
如何在Keras中生成比训练大小更多的增强图像?
如何在Keras中生成比训练大小更多的增强图像?
提问于 2021-01-02 22:16:20
我知道图像的数据增强技术。然而,我对如何生成增强的数据有疑问。
我将使用Keras和Tensorflow共享我的场景和代码,但是对于任何库,这个概念都是相同的。
以下场景的图像增强技术:
随机Rotation
- Random
在Keras中,我们使用ImageDataGenerator来增强图像,而数据被提取用于训练。例如,如果我们有100张图片要开始。然后,ImageDataGenerator将在这些图像上应用上述提到的转换,并在每个时期输出100图像(默认ImageDataGenerator)。
但是,如果我们实现我们自己的ImageDataGenerator,我们也可以实现它来返回100 + 2*100 =300个图像进行培训。
上面提到的场景中哪一种总体上是好的?
回答 1
Stack Overflow用户
发布于 2021-01-02 22:29:29
如果您使用相同的100张图片,并在三个时期内进行增强,您将得到300张独特的图片。每次加载图片时,Keras都会应用随机转换。
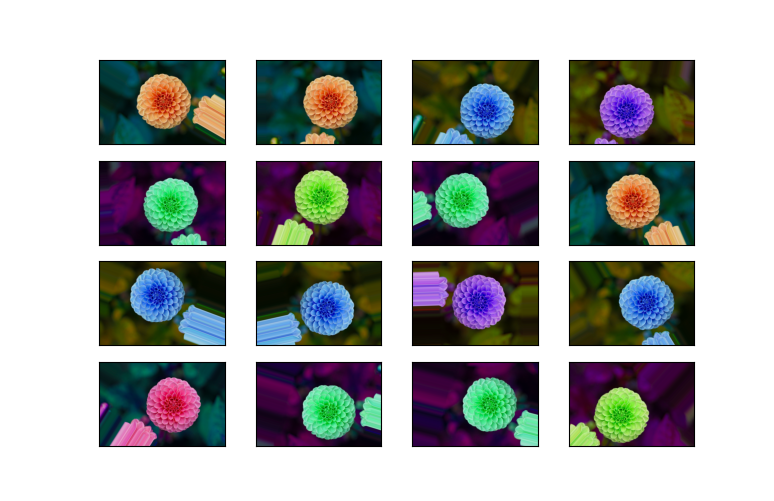
看下面。这是一个图像数据集的16次重复。相同的图像从未以同样的方式被转换。
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
import numpy as np
imgs = np.stack([load_sample_image('flower.jpg') for i in range(4*4)], axis=0)
data_gen = tf.keras.preprocessing.image.ImageDataGenerator(
rotation_range = 90,
width_shift_range = 0.1,
height_shift_range = 0.1,
horizontal_flip = True,
preprocessing_function=lambda x: x[..., np.random.permutation([0, 1, 2])]
)
fig = plt.figure(figsize=(4, 4))
for index, image in enumerate(next(data_gen.flow(imgs)).astype(int)):
ax = plt.subplot(4, 4, index + 1)
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(image)
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65544658
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号