
如何将权重应用于具有固定x值断点的分段回归?
大家下午好!
我已经做了一段时间的回归,并建立了一个我有点满意的模型。
这是它的代码和图形结果。我的约束是必须在坐标(到期日= 10和yield_change = 0)处设置起始点,并且断点必须在15、20和30处。(我希望模型从成熟度10开始,在成熟度50时结束)。
为了解决第一个约束,我从成熟度向量中删除了10,并将模型设置为通过原点。
bond_data Dataframe由两个向量组成;第一列"yield_change“和第二列”成熟度“具有以下值:
yield_change <- c(-1.2 -0.9 -1.8 -1.4 -1.8 -2.1 -2.3 -2.1 -2.5 -2.2 -2.4 -2.5 -2.4 -2.4 -3.0 -2.6 -5.1 -4.8 -4.9 -5.0 -5.0 -6.2 -6.1 -6.3 -5.0 -5.0)
maturity <- c(10.27945 10.86027 11.77534 12.35616 12.52055 13.35890 13.86301 14.28219 14.35890 15.35890 15.86301 16.77808 17.36164 17.86575 18.36164 21.86849 22.52877 23.86849 24.36438 25.36712 26.87123 27.87123 28.87123 29.87397 44.37808 49.38356)这是在我从每个值中删除10之前的成熟度向量。
这是回归程序和图表。
library(segmented)
library("readxl")
library(ggplot2)
#DATA PRE-PROCESSING
bond_data <- read_excel("Book2.xlsx")
bond_data <- bond_data[-1,-c(2,3)]
colnames(bond_data) <- c("yield_change","maturity")
bond_data["maturity"] <- as.numeric(bond_data[["maturity"]])
#FITTING TEN YEAR AT ZERO
bond_data["maturity"] <- bond_data$maturity - 10
model_sub <- lm(yield_change~maturity+0, data = bond_data)
segmented.model <- segmented(model_sub,seg.Z=~ maturity,
psi = list(maturity = c(5,10,20)),fixed.psi = c(5,10,20),
control = seg.control(it.max = 0, n.boot = 50))
summary(segmented.model)
o <- segmented.model
xp <- c(0,o$psi[,"Est."], 40)
new_data <- data.frame(xp)
colnames(new_data) <- "maturity"
new_data$dummy1 <- pmax(new_data$maturity - o$psi[1,2], 0)
new_data$dummy2 <- pmax(new_data$maturity - o$psi[2,2], 0)
new_data$dummy3 <- pmax(new_data$maturity - o$psi[3,2], 0)
new_data$dummy4 <-I(new_data$maturity > o$psi[1,2]) * coef(o)[2]
new_data$dummy5 <-I(new_data$maturity > o$psi[2,2]) * coef(o)[3]
new_data$dummy6 <-I(new_data$maturity > o$psi[3,2]) * coef(o)[4]
names(new_data)[-1] <- names(model.frame(o))[-c(1,2)]
yp <- predict(o,new_data)
plot(bond_data$maturity+10,bond_data$yield_change, pch=16, col="blue",ylim = c(-8,0),
xlab = "maturity",ylab = "yield_change")
lines(xp+10,yp)
#BREAKPOINT VALUES
break_maturities <- c(0,5,10,20,40)
maturities_df <- data.frame(break_maturities)
