
具有多个预测器的多后勤回归代码的问题
我试图对一些变量进行多重逻辑回归,这些变量在单因素分析的疾病条件下具有统计学意义。因为我们的样本尺寸是300左右,所以我们把它作为p<0.2。我为这些变量做了一个新的数据
regression1df <- data.frame(dgfcriteria, recipientage, ESRD_dx,bmirange,graftnumber, dsa_class_1, organ_tx, transfuse01m, transfuse1yr, readmission1yr, citrange1, switrange, anastamosisrange, donorage, donorgender, donorcriteria, donorionotrope, intubaterange, kdpirange, kdrirange, eptsrange, proteinuria, terminalurea, na.rm=TRUE)我使用变量来预测疾病状况,即DGF (dgfcriteria==1),而非疾病则不是DGF (dgfcriteria==0).
这是数据的结构。

当我试图使用glm代码运行整个变量列表时:
predictors1 <- glm(dgfcriteria ~.,
data = predictors1df,
family = "binomial" )contrasts<-中的错误(*tmp*,value = contr.funs[1 + isOFnn]):对比只能应用于2级或2级以上的因素。
但是,当我只使用dataframe的一些变量运行它时,就会有一个输出。
predictors1 <- glm(dgfcriteria ~ recipientage + ESRD_dx + bmirange + graftnumber + dsa_class_1 + organ_tx + transfuse01m + transfuse1yr + readmission1yr +citrange1 +switrange + anastamosisrange+ donorage+ donorgender + donorcriteria + donorionotrope,
data = predictors1df,
family = "binomial" )这个输出看起来很奇怪,尽管有很多NAs。
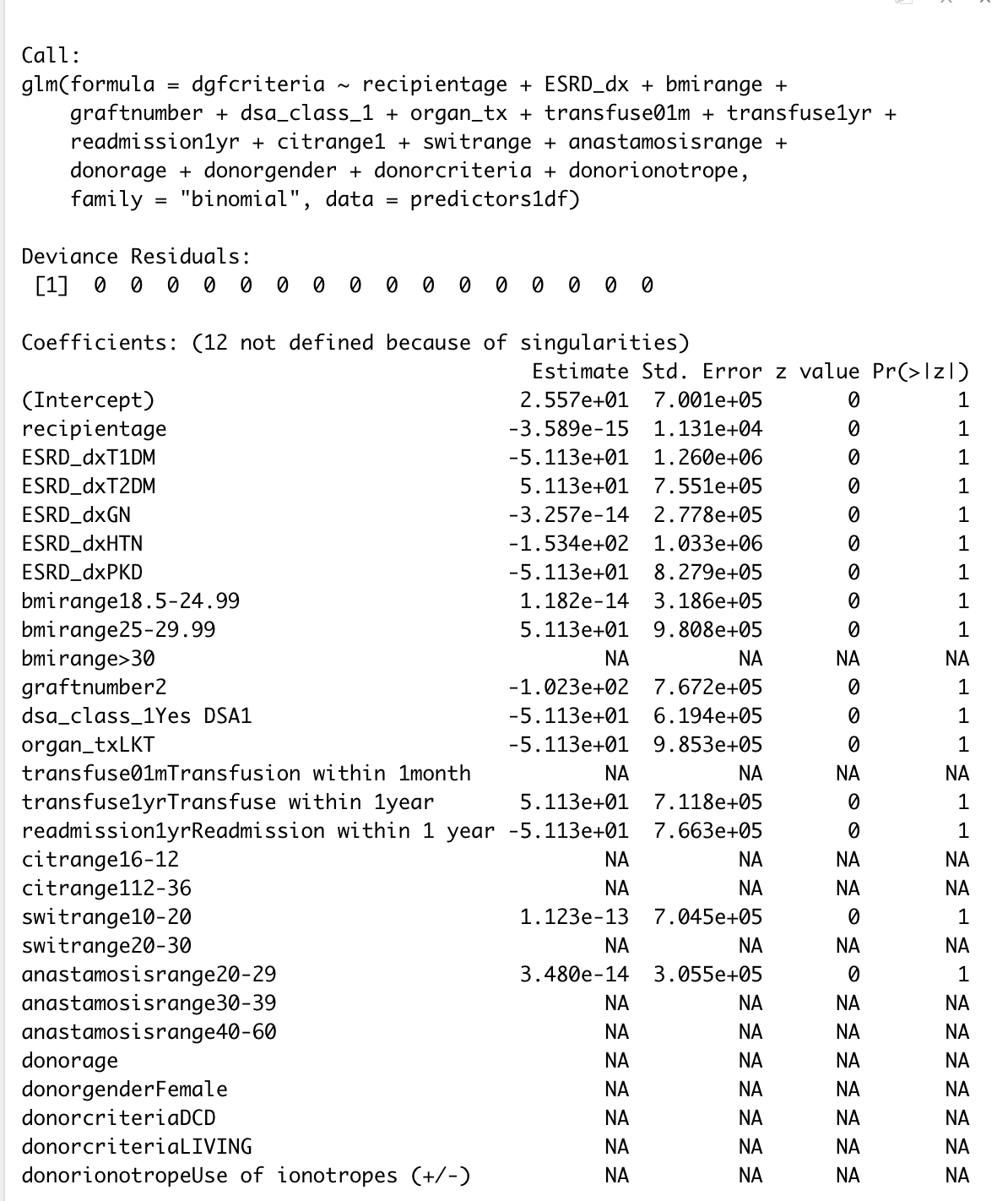
我哪里出错了?
回答 1
Stack Overflow用户
发布于 2020-11-14 04:18:58
从您的数据结构来看,您有很多缺失的值。在前10行中,相当多的变量看起来只有2或3个不缺失的值。当您对缺少值的数据运行回归时,默认情况是删除所有缺少值的行。
显然,有些数据存在严重的重叠,因此当删除所有缺少值的行时(剩下的内容请参见na.omit(your_data) ),一些变量只剩下一个级别,因此不再适合回归。当然,当您只使用一些变量时,将会删除较少的行,并且您的情况可能会更好。
因此,您必须决定如何处理丢失的值。这取决于你的目标和你对失败原因的理解。常见的可能性包括遗漏、归咎、创建新的“缺失”级别,以及在变量选择中考虑到缺失程度。
https://stackoverflow.com/questions/64830715
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号