
自然三次样条的patsy cr
我正在尝试使用patsy库来制作自然三次样条。这是我的代码:
import numpy as np
from sklearn.linear_model import LinearRegression
from patsy import cr
import matplotlib.pyplot as plt
x = df.age #some data
y = df.wage
x_basis = cr(x, df=15)
model = LinearRegression().fit(x_basis, y)
y_hat = model.predict(x_basis)
plt.scatter(x, y)
plt.plot(x, y_hat, 'r')
plt.show()输出如下:
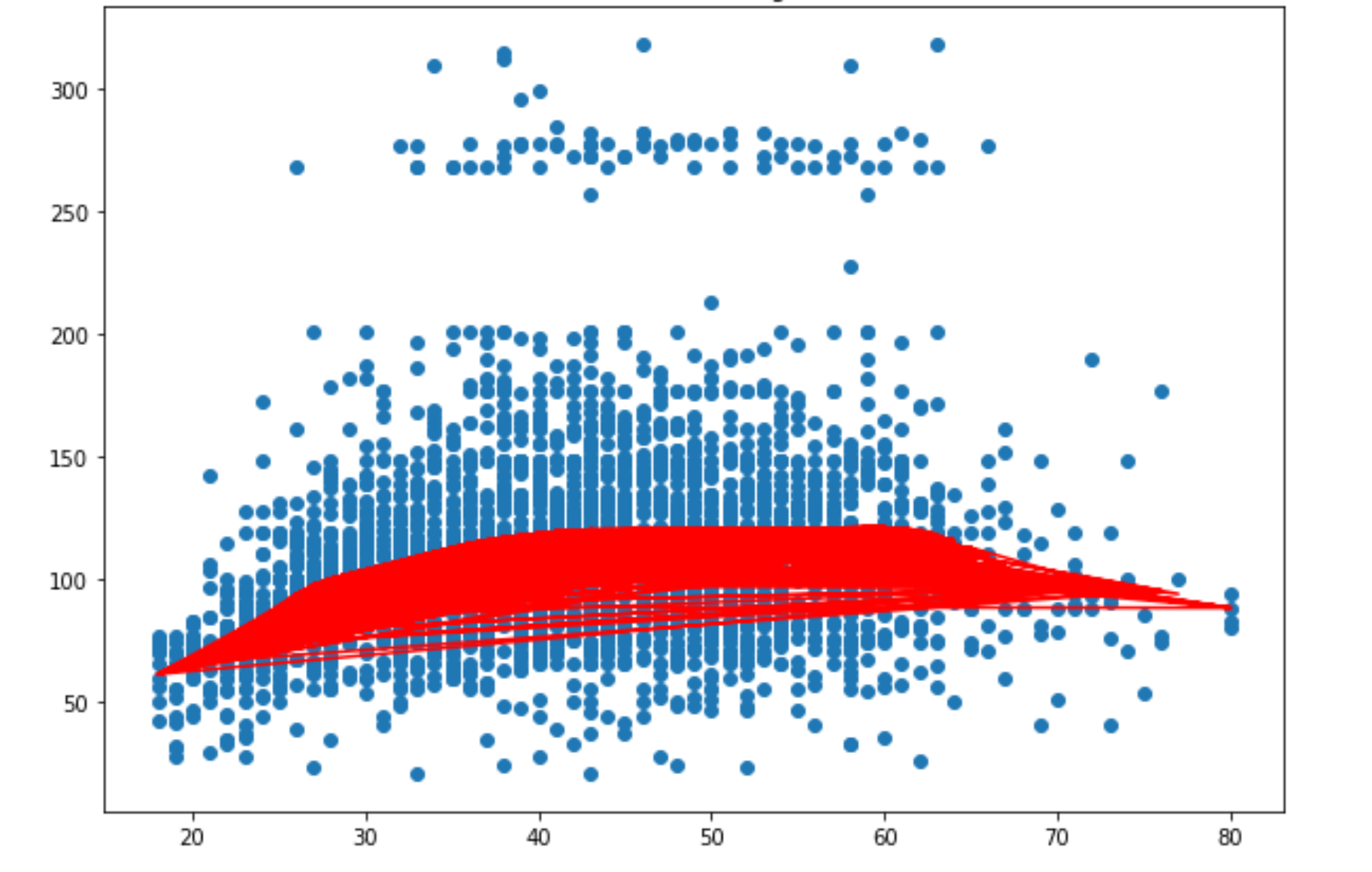
我认为应该有一条线。我怎样才能解决这个问题?
