first_neuron': [1024, 2048, 4096],
'dropout': [0.25, 0.50],
'activation': ['leakyrelu', 'relu'],
'hidden_layers': [0, 1, 2, 3, 4],
'leaky_alpha': [0.1] #Default bei LeakyReLU, sonst PReLU
}Run Talos:
dummy_x = np.empty((1, 2, 3, 224, 224))
dummy_y = np.empty((1, 2))
with tf.device('/device:GPU:0'):
t = ta.Scan(
x = dummy_x,
y = dummy_y,
model = alexnet,
params = hyper_parameter,
experiment_name = '{}'.format(Global.dataset),
#shuffle=False,
reduction_metric = Global.reduction_metric,
disable_progress_bar = False,
print_params = True,
clear_session = 'tf',
save_weights = False
)
t.data.to_csv(Global.target_dir + Global.results, index = True)内存的使用率总是很高,但不会超过时代,但变化不大。
Nvidia SMI输出:
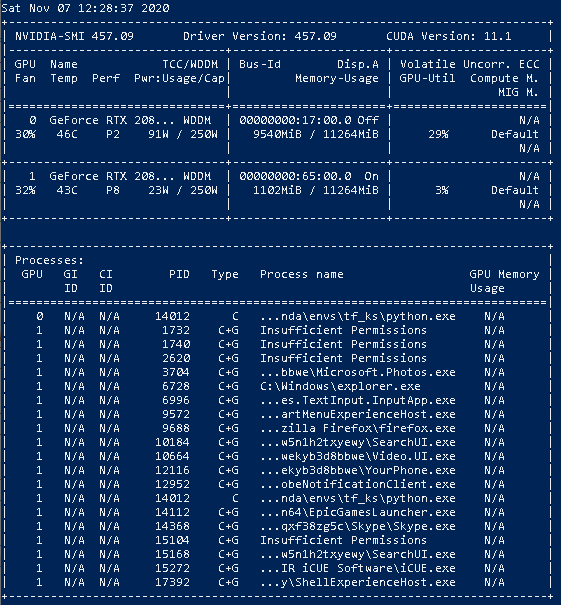
有人能帮帮我吗?
我已经尝试过的东西:========================================================================== :
1)拆分Talos运行:
这导致了同样的错误。
hyper_parameter = {
'samples': [20000],
'epochs': [1],
'batch_size': [32, 64],
'optimizer': [Adam],
'lr': [1, 2, 3, 5],
'first_neuron': [9999],
'dropout': [0.25, 0.50],
'activation': ['leakyrelu', 'relu'],
'hidden_layers': [9999],
'leaky_alpha': [0.1] #Default bei LeakyReLU, sonst PReLU
}
dummy_x = np.empty((1, 2, 3, 224, 224))
dummy_y = np.empty((1, 2))
first = True
for h in [0, 1, 2, 3, 4]:
hyper_parameter['hidden_layers']=[h]
for fn in [1024, 2048, 4096]:
hyper_parameter['first_neuron']=[fn]
with tf.device('/device:GPU:1'):
t = ta.Scan(
x = dummy_x,
y = dummy_y,
model = alexnet,
params = hyper_parameter,
experiment_name = '{}'.format(Global.dataset),
#shuffle=False,
reduction_metric = Global.reduction_metric,
disable_progress_bar = False,
print_params = True,
clear_session = 'tf',
save_weights = False
)
if(first):
t.data.to_csv(Global.target_dir + Global.results, index = True, mode='a')
first = False
else:
t.data.to_csv(Global.target_dir + Global.results, index = True, mode='a', header=False)==========================================================================
2)在自己的线程中运行模型
寻找原因时,我发现有些人抱怨同样的问题,并指责TensorFlow没有执行K.clear_session()。
也许这个想法是愚蠢的,但是我试着用一个额外的线来训练模型。
from threading import Thread
def gen_model_thread(x_train, y_train, x_val, y_val, params):
thread = Thread(target=alexnet, args=(x_train, y_train, x_val, y_val, params))
thread.start()
return_value = thread.join()
return return_valuewith tf.device('/device:GPU:0'):
t = ta.Scan(
x = dummy_x,
y = dummy_y,
model = gen_model_thread,
params = hyper_parameter,
experiment_name = '{}'.format(Global.dataset),
#shuffle=False,
reduction_metric = Global.reduction_metric,
disable_progress_bar = False,
print_params = True,
clear_session = True,
save_weights = False
)这导致类型错误:
Traceback (most recent call last):
File "D:\anaconda\envs\tf_ks\lib\threading.py", line 926, in _bootstrap_inner
self.run()
File "D:\anaconda\envs\tf_ks\lib\threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "<ipython-input-3-2942ae0a0a56>", line 5, in gen_model
model = alexnet(params['activation'], params['leaky_alpha'])
File "<ipython-input-2-2a405202aa5a>", line 27, in alexnet
Dense(units = 2, activation=activation_layer)
File "D:\anaconda\envs\tf_ks\lib\site-packages\keras\engine\sequential.py", line 94, in __init__
self.add(layer)
File "D:\anaconda\envs\tf_ks\lib\site-packages\keras\engine\sequential.py", line 162, in add
name=layer.name + '_input')
File "D:\anaconda\envs\tf_ks\lib\site-packages\keras\engine\input_layer.py", line 178, in Input
input_tensor=tensor)
File "D:\anaconda\envs\tf_ks\lib\site-packages\keras\legacy\interfaces.py", line 91, in wrapper
return func(*args, **kwargs)
File "D:\anaconda\envs\tf_ks\lib\site-packages\keras\engine\input_layer.py", line 87, in __init__
name=self.name)
File "D:\anaconda\envs\tf_ks\lib\site-packages\keras\backend\tensorflow_backend.py", line 73, in symbolic_fn_wrapper
if _SYMBOLIC_SCOPE.value:
AttributeError: '_thread._local' object has no attribute 'value'
TypeError: cannot unpack non-iterable NoneType object我知道,我最后的机会是手动做,但我想我会走向同样的问题,同时训练我的模式,无论如何。
非常感谢你解决了我的问题,阅读了我的问题,纠正了我课文中的拼写错误。
我期待着从这个令人惊叹的社区得到建设性的解决方案!
==========================================================================
GPU: NVIDIA RTX 2080 RTX和泰坦Xp收集器版(我都试过了)
TensorFlow: 2.1.0
Keras: 2.3.1
塔罗斯: 1.0
回答 1
Stack Overflow用户
发布于 2021-02-01 11:46:35
禁用急切的执行解决了我的问题: tf.compat.v1.disable_eager_execution()
https://stackoverflow.com/questions/64744483
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号