
LSTM预测均值,如何解决这个问题?
编辑:
谢谢你们的意见,我不知道这个案子是否解决了,但似乎是这样的。
在我以前的数据准备功能中,我对训练序列进行了调整,从而使LSTM预测了一个平均值。我在网上浏览,偶然发现其他人没有洗牌他们的数据。
我不确定如果不调整数据是否可以--对我来说这似乎很奇怪,而且我也找不到关于这个主题的0-1答案,但当我尝试时,LSTM实际上在测试数据集上做得很好:
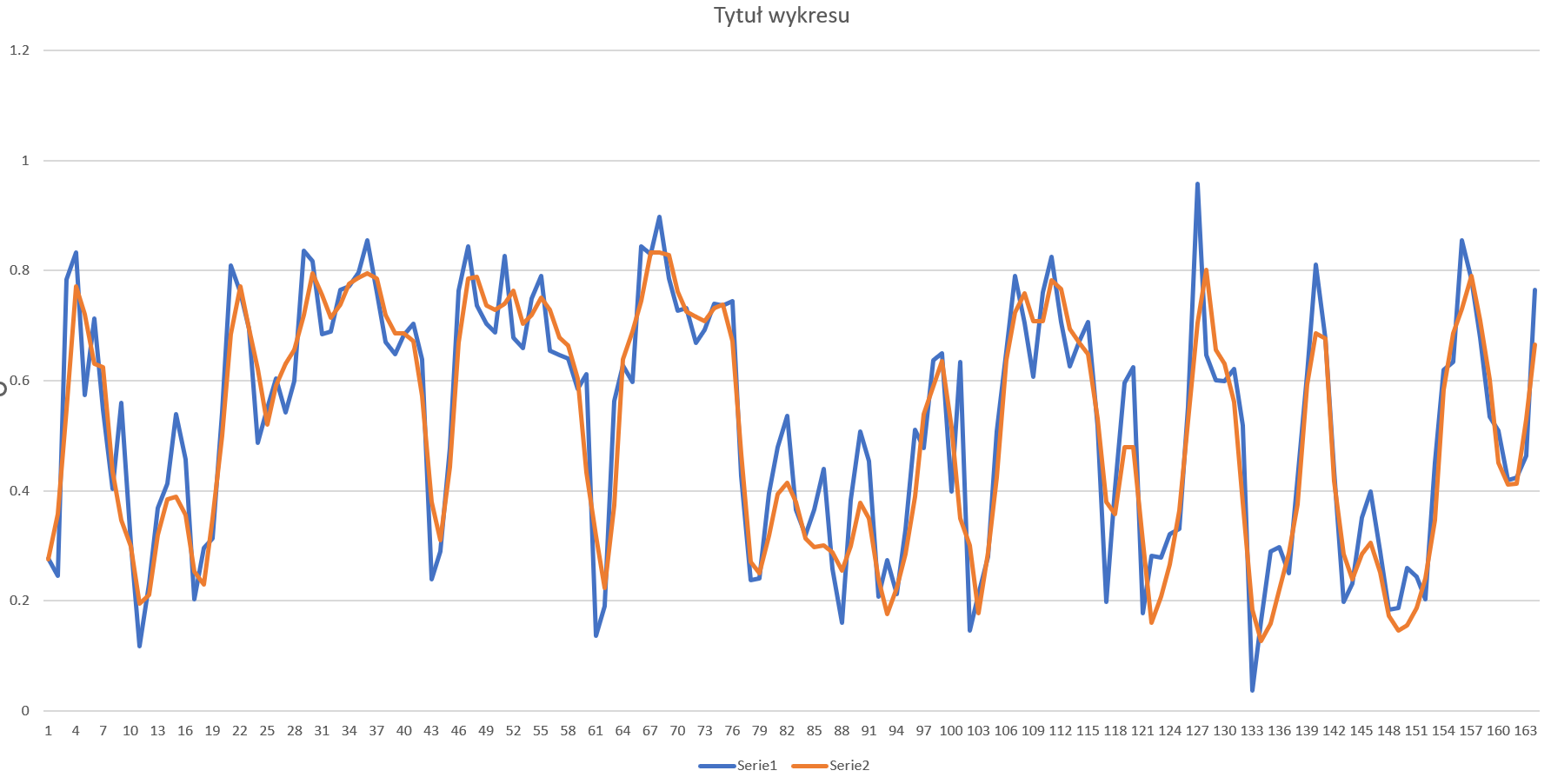
有谁能详细说明一下,为什么把数据洗牌会影响模型呢?或者,在LSTM的情况下,不对数据进行洗牌,就像处理其他模型一样糟糕?