回答 2
Stack Overflow用户
发布于 2020-11-15 23:41:16
这只是个密谋问题。默认情况下,plt.plot函数会绘制没有标记的线条图。由于您的数据不是按照x变量排序的,所以行来回跳,结果看起来很混乱。我生成了示例数据,并用plt.plot默认值绘制了图,然后隐藏了行,并添加了标记。结果是
使用默认的plt.plot参数
以下代码的其余部分(为方便起见不重复)
spline_basis = patsy.cr(x, df=3)
model = LinearRegression().fit(spline_basis, y)
y_spline = model.predict(spline_basis)
plt.scatter(x, y)
plt.plot(x, y_spline, color="red")
plt.show()
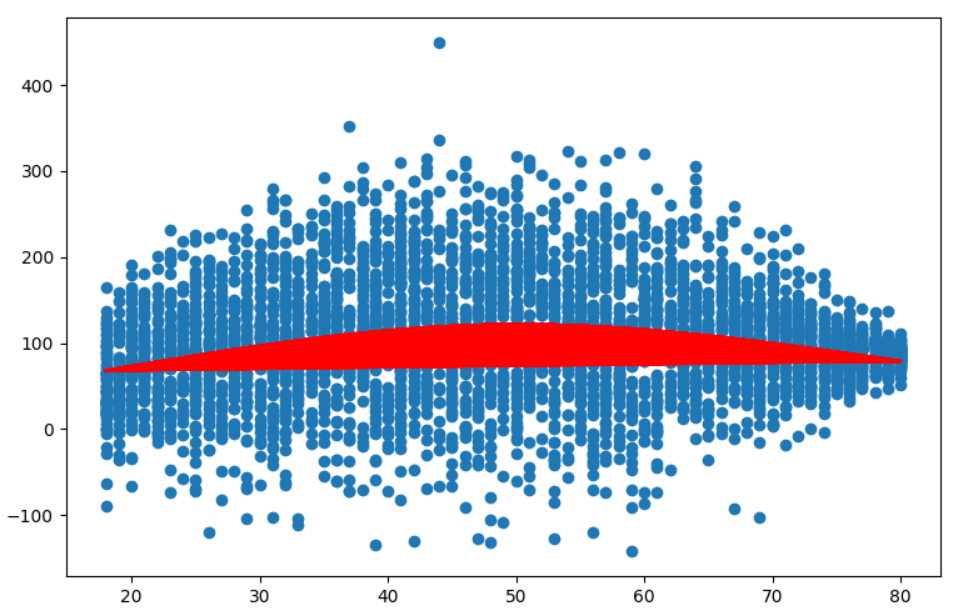
使用plt.plot时marker='.'和ls=''
以下代码的其余部分(为方便起见不重复)
spline_basis = patsy.cr(x, df=3)
model = LinearRegression().fit(spline_basis, y)
y_spline = model.predict(spline_basis)
plt.scatter(x, y)
plt.plot(x, y_spline, ls="", marker=".", color="red") # Only this changed
plt.show()
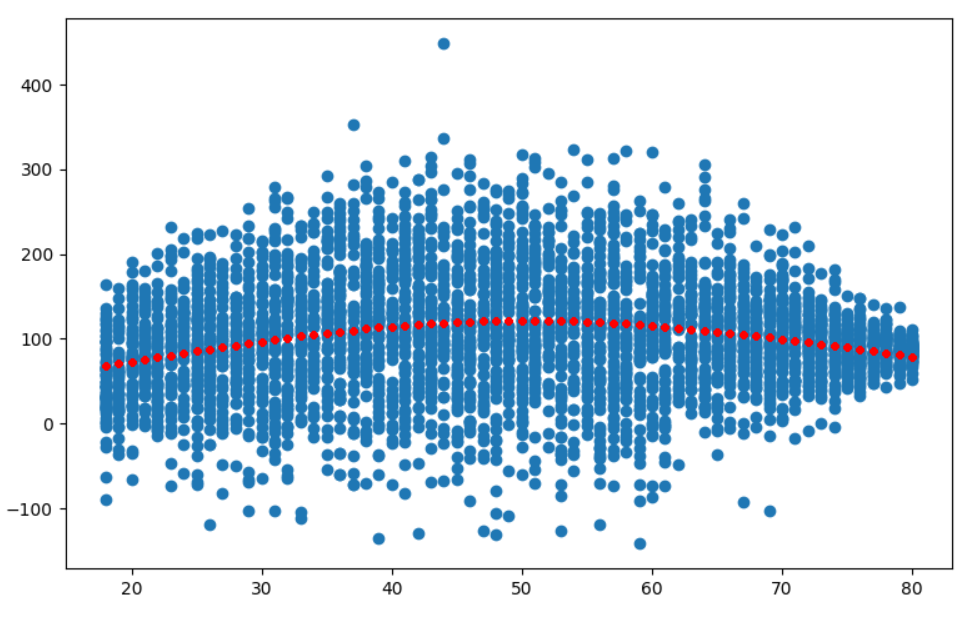
通过重新排序数据
以下代码的其余部分(为方便起见不重复)
如果您想绘制一幅线图,您可以重新排序数据以进行拟合,如下所示:
spline_basis = patsy.cr(x, df=3)
model = LinearRegression().fit(spline_basis, y)
