
如何在飞行中索引附近的3D点?
在物理模拟(例如,n体系统)中,有时需要跟踪哪些粒子( 3D空间中的点)在某种指数中足以相互作用(在某种截止距离d内)。然而,粒子可以四处移动,因此有必要更新索引,最好是在不完全重新计算的情况下进行。此外,为了计算交互作用的效率,有必要以瓷砖的形式保持相互作用粒子的列表:瓷砖是一个固定大小的数组(例如32x32),其中行和列是粒子,几乎每一行粒子都足够接近几乎每一个列粒子(并且数组跟踪哪些粒子实际交互)。
什么算法可以用来做这件事?
下面是对这个问题的更详细的描述:
- 初始构造:给出一个3D空间中的点列表(存储在浮点数数组中的几千到几百万个点),生成一个固定大小的瓷砖列表( NxN ),其中每个块有两个点列表(N行点和N列点),以及一个布尔数组NxN,它描述了是否应该计算每一行和列粒子之间的交互作用,其中: a.在至少一个瓷砖中找到距离( p1,p2) b.如果任何一对点位于一个以上的瓷砖中,则只将其标记为在布尔数组中计算最多一个瓷砖(不重复), 而且,如果可能的话,瓷砖的数量也相对较少(但这比能够有效地更新瓷砖更重要)
- 更新步骤:如果点的位置变化很小(远小于d),请以最快的方式更新瓷砖列表,以便它们仍然满足相同的条件a和b(此步骤重复多次)。
可以保留任何必要的数据结构来帮助这一点,例如,每个瓷砖的边框,或者像四叉树这样的空间索引。计算每个更新步骤的所有粒子配对距离可能太慢(在任何情况下,我们只关心接近的粒子,因此我们可以跳过大多数可能的距离,例如,沿着一个维度进行排序)。此外,保持一个完整的(四叉树或类似的)指数的所有粒子位置可能太慢。另一方面,在规则的网格上构造瓷砖是非常好的。在3D空间中,每单位体积的粒子密度大致是恒定的,所以瓷砖很可能是由(本质上)固定大小的包围盒建造的。
为了给出这类问题的典型尺度/性质的例子,假设有100万个粒子,它们被排列成直径1单位的随机包装,成一个大小约为100x100x100的立方体。假设截止距离为5个单位,通常每个粒子都会与(2*5)**3或~1000个其他粒子相互作用。瓷砖的尺寸是32x32。大约有1e+9相互作用的粒子对,所以最小可能的瓷砖数是~1e+6。现在假设每次位置变化时,粒子沿着一个随机方向移动约0.0001单位,但总是以至少1单位的距离与任何其他粒子相距,并且每单位体积的典型粒子密度保持不变。通常会有数百万这样的职位更新步骤。由于移动而产生的每一步新创建的交互对的数量是(信封的背面) (10**2 * 6 * 0.0001 / 10**3) * 1e+9 = 60000,因此原则上可以通过将60000个粒子标记为在其原始瓷砖中不相互作用来处理一个更新步骤,并且最多添加60000个新的瓷砖(大多数是空的--每对新相互作用的粒子中有一个)。这很快就会达到这样的地步:大多数瓷砖都是空的,所以肯定有必要以某种方式组合/合并瓷砖--但是,如果不完全重建瓷砖列表,又该如何做呢?