colnames(maturities_df) <- "break_maturity"
maturities_df$dummy1 <- pmax(maturities_df$break_maturity - o$psi[1,2], 0)
maturities_df$dummy2 <- pmax(maturities_df$break_maturity - o$psi[2,2], 0)
maturities_df$dummy3 <- pmax(maturities_df$break_maturity - o$psi[3,2], 0)
maturities_df$dummy4 <-I(maturities_df$break_maturity > o$psi[1,2]) * coef(o)[2]
maturities_df$dummy5 <-I(maturities_df$break_maturity > o$psi[2,2]) * coef(o)[3]
maturities_df$dummy6 <-I(maturities_df$break_maturity > o$psi[3,2]) * coef(o)[4]
names(maturities_df)[-1] <- names(model.frame(o))[-c(1,2)]
names(maturities_df)[1] <- "maturity"
fit <- predict(o,maturities_df)
points(break_maturities+10,fit, pch=18, col = "black", cex = 1.5)
break_yields <- data.frame(break_maturities = break_maturities+10,
yield_preds = fit)
breakpoint_yield_predictions <- break_yields #return 2
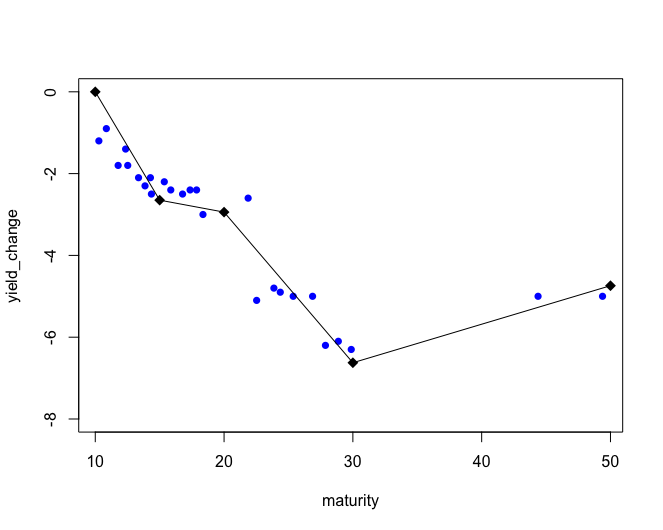
我还覆盖了完全相同的回归图,但没有将第一点设置为(10,0)来说明我试图用权重解决的问题。
(这是它的代码)
#FITTING MODEL WITHOUT SETTING TEN YEAR AT ZERO
model_no_origin <- lm(yield_change~maturity, data = bond_data)
seg_no_origin <- segmented(model_no_origin,seg.Z=~ maturity,
psi = list(maturity = c(5,10,20)),fixed.psi = c(5,10,20),
control = seg.control(it.max = 0, n.boot = 50))
mno <- seg_no_origin
xp <- c(0,mno$psi[,"Est."], 40)
new_data <- data.frame(xp)
colnames(new_data) <- "maturity"
new_data$dummy1 <- pmax(new_data$maturity - mno$psi[1,2], 0)
new_data$dummy2 <- pmax(new_data$maturity - mno$psi[2,2], 0)
new_data$dummy3 <- pmax(new_data$maturity - mno$psi[3,2], 0)
new_data$dummy4 <-I(new_data$maturity > mno$psi[1,2]) * coef(mno)[2]
new_data$dummy5 <-I(new_data$maturity > mno$psi[2,2]) * coef(mno)[3]
new_data$dummy6 <-I(new_data$maturity > mno$psi[3,2]) * coef(mno)[4]
names(new_data)[-1] <- names(model.frame(mno))[-c(1,2)]
yp <- predict(mno,new_data)
lines(xp+10,yp,col = "red")我们得到了以下图(表示回归的红线,不表示点在(成熟度= 10和yield_change = 0),但具有固定的断点成熟度值(15、20、30)。
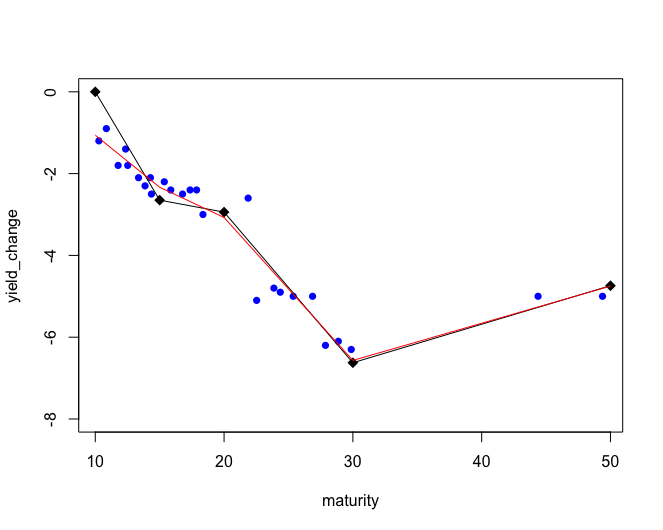
我对将权重应用于20年到期日以上的观测结果并不感兴趣,因为我们可以看到,这两个模型之间的差别很小,但主要是20年到期日之前的所有观测结果(重点是第一部分,我认为是这样,但不确定.)
