
用VowpalWabbit优化CTR (点击率):如何选择合适的参数?
我试图通过VowpalWabbit优化某些文章或广告(动作)的点击率,给出一个设备类型(上下文)(在本文大众教程之后)。然而,我无法使它可靠地收敛到最优动作。
我创建了一个最小的工作示例(对不起长度):
import random
import numpy as np
from matplotlib import pyplot as plt
from vowpalwabbit import pyvw
plt.ion()
action_space = ["article-1", "article-2", "article-3"]
def running_mean(x, N):
cumsum = np.cumsum(np.insert(x, 0, 0))
return (cumsum[N:] - cumsum[:-N]) / float(N)
def to_vw_example_format(context, cb_label=None):
if cb_label is not None:
chosen_action, cost, prob = cb_label
example_string = ""
example_string += "shared |User device={} \n".format(context)
for action in action_space:
if cb_label is not None and action == chosen_action:
example_string += "1:{}:{} ".format(cost, prob)
example_string += "|Action ad={} \n".format(action)
# Strip the last newline
return example_string[:-1]
# definition of problem to solve, playing out the article with highest ctr given a context
context_to_action_ctr = {
"device-1": {"article-1": 0.05, "article-2": 0.06, "article-3": 0.04},
"device-2": {"article-1": 0.08, "article-2": 0.07, "article-3": 0.05},