我试图建立一个LSTM来预测一个指标的下一个值,但它意味着。
Data : (注意:数据准备功能在文章的底部,这样文章本身就会更易读),我在每个数据记录中都有25 000条目,并且具有14 columns的特性。所以我的主数组是25 000 x 14。当我准备我的数据时,我创建的序列形状为序列数、序列中的样本、特性以及从那时起在数据的6 sets上:
Y_train
- X_valid,Y_valid
- X_test,Y_test
其中Y测试是我试图预测的特征值的前一步。注意:所有数据集都是使用MinMaxScaler在范围(-1, 1)中缩放的,因此有些数据低于零。
我试图预测的值以以下方式进行(以前的值在X数据集中):
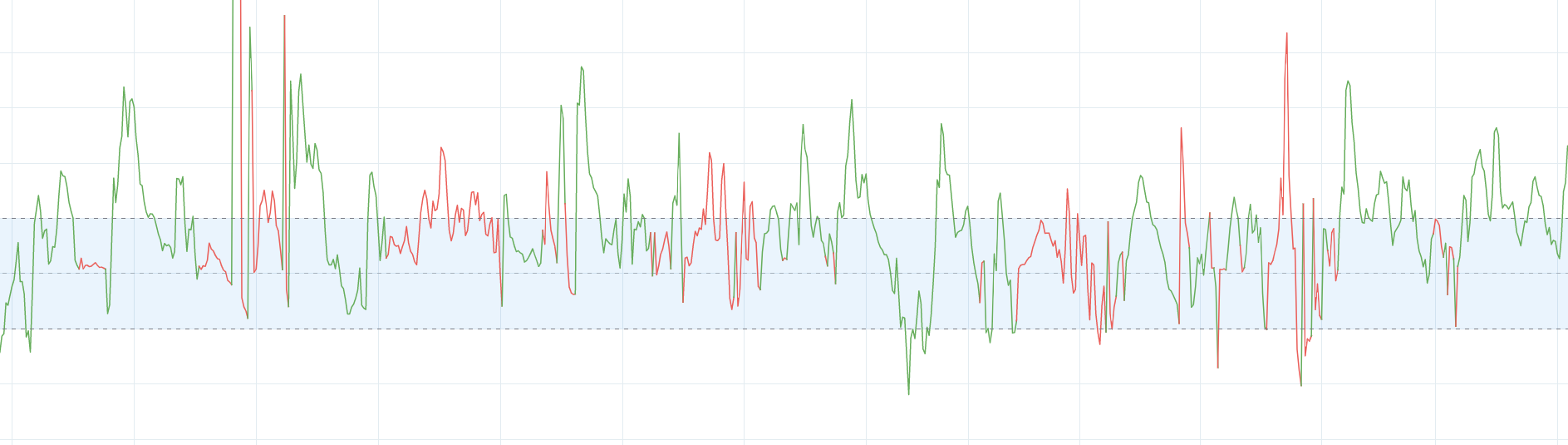
数据示例的示例:(因此,我在另一个图表上绘制了一些系列的不同级别的值):
问题:
问题是,无论有多少神经元,层,我使用什么激活函数,它预测一个特征的平均值,不管是什么,基本上当神经网络击中了0.078周围的价值损失时,损失停止减少,如果我更长的时间,给它更多的时间,在相同的learning rate上,有时损失急剧上升到'NaN或10^30‘。
这是我的模型:
X_train, Y_train, X_valid, Y_valid, X_test, Y_test, scaler = prepare_datasets_lstm_backup(dataset=dataset, samples=200)
optimizer = keras.optimizers.Adam(learning_rate=0.001)
initializer = keras.initializers.he_normal
model = keras.models.Sequential()
model.add(keras.layers.LSTM(64, activation='relu', input_shape=(200, 14), return_sequences=True))
model.add(keras.layers.LSTM(64, activation='relu', return_sequences=True))
model.add(keras.layers.LSTM(3, kernel_regularizer='l2', bias_regularizer='l2', return_sequences=False))
model.add(keras.layers.Activation('sigmoid'))
model.compile(loss='mse', optimizer=optimizer)
history = model.fit(X_train, Y_train, epochs=10, validation_data=(X_valid, Y_valid))
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
plt.xlabel('Epochs')
plt.ylabel('loss function value')
plt.grid()
plt.show()
prediction = model.predict(X_test)可能的解决方案
虽然增加神经元和层的数量无助于我在CrossValidated stackexchange论坛上找到了一篇文章:https://stats.stackexchange.com/questions/261704/training-a-neural-network-for-regression-always-predicts-the-mean,在那里我读了两件重要的东西,下面我将用简短的话来描述我所读过的东西,但是你可以去看看下面的答案:
- 找到@mhdadk的答案并检查出来。
- 找到了Bob的答案,并检查了它。
因此,我们的结论是,即使在1000 neurons中使用two layers,也许我的神经网络也不够复杂。当然,用10000 neurons开发神经网络并查看它是否有效是很有趣的,但问题是我必须在Google上运行它,在那里它可能计算一个月,因此我有一个限制,即每VM 8 CPU。
第一个问题:
是否值得尝试建立一个10k-50k神经元的神经网络,因为我不知道它是否会带来一些积极的结果,如果没有,我将花费500美元或1000美元,甚至一个多月甚至更长的时间。你认为如何?