看一下图,我希望第一个断点在y值上上升,这样它周围的值有更小的残差,这是因为我的模型的主要应用是预测每个断点的yield_change值,我们可以看到这个值在黑线和红线之间有很大的差别。由于没有初始点约束,红线对数据的拟合较好,拟合值较好。
因此,我试图减少那些初始观测值的权重(我认为关键部分是10-15成熟度范围之间的部分),它们的残差比模型的其他部分要大得多。
我使用了以下公式,模型变量是我导出的不使用任何权重的segmented.model。
weight <- 1 / lm(abs(model$residuals) ~ model$fitted.values)$fitted.values^2关于如何将权重应用于分段模型的文档(使用R分段包是非常罕见的)。我认为,对所有分段模型的残差和拟合值应用lm是错误的,因此,我按我所知道的固定间隔分割它(10-15,15-20,20-30,30-50)。这样做可以吗?还是我应该坚持.我甚至不知道这个公式是不是我应该应用的.
下面是我如何为每个回归段实现这个逻辑..。
library(segmented)
library("readxl")
library(ggplot2)
#DATA PRE-PROCESSING
bond_data <- read_excel("Book2.xlsx")
bond_data <- bond_data[-1,-c(2,3)]
colnames(bond_data) <- c("yield_change","maturity")
bond_data["maturity"] <- as.numeric(bond_data[["maturity"]])
#SEGMENTED MODEL FITING
#FITTING TEN YEAR AT ZERO
bond_data["maturity"] <- bond_data$maturity - 10
model_sub <- lm(yield_change~maturity+0, data = bond_data)
segmented.model <- segmented(model_sub,seg.Z=~ maturity,
psi = list(maturity = c(5,10,20)),fixed.psi = c(5,10,20),
control = seg.control(it.max = 0, n.boot = 50))
m <- segmented.model
summary(segmented.model)
o <- segmented.model
#10 TO 15 WEIGHTS
residuals_10 <- o$residuals[bond_data$maturity <= 5]
fitted_10 <- o$fitted.values[bond_data$maturity <= 5]
data_10 <- data.frame(residuals = abs(residuals_10),
fitted = fitted_10)
model_1 <- lm(residuals ~ fitted, data = data_10)
weight_1 <- 1 / model_1$fitted.values^2
#15 TO 20 WEIGHTS
residuals_15 <- o$residuals[bond_data$maturity > 5 & bond_data$maturity <= 10]
fitted_15 <- o$fitted.values[bond_data$maturity > 5 & bond_data$maturity <= 10]
data_15 <- data.frame(residuals = abs(residuals_15),
fitted = fitted_15)
model_2 <- lm(residuals ~ fitted, data = data_15)
weight_2 <- 1 / model_2$fitted.values^2
#20 TO 30 WEIGHTS
residuals_20 <- o$residuals[bond_data$maturity > 10 & bond_data$maturity <= 20]
fitted_20 <- o$fitted.values[bond_data$maturity > 10 & bond_data$maturity <= 20]
data_20 <- data.frame(residuals = abs(residuals_20),
fitted = fitted_20)
model_3 <- lm(residuals ~ fitted, data = data_20)
weight_3 <- 1 / model_3$fitted.values^2
#30 TO 50 WEIGHTS
residuals_30 <- o$residuals[bond_data$maturity > 20 & bond_data$maturity <= 40]
fitted_30 <- o$fitted.values[bond_data$maturity > 20 & bond_data$maturity <= 40]
data_30 <- data.frame(residuals = abs(residuals_30),
fitted = fitted_30)
model_4 <- lm(residuals ~ fitted, data = data_30)
weight_4 <- 1 / model_4$fitted.values^2
#Combined weight vector
