
达斯克工人的记忆不足但我不知道为什么
我有一个dask集群,其中有几个工作人员,每个工作人员的内存为93 GiB = 100 GB,整个集群的内存超过2 TiB (见下图)。当我看到仪表板时,我的工作运行,它波动了一点,但总是看上去像在图片中显示的东西,即没有在内存限制附近。然后,其中一名工人将因内存不足而死亡.我真正感到困惑的是,它是如何发生的,为什么它在仪表板上根本没有显示出来?(请注意,我的dask版本足够新,它将非托管内存显示为每个工作人员的浅色)。
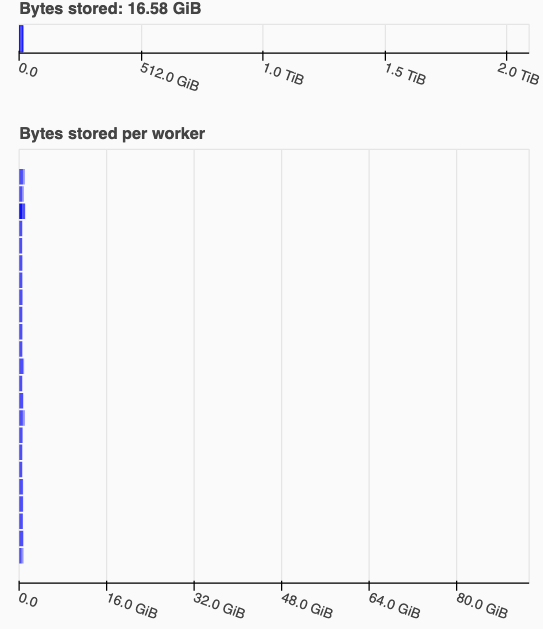
我的任务是加载在2D网格(一个波场)上定义的一个相对较大的数据集。首先,我想在时间域中过滤它(这意味着一次访问每个点的整个时间轴)。然后,我想在每一时间将所有点的过滤数据写入一个单独的文件。当这两个任务是独立的(即,如果我只过滤数据而不写;或者我不过滤数据,只写原始波场),dask工作得非常好。然而,当它们组合在一起时,OOM误差就会发生在大型模拟中(但对于小的模拟仍然很好)。
我的大型模拟的原始波场数据(变量:wave_on_slice_channel)为11.67 GiB。
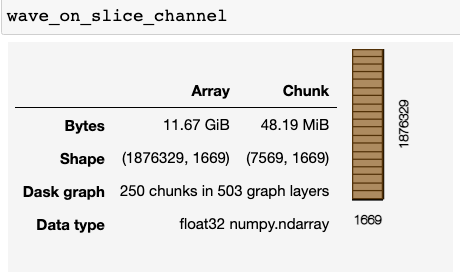
对于一个较小的测试模拟(当以上两个任务组合时工作),它仅为20.75 MiB。

我的(简化)代码如下:
### Function to filter
def filter_wavefield(pos, butter_filter):
filtered = signal.sosfilt(butter_filter,wave_on_slice_channel[pos,:].compute()).astype("float32")
return filtered
### Function to write files
def save_filtered_wavefield(chunk):
# Many lines omitted here for setting up the write
filtered_data = ncfile.createVariable('filtered_data', np.float32, ('data','time'))
filtered_data[:,:] = blocks[chunk].compute()
ncfile.close()
return
### Putting multiple points together into a dask bag to avoid crushing the scheduler
coord_list = [i for i in range(nelem*ngll)]
coord_bag = db.from_sequence(coord_list,npartitions=100)
coord_bag = coord_bag.persist()
wait(coord_bag)
### Submitting tasks for filtering
### and converting back to dask arrays
filtered = coord_bag.map(filter_wavefield, butter_filter)
filtered_waves = filtered.compute() # this is a numpy array
filtered_da = da.from_array(filtered_waves,chunks=wave_on_slice_channel.chunks) # this should be exactly the same in size and shape as the raw wavefield, except this is filtered
blocks = filtered_da.to_delayed().ravel() # Split filtered wavefield by the raw wavefield's original chunks so each writer only sees a portion of the whole wavefield. 无论是小型模拟还是大型模拟,上述代码都能正常工作(因为这只是两个任务之一,即过滤+写入)。作为检查,显示了用于小型模拟的filtered_da,我们可以看到它与来自小型模拟的原始波场完全相同(除了图层的数目,我认为这只是得到这个dask阵列所需的操作数,所以不重要?)

当我想将这些过滤后的数据保存到文件中时,问题就出现了。我有类似的情况:
### Use dask bags to avoid too many tasks
file_list = [i for i in range(len(blocks))]
file_bag = db.from_sequence(file_list,npartitions=len(blocks))
file_bag = file_bag.persist()
wait(file_bag)
### Write out expected number of files to receive
### This file is always written so up to here everything is fine.
with open(dest_dir+'/NOF.txt','w') as f:
f.write("The number of expected filtered data files is: %d" % len(blocks)+'\n')
### Submit tasks to write files
### This is where things break
for i in range(len(blocks)):
f.append(client.submit(save_filtered_wavefield,i)). 注意,传递给每个save_filtered_wavefield调用的变量只是一个索引i,然后在该函数中使用blocks[i].compute()访问数据。我认为这是好的,因为过滤也有wave_on_slice_channel[pos,:].compute()。
我试图从内存中删除一些变量,特别是持久化的coord_bag,但问题仍然存在。我还试着读了一些关于在dask上管理内存的文章,但是由于我似乎看不到仪表板上的任何东西,所以我在这里仍然很迷茫。
很抱歉这么长的帖子,但是任何帮助都会非常感谢!
回答 1
Stack Overflow用户
发布于 2022-12-02 16:45:41
希望后面会有更详细的答案。
我的第一个想法是:访问要提交的函数中的全局dask数组是个坏主意。您应该只调用客户端中的高级API (如数组、包),并编写仅在分区上工作的函数(numpy数组)。通常,您不应该在员工上调用compute()。
https://stackoverflow.com/questions/74651409
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号