y_spline = model.predict(spline_basis)
plt.scatter(x, y)
xsorted, ysorted = zip(*[(X, Y) for (X, Y) in sorted(zip(x, y_spline))]) # simple reordering
plt.plot(xsorted, ysorted, color="red")
plt.show()
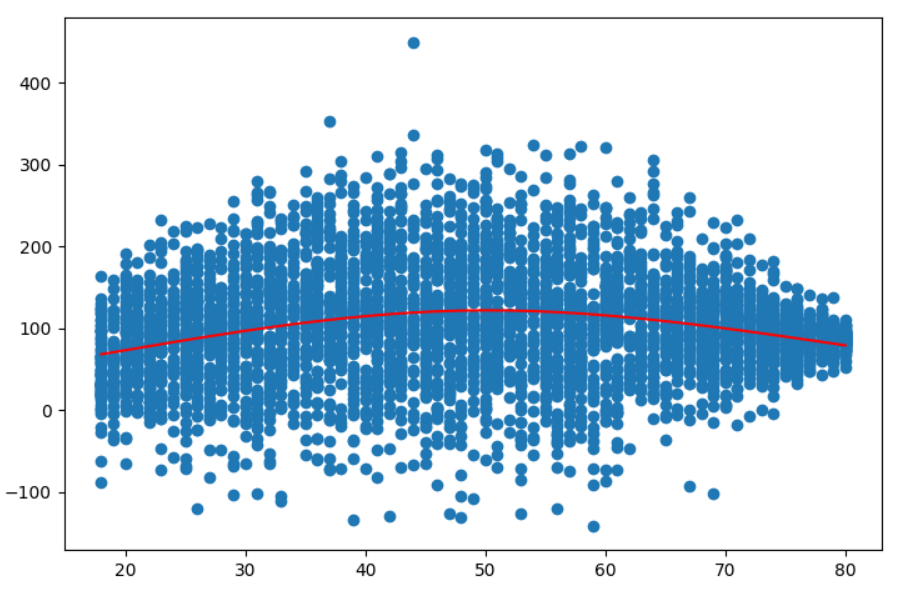
使用新的数据进行预测
通常,模型是为预测而创建的。其思想是使用训练数据创建模型,然后与一些新数据一起使用该模型。这些新的数据可以是任何东西。如果对其进行排序,则可以将其绘制为线条图。在这种情况下,您可以创建新的x-值,例如
new_x = np.linspace(10, 100, 100)并计算它们的预测y值。为此,您只需要知道(并保存)很少的值。实际上,只有df,lower_bound,upper_bound和来自model._coef的4个浮标。
# Fit model
spline_basis = patsy.cr(x, df=3, lower_bound=x.min(), upper_bound=x.max())
model = LinearRegression().fit(spline_basis, y)
y_train = model.predict(spline_basis)
# Use model
new_x = np.linspace(10, 100, 100) # 100 points
spline_basis_new = patsy.cr(new_x, df=3, lower_bound=x.min(), upper_bound=x.max())
new_y = model.predict(spline_basis_new)
plt.scatter(x, y)
plt.plot(x, y_train, color="red", ls="", marker=".")
