
如何在R中获得带有group_by子句的变量列表?
如何在R中获得带有group_by子句的变量列表?
提问于 2022-11-18 17:52:17
我试图在R中使用group_by()子句来获取字符串值的列表,请在下面找到一个示例数据。这是我试过的。
result <- data %>%
group_by(station) %>%
summarise(values = list(variable))
measurement_vars <- c("PRCP", "SNOW", "SNWD", "TMAX", "TMIN")在这种情况下,values列将是一个列表。我想通过使用values函数来检查measurement_vars列是否包含特定的字符串,例如measurement_vars。%in%函数不检查列表中的所有值。因此,我尝试unlist() values;但是,它没有工作。我的问题类似于this one,但它是在SQL中。这是我在结果中所期望的(values不会是一个列表)。
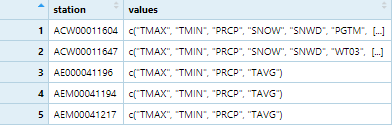
我想过滤包括所有measurement_vars的电台。
data <- structure(list(station = c("ACW00011604", "ACW00011604", "ACW00011604",
"ACW00011604", "ACW00011604", "ACW00011604", "ACW00011604", "ACW00011604",
"ACW00011604", "ACW00011604", "ACW00011604", "ACW00011647", "ACW00011647",
"ACW00011647", "ACW00011647", "ACW00011647", "ACW00011647", "ACW00011647",
"AE000041196", "AE000041196", "AE000041196", "AE000041196", "AEM00041194",
"AEM00041194", "AEM00041194", "AEM00041194", "AEM00041217", "AEM00041217",
"AEM00041217", "AEM00041217"), lat = c(17.1167, 17.1167, 17.1167,
17.1167, 17.1167, 17.1167, 17.1167, 17.1167, 17.1167, 17.1167,
17.1167, 17.1333, 17.1333, 17.1333, 17.1333, 17.1333, 17.1333,
17.1333, 25.333, 25.333, 25.333, 25.333, 25.255, 25.255, 25.255,
25.255, 24.433, 24.433, 24.433, 24.433), lon = c(-61.7833, -61.7833,
-61.7833, -61.7833, -61.7833, -61.7833, -61.7833, -61.7833, -61.7833,
-61.7833, -61.7833, -61.7833, -61.7833, -61.7833, -61.7833, -61.7833,
-61.7833, -61.7833, 55.517, 55.517, 55.517, 55.517, 55.364, 55.364,
55.364, 55.364, 54.651, 54.651, 54.651, 54.651), variable = c("TMAX",
"TMIN", "PRCP", "SNOW", "SNWD", "PGTM", "WDFG", "WSFG", "WT03",
"WT08", "WT16", "TMAX", "TMIN", "PRCP", "SNOW", "SNWD", "WT03",
"WT16", "TMAX", "TMIN", "PRCP", "TAVG", "TMAX", "TMIN", "PRCP",
"TAVG", "TMAX", "TMIN", "PRCP", "TAVG"), start = c(1949, 1949,
1949, 1949, 1949, 1949, 1949, 1949, 1949, 1949, 1949, 1961, 1961,
1957, 1957, 1957, 1961, 1961, 1944, 1944, 1944, 1944, 1983, 1983,
1983, 1983, 1983, 1983, 1984, 1983), end = c(1949, 1949, 1949,
1949, 1949, 1949, 1949, 1949, 1949, 1949, 1949, 1961, 1961, 1970,
1970, 1970, 1961, 1966, 2022, 2022, 2022, 2022, 2022, 2022, 2022,
2022, 2022, 2022, 2020, 2022)), row.names = c(NA, -30L), class = c("tbl_df",
"tbl", "data.frame"))回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-18 17:53:41
我们需要遍历list。要么使用lapply/sapply,要么与purrr::map一起使用
library(dplyr)
library(purrr)
result %>%
filter(map_lgl(values, ~ all(measurement_vars %in% .x)))-output
# A tibble: 2 × 2
station values
<chr> <list>
1 ACW00011604 <chr [11]>
2 ACW00011647 <chr [7]> 如果我们想要filter原始数据,也可以这样做。
data %>%
group_by(station) %>%
filter(all(measurement_vars %in% variable)) %>%
ungroup-output
# A tibble: 18 × 6
station lat lon variable start end
<chr> <dbl> <dbl> <chr> <dbl> <dbl>
1 ACW00011604 17.1 -61.8 TMAX 1949 1949
2 ACW00011604 17.1 -61.8 TMIN 1949 1949
3 ACW00011604 17.1 -61.8 PRCP 1949 1949
4 ACW00011604 17.1 -61.8 SNOW 1949 1949
5 ACW00011604 17.1 -61.8 SNWD 1949 1949
6 ACW00011604 17.1 -61.8 PGTM 1949 1949
7 ACW00011604 17.1 -61.8 WDFG 1949 1949
8 ACW00011604 17.1 -61.8 WSFG 1949 1949
9 ACW00011604 17.1 -61.8 WT03 1949 1949
10 ACW00011604 17.1 -61.8 WT08 1949 1949
11 ACW00011604 17.1 -61.8 WT16 1949 1949
12 ACW00011647 17.1 -61.8 TMAX 1961 1961
13 ACW00011647 17.1 -61.8 TMIN 1961 1961
14 ACW00011647 17.1 -61.8 PRCP 1957 1970
15 ACW00011647 17.1 -61.8 SNOW 1957 1970
16 ACW00011647 17.1 -61.8 SNWD 1957 1970
17 ACW00011647 17.1 -61.8 WT03 1961 1961
18 ACW00011647 17.1 -61.8 WT16 1961 1966或在base R中
Filter(\(x) all(measurement_vars %in% x),
with(data, split(variable, station)))
$ACW00011604
[1] "TMAX" "TMIN" "PRCP" "SNOW" "SNWD" "PGTM" "WDFG" "WSFG" "WT03" "WT08" "WT16"
$ACW00011647
[1] "TMAX" "TMIN" "PRCP" "SNOW" "SNWD" "WT03" "WT16"页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74493606
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号