"device-3": {"article-1": 0.01, "article-2": 0.04, "article-3": 0.09},
"device-4": {"article-1": 0.04, "article-2": 0.04, "article-3": 0.045},
"device-5": {"article-1": 0.09, "article-2": 0.01, "article-3": 0.07},
"device-6": {"article-1": 0.03, "article-2": 0.09, "article-3": 0.04}
}
#vw = f"--cb_explore 3 -q UA -q UU --epsilon 0.1"
vw = f"--cb_explore_adf -q UA -q UU --bag 5 "
#vw = f"--cb_explore_adf -q UA --epsilon 0.2"
actor = pyvw.vw(vw)
random_rewards = []
actor_rewards = []
optimal_rewards = []
for step in range(200000):
# pick a random context
device = random.choice(list(context_to_action_ctr.keys()))
# let vw generate probability distribution
# action_probabilities = np.array(actor.predict(f"|x device:{device}"))
action_probabilities = np.array(actor.predict(to_vw_example_format(device)))
# sample action
probabilities = action_probabilities / action_probabilities.sum()
action_idx = np.random.choice(len(probabilities), 1, p=probabilities)[0]
probability = action_probabilities[action_idx]
# get reward/regret
action_to_reward_regret = {
action: (1, 0) if random.random() < context_to_action_ctr[device][action] else (0, 1) for action in action_space
}
actor_action = action_space[action_idx]
random_action = random.choice(action_space)
optimal_action = {
"device-1": "article-2",
"device-2": "article-1",
"device-3": "article-3",
"device-4": "article-3",
"device-5": "article-1",
"device-6": "article-2",
}[device]
# update statistics
actor_rewards.append(action_to_reward_regret[actor_action][0])
random_rewards.append(action_to_reward_regret[random_action][0])
optimal_rewards.append(action_to_reward_regret[optimal_action][0])
# learn online
reward, regret = action_to_reward_regret[actor_action]
cost = -1 if reward == 1 else 0
# actor.learn(f"{action_idx+1}:{cost}:{probability} |x device:{device}")
actor.learn(to_vw_example_format(device, (actor_action, cost, probability)))
if step % 100 == 0 and step > 1000:
plt.clf()
axes = plt.gca()
plt.title("Reward over time")
plt.plot(running_mean(actor_rewards, 10000), label=str(vw))
plt.plot(running_mean(random_rewards, 10000), label="Random actions")