描述这与典型的空间索引(如八叉树)的不同可能是有用的: a.我们只关心将点按点组合成块,而不是在任意边界框中查找哪些点或哪个点最接近查询点--更接近于查询和b的聚类。空间中的点密度相当恒定,c.索引必须经常更新,但大多数移动都很小。
回答 3
Stack Overflow用户
发布于 2021-11-27 15:49:28
我不确定我的推理是否正确,但我有一个想法:
将你的空间划分成一个三维立方体的网格,就像这样的三维:

立方体的边长为d。然后执行以下操作:
- 将所有点分配给包含它们的所有多维数据集;这是快速的,因为您可以从它们的坐标导出一个点的立方体
- 现在检查以下内容:
- 将立方体左上角的所有点标记为碰撞;它们的距离小于
d。此外,在空间中的每一个“四分之一立方体”仅仅是一个立方体的左上角,所以你不会检查同一对数据。 - 检查
(p, q)类型的冲突,其中p是左上四分位数的一个点,而q是一个点而不是左上角的四分位数。以这种方式,你将再次检查每两个点之间的碰撞,最多一次,因为非常多的分位数被精确地检查一次。
- 将立方体左上角的所有点标记为碰撞;它们的距离小于
因为每对点都位于同一个四分位数或相邻四分位数中,它们将由第一个或第二个算法检查。此外,由于点是近似均匀分布的,所以运行时要比n^2 (n=no点数)小得多;总的来说,它是k^2 (k =每个四分位数没有点,它似乎是常数)。
在更新步骤中,只需检查:
- 如果一个点跨越了一个盒子的边界,这应该是快速的,因为你可以一次看一个坐标,而盒子的边界是
d/2的简单倍数。 - 检查以上各点的碰撞情况
要创建瓷砖,将空间划分为(不重叠)立方体的第二个网格,其宽度被选择为s.t。两个粒子之间的平均中心数,它们几乎相互作用,落在一个给定的立方体中,小于你的瓷砖的宽度(即32)。由于每个粒子预计与300-500粒子相互作用,宽度将比d小得多。
然后,在检查步骤1和步骤2中的相互作用时,根据它们相互作用中心的坐标将粒子相互作用分配给这些新的立方体。每个立方体指定一个瓷砖,并在瓷砖中标记分配给该立方体的相互作用粒子。可视化:
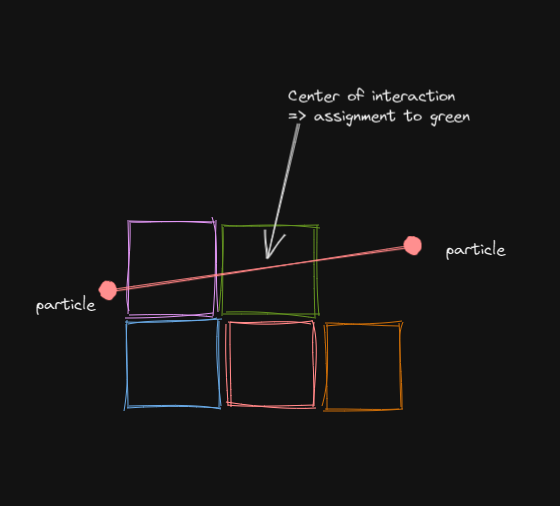
进一步的优化可能是考虑一个点在立方体内的最近邻的距离,并由此导出至少需要多少更新步骤才能更改该点的碰撞状态;然后对这许多步骤忽略这一点。
Stack Overflow用户
发布于 2021-11-27 13:46:32
我建议采用以下算法。例如,我们有立方体1x1x1,截止距离为0.001。
- 让我们选择三个基本锚点:(0,0,0) (0,1,0) (1,0,0)
- 将大小为1000 (1/ 0.001)的数组与每个锚点相关联
- 在每个规则点中添加三个数字。我们将在这些字段中存储给定点与每个锚点之间的距离。
- 同时,这个距离将用作锚点内数组中的索引。0.4324是指指数432。
- 让我们将这组点存储在每三个数组中
- 每次更新时计算规则点与每个锚点之间的距离。
- 在更新期间在数组中的集合之间移动点
给定的结构将给你一个找到所有更近点的简单方法:它是三个集合之间的交集。根据点与锚点之间的距离来选择这些集。
简而言之,它是三个领域之间的交汇点。如果您想要擦除这个交叉口的角,您可能需要为结果应用额外的过滤。
Stack Overflow用户
发布于 2021-11-27 22:16:16
考虑使用Barnes-Hut算法或类似的方法。二维模拟将使用四叉树数据结构来存储粒子,而三维模拟将使用八叉树。
使用树结构的好处是,它以这样一种方式存储粒子,即通过遍历树可以快速找到附近的粒子,而遥远的粒子处于可以忽略的遍历路径中。
维基百科对算法有一个很好的描述:在三维n体模拟中的Barnes-Hut树,Barnes-Hut算法通过将n个身体存储在一个八叉树中(或者在2D模拟中存储一个四叉树)递归地将n个身体分成几个组。此树中的每个节点表示三维空间的一个区域。最上面的节点代表整个空间,它的八个子节点代表空间的八个八位格。空间被递归地细分为八体,直到每个细分包含0或1个体(有些区域没有在所有的八体中都有体)。八叉树中有两种类型的节点:内部节点和外部节点。外部节点没有子节点,并且不是空的,就是表示单个实体。每个内部节点代表其下面的一组身体,并存储其所有子身体的质量中心和总质量。
https://stackoverflow.com/questions/70026017
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号