第二个问题
如果预测原始值似乎是不可行的,那么神经网络是否真的可以与分类一起工作,即预测下一个值是在某个阈值之间,还是在它之上,还是在它下面?或者它也可以预测类的均值,也就是所有预测中最频繁的类?
第三个问题
如果我把太多的数据输入一个神经网络,把数据限制在5000或10000条,这会有帮助吗?
第四题
你还有什么其他的想法可以帮助预测吗?
感谢大家花时间阅读这篇文章,并感谢你们提前提供了帮助:)
正如我在上面所写的,数据准备功能是:
def prepare_datasets_lstm(dataset : pd.DataFrame, samples : int):
main_data_df = dataset.copy()
main_data_df = main_data_df.dropna(how='any').copy()
main_data_df = main_data_df[main_data_df.columns[~main_data_df.columns.isin(['timestamp', 'datetime'])]].copy()
main_data_np = main_data_df.copy().to_numpy(dtype='float32')
scaler = StandardScaler()
signal_data = main_data_np[:, 5]
main_data_scaled = scaler.fit_transform(main_data_np.copy())
joblib.dump(scaler, 'lstm_scaler.save')
samples_val = samples
sequences_val = (main_data_scaled.shape[0] - samples_val) - 1
columns_val = main_data_scaled.shape[1]
# seqeunces = np.empty((liczba sekwencji, liczba sampli w sekwencji, kolumny))
seqeunces = np.empty((sequences_val + 1, samples_val, columns_val))
# etiquets = np.empty((liczba sekwencji - 1, 1 element w sekwencji, liczba przewidywanych wartości))
etiquets = np.empty((sequences_val, 1, 1))
for i in range(sequences_val + 1):
for j in range(samples_val):
for k in range(columns_val):
seqeunces[i, j, k] = main_data_scaled[i + j, k]
for i in range(sequences_val):
etiquets[i, 0, 0] = signal_data[i]#seqeunces[i + 1, 0, 5] # CCI
seqeunces = seqeunces[:-1, :, :].copy()
shape_x = main_data_scaled.shape[0]
train_len = math.floor(0.7 * shape_x)
valid_len = math.floor((shape_x - train_len) * 0.5) + train_len
train_dataset = seqeunces[:train_len, :, :].copy()
train_etiquets = etiquets[:train_len, :, :].copy()
valid_dataset = seqeunces[train_len : valid_len, :, :].copy()
valid_etiquets = etiquets[train_len : valid_len, :, :].copy()
test_dataset = seqeunces[valid_len:, :, :].copy()
test_etiquets = etiquets[valid_len:, :, :].copy()
train_etiquets_shuffled, train_dataset_shuffled = shuffle((train_dataset, train_etiquets), random_state=0)
valid_etiquets_shuffled, valid_dataset_shuffled = shuffle((valid_dataset, valid_etiquets), random_state=0)
X_train = train_dataset_shuffled.copy()
Y_train = train_etiquets_shuffled.copy()
X_valid = valid_dataset_shuffled.copy()
Y_valid = valid_etiquets_shuffled.copy()
X_test = test_dataset.copy()
Y_test = test_etiquets.copy()
return X_train, Y_train, X_valid, Y_valid, X_test, Y_test, scaler回答 2
Stack Overflow用户
发布于 2022-11-11 17:39:07
问:我正在尝试做一个预测指标的下一个值,但它预测的是均值。。
答: LSTM和另一种类型的神经元在其范围内从输入变化中预测值,参见我在密集但LSTM中的例子(我刚才写并测试了)--问题是,他试图预测序列,而不是平均值输出,我举了10个输入到输出序列的例子。
问题1:是否值得尝试建立一个10k-50k神经元的神经网络?
答:有可能,但目标是使用历史数据,您可以使用优化器来训练模型,并在实时响应中进行工作和反馈。
Q 2:如果预测原始值似乎是不可行的,那么神经网络是否真的可以与分类一起工作,即预测下一个值是在某个阈值之间,还是在它之上,还是在它下面?还是也可以预测类的均值,也就是所有预测中最频繁的类?
答:可能的尺度,或范围,它们是数据集,范围或意义应用.
问题3:我给一个神经网络输入过多的数据,并将数据限制在5000或10000个条目会有帮助吗?
答:可能会让你训练得更快、更可靠,但整个历史是为了研究它可以重复的模式。
问题4:你还有什么其他的想法可以帮助预测吗?