weight <- c(weight_1,weight_2,weight_3,weight_4)
#WEIGHTED MODEL
weighted_lm_model <- lm(yield_change ~ maturity+0, data = bond_data, weights = weight)
piecewise_model <- segmented(weighted_lm_model,seg.Z=~ maturity,
psi = list(maturity = c(5,10,20)),fixed.psi = c(5,10,20),
control = seg.control(it.max = 0, n.boot = 50))
o <- piecewise_model
summary <- summary(o) #return 1
xp <- c(0,o$psi[,"Est."], 40)
new_data <- data.frame(xp)
colnames(new_data) <- "maturity"
RMSE <- sqrt(mean(o$residuals^2))
RMSE <- format(round(RMSE,3), nsmall = 3)
new_data$dummy1 <- pmax(new_data$maturity - o$psi[1,2], 0)
new_data$dummy2 <- pmax(new_data$maturity - o$psi[2,2], 0)
new_data$dummy3 <- pmax(new_data$maturity - o$psi[3,2], 0)
new_data$dummy4 <-I(new_data$maturity > o$psi[1,2]) * coef(o)[2]
new_data$dummy5 <-I(new_data$maturity > o$psi[2,2]) * coef(o)[3]
new_data$dummy6 <-I(new_data$maturity > o$psi[3,2]) * coef(o)[4]
names(new_data)[-1] <- names(model.frame(o))[-c(1,2,3)]
yp <- predict(o,new_data)
plot(bond_data$maturity+10,bond_data$yield_change, pch=16, col="blue",ylim = c(-8,0),
xlab = "maturity",ylab = "yield_change")
text(35,-2.5,paste("RMSE =",RMSE,sep = " "))
lines(xp+10,yp)
#BREAKPOINT VALUES
break_maturities <- c(0,5,10,20,40)
maturities_df <- data.frame(break_maturities)
colnames(maturities_df) <- "break_maturity"
maturities_df$dummy1 <- pmax(maturities_df$break_maturity - o$psi[1,2], 0)
maturities_df$dummy2 <- pmax(maturities_df$break_maturity - o$psi[2,2], 0)
maturities_df$dummy3 <- pmax(maturities_df$break_maturity - o$psi[3,2], 0)
maturities_df$dummy4 <-I(maturities_df$break_maturity > o$psi[1,2]) * coef(o)[2]
maturities_df$dummy5 <-I(maturities_df$break_maturity > o$psi[2,2]) * coef(o)[3]
maturities_df$dummy6 <-I(maturities_df$break_maturity > o$psi[3,2]) * coef(o)[4]
names(maturities_df)[-1] <- names(model.frame(o))[-c(1,2,3)]
names(maturities_df)[1] <- "maturity"
fit <- predict(o,maturities_df)
points(break_maturities+10,fit, pch=18, col = "black", cex = 1.5)
break_yields <- data.frame(break_maturities = break_maturities+10,
yield_preds = fit)
breakpoint_yield_predictions <- break_yields #return 2给出图表:
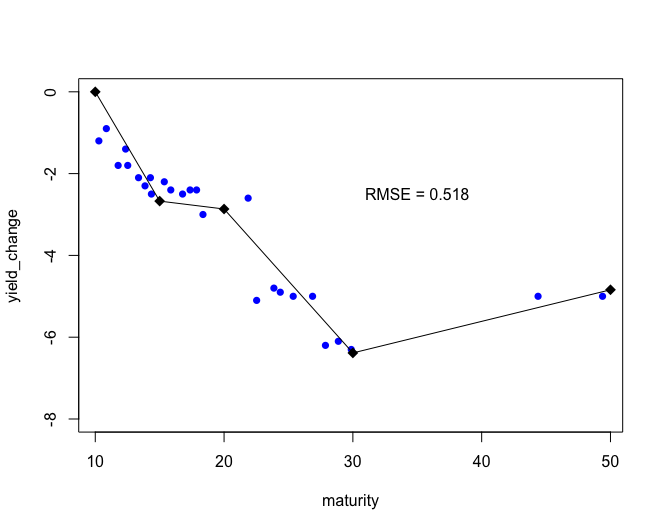
这是我的第二个问题,15年的断点实际上越来越低.这是因为(我认为)计算出的权重使那些接近15个成熟断点的观测结果得分高得多,因为它们的残差很小.
如果我只想把一些权值应用到像前三个这样的观测上,那么我应该给其他的,0,NA或1设置什么权重呢?在20年的期限内,我的模型没有增加任何权重,这使得我的模型表现得非常奇怪……
我所做的也是创建一个条件结构,如果第一个分段模型的abs(残留物)(作为第一部分/线的一部分)高于我根据经验选择的某个值(不理想的东西),那么我对这个观察应用的值比其他的要低。(但输入值是随机选择的.)
