
批量模型权重的Tensorflow计算
我在复制一篇论文。我有一个基本的Keras模型,用于MNIST分类。现在,对于训练中的样本z,我要计算模型参数的关于该样本丢失的恒心矩阵。我想对训练数据进行平均化(n是训练数据的数量)。
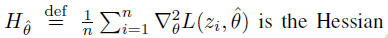
我的最终目标是计算这个值(影响分数):
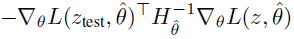
我可以计算左项和右项,想要计算Hessian项。我不知道如何计算一批示例的模型权重(向量化)。我只能在一次速度太慢的样本上计算它。
x=tf.convert_to_tensor(x_train[0:13])
with tf.GradientTape() as t2:
with tf.GradientTape() as t1:
y=model(x)
mce = tf.keras.losses.CategoricalCrossentropy()
y_expanded=y_train[train_idx]
loss=mce(y_expanded,y)
g = t1.gradient(loss, model.weights[4])
h = t2.jacobian(g, model.weights[4])
print(h.shape)为了澄清,如果模型层是维20*30的,我想给它提供一批13样本,并得到一个维度(13,20,30,20,30)的Hessian。现在我只能得到维数(20,30,20,30)的Hessian,它阻碍了向量化(上面的代码)。
这个thread也有同样的问题,只是我想要二阶导数,而不是一阶。
我还尝试了下面的脚本,它返回一个满足维数的(13,20,30,20,30)矩阵,但是当我手动检查这个矩阵的和时,用13单次计算的和,以及从0到12循环的for循环,它们会导致不同的数字,因此它也不能工作,因为我期望相同的值。
x=tf.convert_to_tensor(x_train[0:13])
mce = tf.keras.losses.CategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE)
with tf.GradientTape() as t2:
with tf.GradientTape() as t1:
t1.watch(model.weights[4])
y_expanded=y_train[0:13]
y=model(x)
loss=mce(y_expanded,y)
j1=t1.jacobian(loss, model.weights[4])
j3 = t2.jacobian(j1, model.weights[4])
print(j3.shape)回答 2
Stack Overflow用户
发布于 2022-11-23 11:42:55
这就是hessians的定义,你只能计算一个标量函数的hessian。
但是这里没有什么新的,梯度也是一样的,处理批次的方法是积累梯度,类似的事情可以用hessian做。
如果您知道如何计算loss的恒河,这意味着您可以定义批处理cost,并且仍然能够用相同的方法计算该cost。例如,您可以将cost定义为sum(losses),其中losses是批处理中所有示例的损失向量。
Stack Overflow用户
发布于 2022-11-26 09:48:19
让我们假设您有一个模型,并且您希望通过获取训练图像w.r.t可训练权重的Hessian值来训练模型的权重。
#Import the libraries we need
import tensorflow as tf
from tensorflow.python.eager import forwardpropmodel = tf.keras.models.load_model('model.h5')#Define the Adam Optimizer
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.98,
epsilon=1e-9)#Define the loss function
def loss_function(y_true , y_pred):
return tf.keras.losses.sparse_categorical_crossentropy(y_true , y_pred , from_logits=True)
#Define the Accuracy metric function
def accuracy_function(y_true , y_pred):
return tf.keras.metrics.sparse_categorical_accuracy(y_true , y_pred)Now, define the variables for storing the mean of the loss and accuracy
train_loss = tf.keras.metrics.Mean(name='loss')
train_accuracy = tf.keras.metrics.Mean(name='accuracy')#Now compute the Hessian in some different style for better efficiency of the model
vector = [tf.ones_like(v) for v in model.trainable_variables]
def _forward_over_back_hvp(images, labels):
with forwardprop.ForwardAccumulator(model.trainable_variables, vector) as acc:
with tf.GradientTape() as grad_tape:
logits = model(images, training=True)
loss = loss_function(labels ,logits)
grads = grad_tape.gradient(loss, model.trainable_variables)
hessian = acc.jvp(grads)
optimizer.apply_gradients(zip(hessian, model.trainable_variables))
train_loss(loss) #keep adding the loss
train_accuracy(accuracy_function(labels, logits)) #Keep adding the accuracy#Now, here we need to call the function and train it
import time
for epoch in range(20):
start = time.time()
train_loss.reset_states()
train_accuracy.reset_states()
for i,(x , y) in enumerate(dataset):
_forward_over_back_hvp(x , y)
if(i%50==0):
print(f'Epoch {epoch + 1} Loss {train_loss.result():.4f} Accuracy {train_accuracy.result():.4f}')
print(f'Time taken for 1 epoch: {time.time() - start:.2f} secs\n')Epoch 1 Loss 2.6396 Accuracy 0.1250
Time is taken for 1 epoch: 0.23 secshttps://stackoverflow.com/questions/74454228
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号