plt.plot(new_x, new_y, color="green")
plt.show()
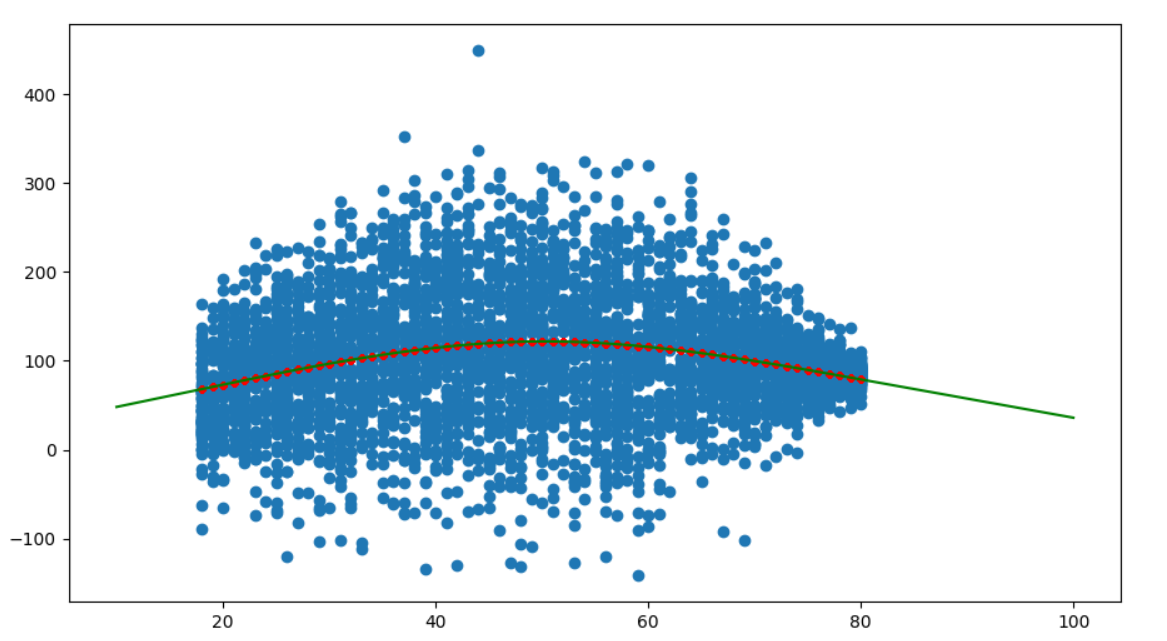
其余代码
from matplotlib import pyplot as plt
import numpy as np
import patsy
from sklearn.linear_model import LinearRegression
def dummy_data():
np.random.seed(1)
x = np.random.choice(np.arange(18, 81), size=4000)
def model(x):
a = 83 / 107520
b = -895 / 5376
c = 17747 / 1680
d = -622 / 7
return a * x ** 3 + b * x ** 2 + c * x + d
def noisemodel(x):
an = -0.0591836734693878
bn = 5.25510204081633
cn = -31.6326530612245
return an * x ** 2 + bn * x + cn
y = model(x)
ynoise = np.array([np.random.randn() * noisemodel(_) for _ in x])
return x, y + ynoise
x, y = dummy_data()Stack Overflow用户
发布于 2020-11-15 12:20:22
兄弟,在传递给一个模糊函数之前,对你的值进行排序。
DSBA广场教师助理小组
https://stackoverflow.com/questions/64821775
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号