从本质上说,我认为我采取了错误的方法,并在网上做了调查,使我几乎找不到这方面的任何东西.我还在考虑减少这些初始变量的权重,并可能将接近15年断点的值设置为最大权重。
概括地说,我的主要目标是解决初始点约束(成熟度= 10和yield_change = 0)在20年前的breakpoint.The模型中创建的更改,主要目标是有准确的断点预测(就像红线中的一个),同时仍然有一个有点精确的分段回归线,而不与我的模型相适应。
这可能有点长的喘息,但我非常感谢你花时间阅读它!任何帮助都将是非常感谢的,我希望你有一个伟大的休息一天!
回答 1
Stack Overflow用户
发布于 2022-11-23 13:43:41
早上好,
我不认为你需要在这里使用重量。我认为你面临的挑战是,如果你估计一个没有拦截的模型,你通常不会得到一个很好的拟合,就像你用一个截距来估计它一样(通常,在一个因变量以零为中心减去平均值后,估计一个模型就没有截距)。与其使用分段包,我只为每个“纽结点”创建三个变量,如(成熟度- 15 )*(如果成熟度>15,则为0)等等。我想这就是你想要的:
maturity <- c(
10.27945, 10.86027, 11.77534, 12.35616, 12.52055, 13.35890, 13.86301,
14.28219, 14.35890, 15.35890, 15.86301, 16.77808, 17.36164, 17.86575,
18.36164, 21.86849, 22.52877, 23.86849, 24.36438, 25.36712, 26.87123,
27.87123, 28.87123, 29.87397, 44.37808, 49.38356
)
maturity15 <- (maturity - 15) * (maturity > 15)
maturity20 <- (maturity - 20) * (maturity > 20)
maturity30 <- (maturity - 30) * (maturity > 30)
plot(maturity, yield_change, col = "darkblue", ylim = c(-8, 0))
lm1 <- lm(yield_change ~ maturity + maturity15 + maturity20 + maturity30)
pred1 <- cbind(maturity, predict(lm1))
pred1 <- pred1[order(pred1[, 1]), ]
lines(pred1, col = "darkred",lwd=4)
weights0 = rep(1,length(maturity))
weights0 = 30*(maturity<12)
table(weights0)
lm2 <- lm(yield_change ~ maturity + maturity15 + maturity20 + maturity30,weights=weights0)
pred2 <- cbind(maturity, predict(lm2))
pred2 <- pred2[order(pred1[, 1]), ]
lines(pred1, col = "green")返回下面的情节。看看加权模型和未加权模型基本上是一样的。
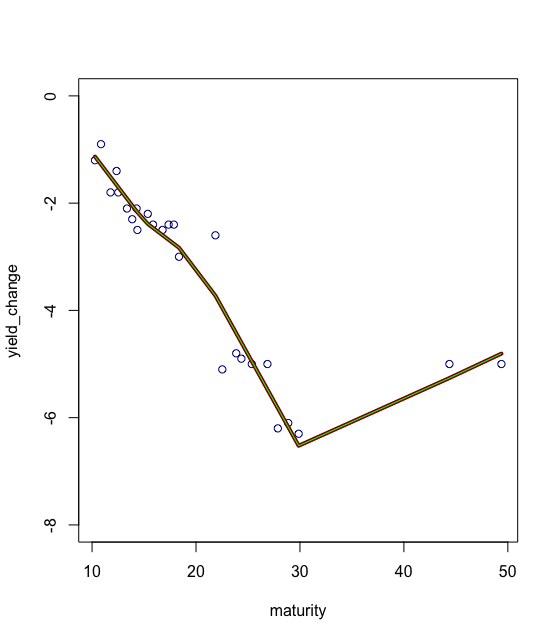
我认为加权回归的方式是,如果将一个观察的权重设为10 (而将其他观察设为1),则将其视为10个观察。你应该得到相同的系数,如果你估计一个未加权的回归,但重复观察10次。在help("lm")中,它声明‘’(即最小和(w*e^2))‘,因此,如果设置w=10和所有其他值为1,则目标相同,就像重复观察10次一样。希望这会有帮助。
https://stackoverflow.com/questions/74546867
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号