
如何知道在sktime的TimeSeriesForestClassifier中使用的特性是从哪个输入间隔计算出来的
如何知道在sktime的TimeSeriesForestClassifier中使用的特性是从哪个输入间隔计算出来的
提问于 2021-12-03 09:39:04
我使用sktime库的TimeSeriesForestClassifier类来执行多变量时间序列分类。
代码如下
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sktime.classification.compose import ColumnEnsembleClassifier
from sktime.classification.interval_based import TimeSeriesForestClassifier
from sktime.datasets import load_basic_motions
from sktime.transformations.panel.compose import ColumnConcatenator
X, y = load_basic_motions(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
steps = [
("concatenate", ColumnConcatenator()),
("classify", TimeSeriesForestClassifier(n_estimators=100)),
]
clf = Pipeline(steps)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)我想检查feature_importances_的值,它与输入的长度不一样,而是一个与特性数相同长度的数组。
clf.steps[1][1].feature_importances_我想知道每一个重要的投入的哪一部分是对应的。是否有任何方法可以获得有关TimeSeriesForestClassifier正在从哪个部分计算特性的信息?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-12-04 00:57:14
您可以从以下位置获得集合的每个树的间隔(开始和结束索引):
clf.steps[1][1].intervals_sktime现在也实现了较新的典型区间预报。
当我们第一次实现时间序列森林算法时,我们得到了两个版本。您使用的是推荐的版本,但旧版本为特性重要性图提供了自己的功能(参见下面)。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sktime.classification.compose import ColumnEnsembleClassifier
from sktime.classification.compose import ComposableTimeSeriesForestClassifier
from sktime.datasets import load_basic_motions
from sktime.transformations.panel.compose import ColumnConcatenator
X, y = load_basic_motions(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
steps = [
("concatenate", ColumnConcatenator()),
("classify", ComposableTimeSeriesForestClassifier(n_estimators=100)),
]
clf = Pipeline(steps)
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
clf.steps[-1][-1].feature_importances_.rename(columns={"_slope": "slope"}).plot(xlabel="time", ylabel="feature importance")
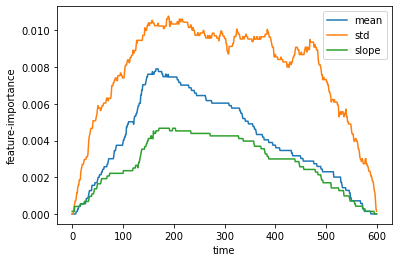
在计算和解释特征重要性时要注意一些微妙的问题。有关问题如下:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70212188
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号