
如何利用MCMC分解混合分布
我的数据是正态分布和恒定值的50:50混合:
numdata = 10000
data = np.random.normal(0.0,1.0,numdata).astype(np.float32)
data[int(numdata/2):] = 0.0
plt.hist(data,30,density=True)
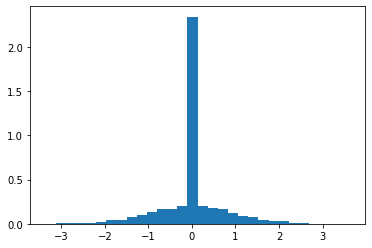
我的任务是将混合密度与这些数据相匹配。我使用的是tfd.Mixture和tfd.Normal和tfd.Deterministic,已知的(在样本数据情况下)正常与确定性的比率是0.5,我的MCMC则返回一个0.83的比率,以支持正常值。
是否有更好的方法使这一分布符合正确的比率?
以下是完整的示例代码:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
import tensorflow as tf
import tensorflow_probability as tfp
import matplotlib.pyplot as plt
tfd = tfp.distributions
tfb = tfp.bijectors
import numpy as np
from time import time
numdata = 10000
data = np.random.normal(0.0,1.0,numdata).astype(np.float32)
data[int(numdata/2):] = 0.0
_=plt.hist(data,30,density=True)
root = tfd.JointDistributionCoroutine.Root
def dist_fn(rv_p,rv_mu):
rv_cat = tfd.Categorical(probs=tf.stack([rv_p, 1.-rv_p],-1))
rv_norm = tfd.Normal(rv_mu,1.0)
rv_zero = tfd.Deterministic(tf.zeros_like(rv_mu))
rv_mix = tfd.Independent(
tfd.Mixture(cat=rv_cat,
components=[rv_norm,rv_zero]),
reinterpreted_batch_ndims=1)
return rv_mix
def model_fn():
rv_p = yield root(tfd.Sample(tfd.Uniform(0.0,1.0),1))
rv_mu = yield root(tfd.Sample(tfd.Uniform(-1.,1. ),1))
rv_mix = yield dist_fn(rv_p,rv_mu)
jd = tfd.JointDistributionCoroutine(model_fn)
unnormalized_posterior_log_prob = lambda *args: jd.log_prob(args + (data,))
n_chains = 1
p_init = [0.3]
p_init = tf.cast(p_init,dtype=tf.float32)
mu_init = 0.1
mu_init = tf.stack([mu_init]*n_chains,axis=0)
initial_chain_state = [
p_init,
mu_init,
]
bijectors = [
tfb.Sigmoid(), # p
tfb.Identity(), # mu
]
step_size = 0.01
num_results = 50000
num_burnin_steps = 50000
kernel=tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unnormalized_posterior_log_prob,
num_leapfrog_steps=2,
step_size=step_size,
state_gradients_are_stopped=True),
bijector=bijectors)
kernel = tfp.mcmc.SimpleStepSizeAdaptation(
inner_kernel=kernel, num_adaptation_steps=int(num_burnin_steps * 0.8))
#XLA optim
@tf.function(autograph=False, experimental_compile=True)
def graph_sample_chain(*args, **kwargs):
return tfp.mcmc.sample_chain(*args, **kwargs)
st = time()
trace,stats = graph_sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_chain_state,
kernel=kernel)
et = time()
print(et-st)
ptrace, mutrace = trace
plt.subplot(121)
_=plt.hist(ptrace.numpy(),100,density=True)
plt.subplot(122)
_=plt.hist(mutrace.numpy(),100,density=True)
print(np.mean(ptrace),np.mean(mutrace))P和mu的结果分布如下:
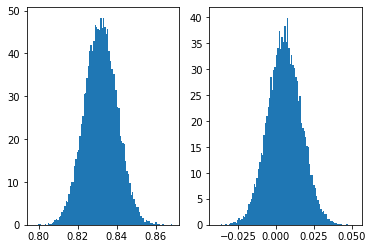
显然,它的平均值应该是0.5,我怀疑model_fn()可能有问题。我试着在不同的p值下评估模型的log_prob,实际上,“最优”在0.83左右,我只是不明白为什么以及如何修复它,以便重建原始混合物。
用pymc3编辑一个“简单”的演示代码。同样的行为,结果是0.83而不是0.5
import pymc3 as pm
import numpy as np
import arviz as az
import matplotlib.pyplot as plt
numdata = 1000
data1 = np.random.normal(0.0,1.0,numdata).astype(np.float32)
data2 = np.zeros(numdata).astype(np.float32)
data = np.concatenate((data1,data2))
_=plt.hist(data,30,density=True)
with pm.Model() as model:
norm = pm.Normal.dist(0.0,1.0)
zero = pm.Constant.dist(0.0)
components = [norm,zero]
w = pm.Dirichlet('p', a=np.array([1, 1])) # two mixture component weights.