plt.plot(running_mean(optimal_rewards, 10000), label="Optimal actions")
plt.legend()
plt.pause(0.0001)实质上,有三种可能的行动(第1-3条)和6种情况(装置1-6),每种组合都有一定的CTR (点击率)和给定上下文的最佳行动(在给定装置时ctr最高的条款)。每次迭代时,随机抽取上下文,计算每个动作的回报/后悔。如果奖励为1(用户单击),则VowpalWabbit用于学习的成本为-1,如果奖励为0,则为0(用户没有单击)。随着时间的推移,该算法被认为是为每个设备找到最好的文章。
一些结果(随着时间的推移平均奖励):
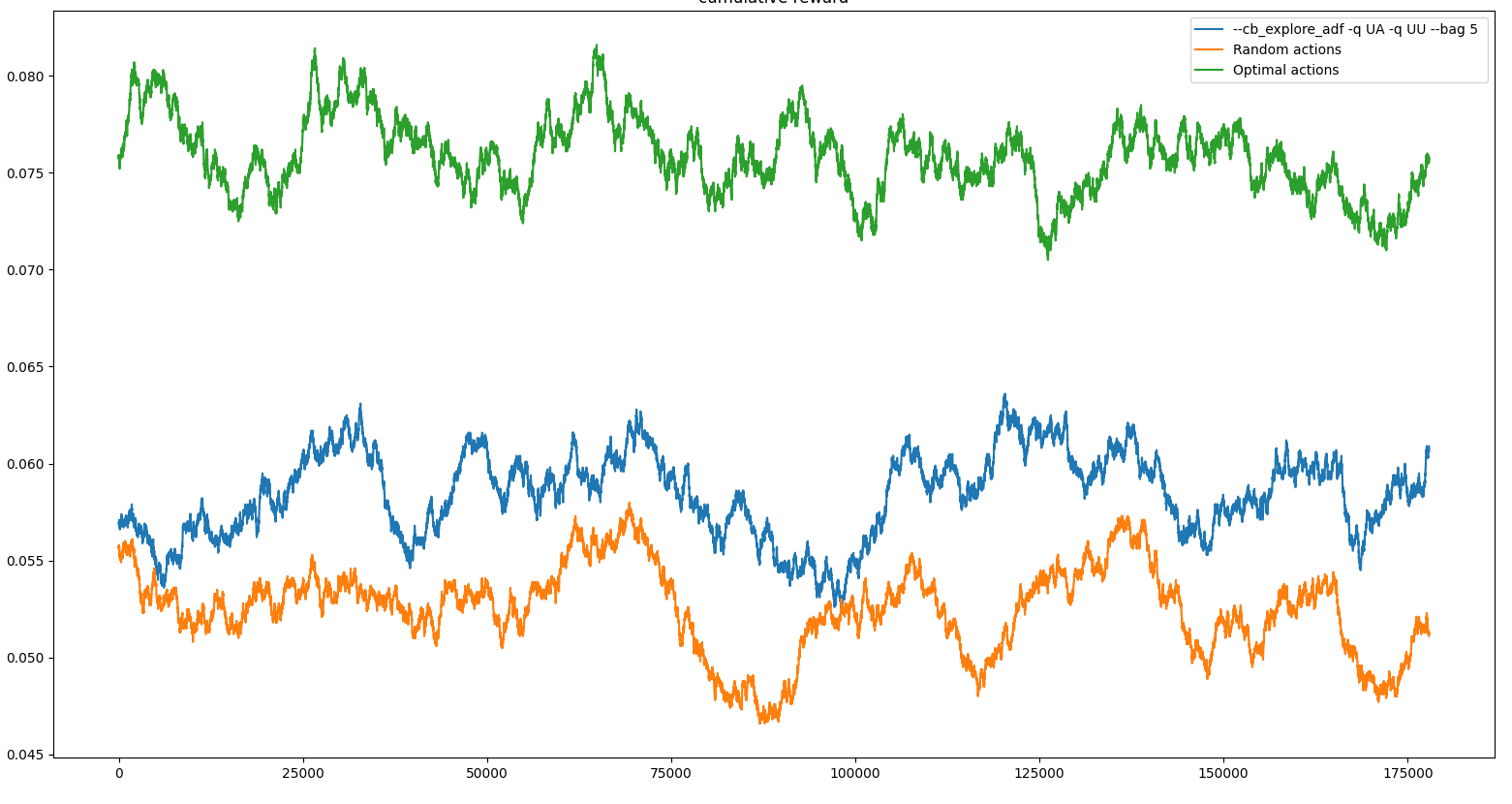
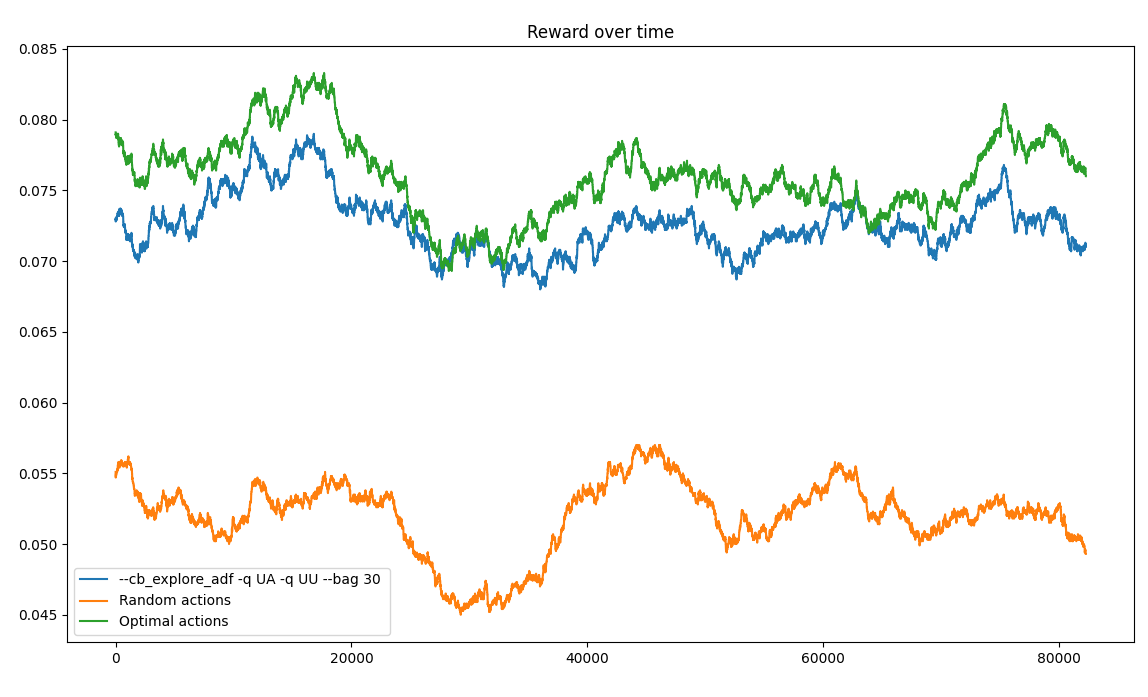
问题:
- 多次启动相同的程序,会导致不同的结果(有时根本不收敛,有时找到最优并保持不变)
- 随着一个糟糕的开端(早期收敛到次优手臂),随着时间的增加,算法仍然没有移动到更好的手臂。
- 该算法似乎早期陷入局部极小值,这就决定了实验的其余部分的性能。(即使有一些勘探因素)
由于CTR相当小,需要大量的比赛才能收敛,我理解这个问题的困难。然而,我希望随着时间的推移,算法会找到最优的。
我是不是错过了VowpalWabbit配置中的一些东西?
回答 1
Stack Overflow用户
发布于 2021-07-19 19:38:03
只要“-袋5”没有epsilon参数,如果所有政策一致,就会产生零概率。
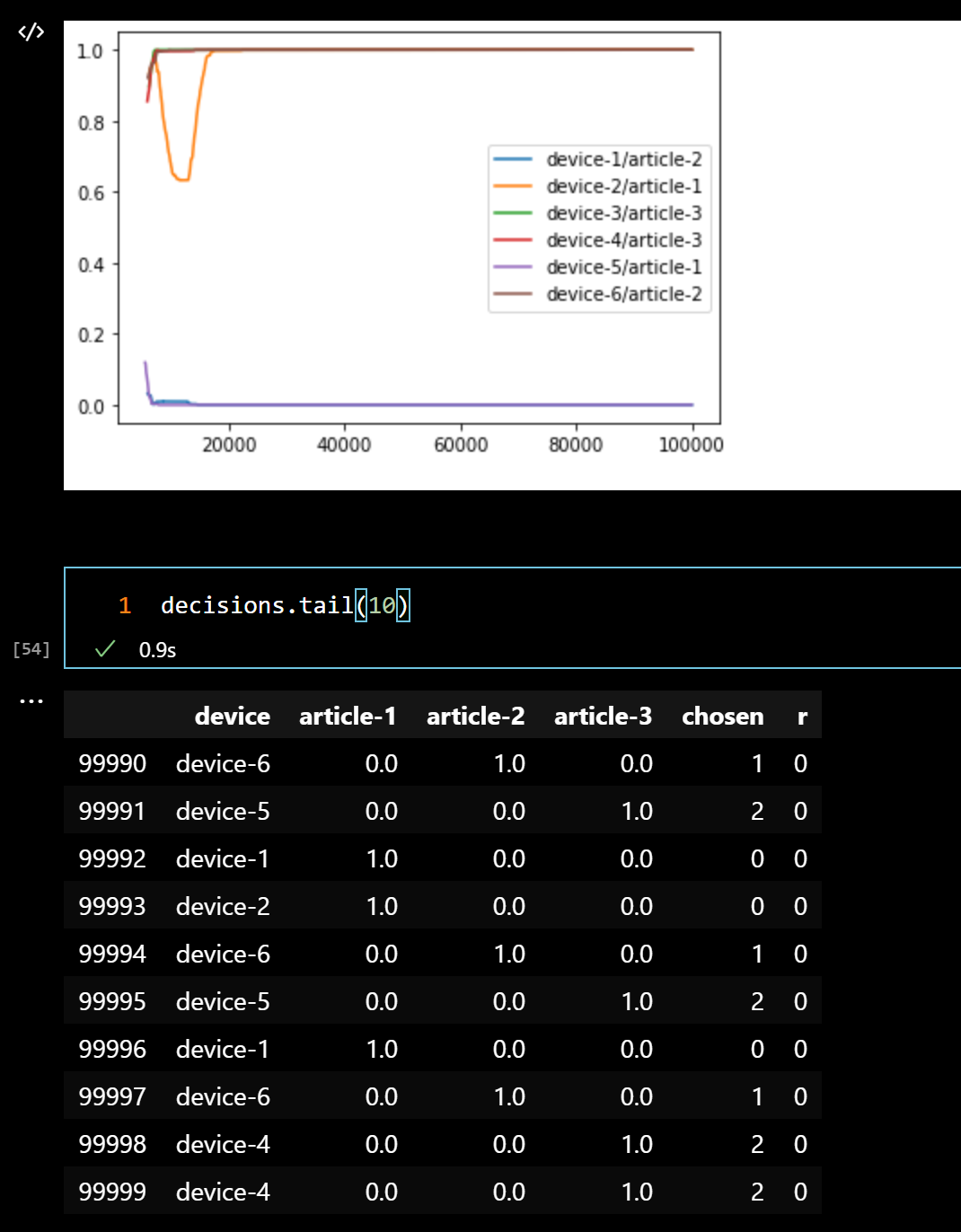
我对您的代码做了一些修改,以跟踪来自actor.predict的概率。
第一个情节:所有“最优行动”的预测概率的移动平均。我们可以看到,对于其中的少数人,我们实际上是在0左右。带有决策的表尾显示,所有的分布实际上都类似于1,0,0。因此,没有机会从这一点恢复,因为我们基本上已经关闭了勘探。
增加少量的勘探(-包5-epsilon 0.02)有助于最终收敛到全球最小值,并给出这样的情节:
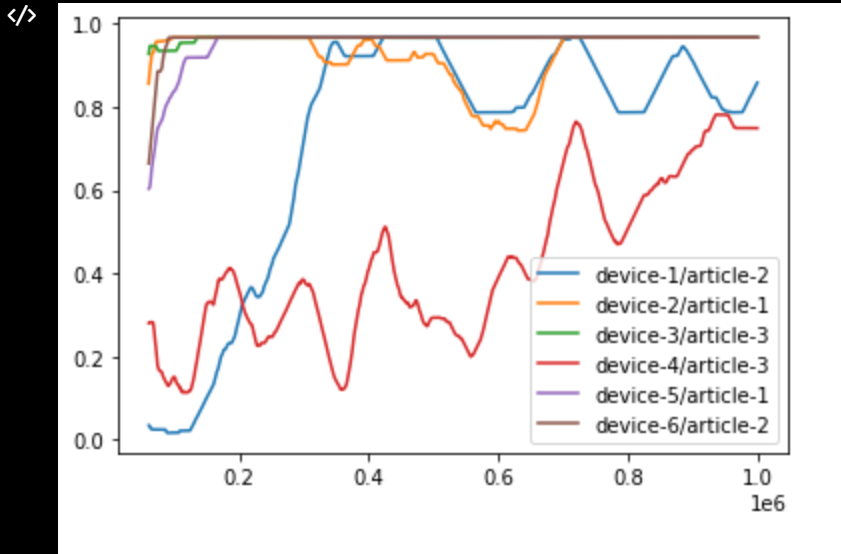
学习似乎不是快速的,但问题的上下文实际上是最模糊的,也不会有太多的遗憾。
https://stackoverflow.com/questions/68192405
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号