
InvalidArgumentError:接收到的标签值为3,超出了[0,3] tensorflow情感分析的有效范围
InvalidArgumentError:接收到的标签值为3,超出了[0,3] tensorflow情感分析的有效范围
提问于 2021-11-08 03:46:11
所以我试着用tensorflow学习情感分析,我的数据集包含3 y_labels,即1 == 'negative,2=='neutral,3=='positive'。这是我的密码
tokenizer = Tokenizer(num_words=vocab_size,oov_token=oov_tok)
tokenizer.fit_on_texts(X)
word_index =tokenizer.word_index
training_sequence = tokenizer.texts_to_sequences(X_train)
testing_sequence = tokenizer.texts_to_sequences(X_test)
training_padding = pad_sequences(training_sequence,maxlen=max_length,padding=padding_type)
test_padding = pad_sequences(training_sequence,maxlen=max_length,padding=padding_type)
training_padded = np.array(training_padding)
training_label = np.array(y_train)
test_padded = np.array(test_padding)
test_label = np.array(y_test)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size,embedding_dim,input_length=max_length ),
tf.keras.layers.GlobalMaxPool1D(),
tf.keras.layers.Dense(20,activation='relu'),
tf.keras.layers.Dense(40,activation='relu'),
tf.keras.layers.Dense(3,activation='relu')
])
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
num_epoch = 200
history = model.fit(training_padded,training_label,epochs=num_epoch)但是我有一个错误,我剪了一点,因为它太长了。
invalidArgumentError: Received a label value of 3 which is outside the valid range of [0, 3). Label values: 2 2 1 3 3 1 1 1 3 2 3 1 3 3 2 1 1 1 1 3 3 2 2 2 1 3 3 3 1 3 2 2
[[node sparse_categorical_crossentropy/SparseSoftmaxCrossEntropyWithLogits/SparseSoftmaxCrossEntropyWithLogits
(defined at c:\users\pc\pycharmprojects\deeplearning_sentiment_analysis\venv\lib\site-packages\keras\backend.py:5113)
]] [Op:__inference_train_function_3960]
Errors may have originated from an input operation.在我看来,我所做的已经是正确的,谁能告诉我出了什么问题吗?据我所知,我们可以在sequental()中构建分类,但是所有的资源都只能用于二进制分类[0,1],我们可以构建多个类吗?
这里是我的示例dataframe
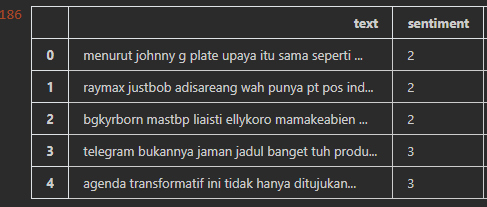
回答 1
Stack Overflow用户
发布于 2022-04-02 09:12:53
我从Luke Borowy那里得到了这样的结论:在多类或多标签分类中,所有标签都应该从0开始。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69878468
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号