like = pm.Mixture('data', w=w, comp_dists=components, observed=data)
posterior = pm.sample()
idata = az.from_pymc3(posterior)
az.plot_posterior(posterior)回答 1
Stack Overflow用户
发布于 2021-03-06 06:10:41
概率密度和质量的不可通约性
这里的问题是,来自每个模型的可能性涉及到高斯的概率密度和离散的质量,这是不相称的。具体来说,比较零观测来自何处的计算将涉及到可能性。
P[x=0|Normal[0,1]] = 1/sqrt(2*pi) = 0.3989422804014327
P[x=0| Zero ] = 1它将比较这些(按p加权),好像它们有相同的单位。然而,前者是相对于后者的密度,因此是无穷小的。如果忽略了这种不可通约性,那么实际上就好像高斯有40%的机会生成零,而在现实中,几乎从来没有却产生了一个零。
解决办法:伪离散分布
我们需要以某种方式改造这些单位。一个简单的方法是用一个连续的分布来近似离散分布,这样它产生的可能性就在密度单位中。例如,使用以离散值为中心的高精度(窄)高斯或拉普拉斯分布,在p上产生一个以0.5为中心的后验分布:
with pm.Model() as model:
norm = pm.Normal.dist(0.0, 1.0)
pseudo_zero = pm.Laplace.dist(0.0, 1e-16)
components = [norm, pseudo_zero]
w = pm.Dirichlet('p', a=np.array([1, 1])) # two mixture component weights.
like = pm.Mixture('data', w=w, comp_dists=components, observed=data)
posterior = pm.sample()
idata = az.from_pymc3(posterior)
az.plot_posterior(posterior)
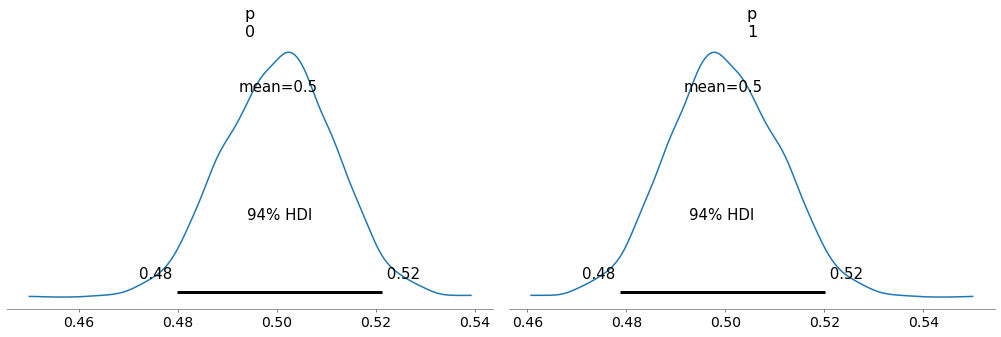
为什么p=0.83
我们观察到的离散和连续混合时的后验不是任意的。这里有几种方法可以得到它。对于下面的内容,我们只使用一个p来表示来自高斯的概率。
地图估计
忽略不可通约性,我们可以导出p的地图估计如下。让我们用D = { D_1 | D_2 }表示组合的观测值,其中D_1是高斯的子集,n是每个子集的观测数。然后我们就可以写出可能性
P[p|D] ~ P[D|p]P[p]由于Dirichlet是统一的,我们可以忽略P[p]并扩展数据。
P[D|p] = P[D_1|p]P[D_2|p]
= (Normal[D_1|0,1]*(p^n))(Normal[0|0,1]*p + 1*(1-p))^n
= Normal[D_1|0,1]*(p^n)(0.3989*p + 1 - p)^n
= Normal[D_1|0,1]*(p - 0.6011*(p^2))^n取导数w.r.t.p和设置为零
0 = n*(1-1.2021*p)(p-0.6011*p^2)^(n-1)它在p = 1/1.2021 = 0.8318669上取一个(非平凡的)零。
抽样思维实验
另一种方法是通过一个抽样实验来实现这一目标。假设我们使用了下面的方案来示例p。
- 从给定的
p开始。 - 对于每个观察结果,使用两个模型的可能性绘制一个Bernoulli样本,并按前面的
p值加权。 - 计算一个新的
p作为所有伯努利画的平均值。 - 去第一步。
本质上,吉布斯采样器用于p,但对不可能的观察-模型分配稳健.
对于第一个迭代,让我们从p=0.5开始。对于所有真正来自高斯的观测结果,它们对离散模型的概率为零,因此,至少,我们的Bernoulli绘制的一半将是1(对于高斯)。对于来自离散模型的所有观测,这将是对每个模型中观察到零的可能性的比较。离散模型为1,高斯为0.3989422804014327。规范这一点,意味着伯努利的平局概率为
p*0.3989/((1-p)*1 + p*0.3989)
# 0.2851742248343187支持高斯。现在我们可以更新p了,这里我们只需要使用预期的值,即:
p = 0.5*1 + 0.5*0.2851742248343187
# 0.6425871124171594如果我们开始迭代这个会发生什么呢?
# likelihood for zero from normal
lnorm = np.exp(pm.Normal.dist(0,1).logp(0).eval())
# history
p_n = np.zeros(101)
# initial value
p_n[0] = 0.5
for i in range(100):
# update
p_n[1+i] = 0.5 + 0.5*p_n[i]*lnorm/((1-p_n[i])+p_n[i]*lnorm)
plt.plot(p_n);
p_n[100]
# 0.8318668635076404

同样,期望值收敛到我们的p = 0.83后验均值。
因此,抛开PDF和PMFs对其共域有不同的单位这一事实,TFP和PyMC3的行为似乎都是正确的。
https://stackoverflow.com/questions/66407576
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号