答:更好的模型,数学问题,输入数据,数据意义和研究研究。
样品:冰淇淋周日歌曲,简单如冰淇淋,但时尚的结果。
import os
from os.path import exists
import tensorflow as tf
import tensorflow_text as tft
import matplotlib.pyplot as plt
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
None
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
physical_devices = tf.config.experimental.list_physical_devices('GPU')
assert len(physical_devices) > 0, "Not enough GPU hardware devices available"
config = tf.config.experimental.set_memory_growth(physical_devices[0], True)
print(physical_devices)
print(config)
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Variables
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
input_word = tf.constant(' \'Cause it\'s easy as an ice cream sundae Slipping outta your hand into the dirt Easy as an ice cream sundae Every dancer gets a little hurt Easy as an ice cream sundae Slipping outta your hand into the dirt Easy as an ice cream sundae Every dancer gets a little hurt Easy as an ice cream sundae Oh, easy as an ice cream sundae ')
dataset = tf.data.Dataset.from_tensors( tf.strings.bytes_split(input_word) )
window_size = 6
vocab = [ "a", "b", "c", "d", "e", "f", "g", "h", "I", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z", "_" ]
layer = tf.keras.layers.StringLookup(vocabulary=vocab)
ZeroPadding1D = tf.keras.layers.ZeroPadding1D(padding=(2))
list_output = [ ]
list_label = [ ]
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Class and Functions
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
class MyDenseLayer(tf.keras.layers.Layer):
def __init__(self, num_outputs):
super(MyDenseLayer, self).__init__()
self.num_outputs = num_outputs
def build(self, input_shape):
self.kernel = self.add_weight("kernel",
shape=[int(10),
self.num_outputs])
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Datasets
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
dataset = dataset.map(lambda x: tft.sliding_window(x, width=window_size, axis=0)).flat_map(tf.data.Dataset.from_tensor_slices)
for sample in dataset:
inputs_vocab = tf.constant( tf.cast( layer( sample ), dtype=tf.float32 ), shape=(1, 6, 1) )
result = tf.constant( ZeroPadding1D( inputs_vocab ), shape=(10, 1) )
list_output.append( [ int( result.numpy()[0] ), int( result.numpy()[1] ), int( result.numpy()[2] ), int( result.numpy()[3] ), int( result.numpy()[4] ),
int( result.numpy()[5] ), int( result.numpy()[6] ), int( result.numpy()[7] ), int( result.numpy()[8] ), int( result.numpy()[9] ) ] )
list_label.append(
[ int( result.numpy()[0] ), int( result.numpy()[1] ), int( result.numpy()[2] ), int( result.numpy()[3] ), int( result.numpy()[4] ),
int( result.numpy()[5] ), int( result.numpy()[6] ), int( result.numpy()[7] ), int( result.numpy()[8] ), int( result.numpy()[9] ) ]
)
print( list_label )
start = 0
limit = 322
X = tf.range(start, limit, delta=1, dtype=tf.int32, name='range')
fig = plt.figure(1) #identifies the figure
plt.title("Word and Time", fontsize='16') #title
plt.plot( X, list_output )
plt.show()
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Training
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
layer_dense = MyDenseLayer(10)
model = tf.keras.Sequential([
tf.keras.Input(shape=(1, 10)),
layer_dense,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(192, activation='relu'),
tf.keras.layers.Dense(10),
])
model.summary()
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Callback
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
class custom_callback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if( logs['accuracy'] >= 0.80 ):
self.model.stop_training = True
custom_callback = custom_callback()
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Optimizer
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
optimizer = tf.keras.optimizers.Nadam(
learning_rate=0.00001, beta_1=0.9, beta_2=0.999, epsilon=1e-07,
name='Nadam'
)
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Loss Fn
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
lossfn = tf.keras.losses.MeanSquaredError(
reduction=tf.keras.losses.Reduction.AUTO,
name='mean_squared_error'
)
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Model Summary
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
model.compile(optimizer=optimizer, loss=lossfn, metrics=['accuracy'])
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Datasets
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
dataset = tf.data.Dataset.from_tensor_slices(( tf.constant(list_output, shape=(322, 1, 1, 10)), tf.constant(list_label, shape=(322, 1, 1, 10) )))
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Training
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
history = model.fit( dataset, batch_size=100, epochs=500, callbacks=[custom_callback] )
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
: Prediction
"""""""""""""""""""""""""""""""""""""""""""""""""""""""""
temp = tf.constant( model.predict( tf.constant(list_output, shape=(322, 1, 10)) ), shape=(322, 10) )
fig = plt.figure(2) #identifies the figure
plt.title("Word and Time", fontsize='16') #title
plt.plot( X, temp )
plt.show()输出:
Epoch 38/500
322/322 [==============================] - 2s 7ms/step - loss: 11.6526 - accuracy: 0.7671
Epoch 39/500
322/322 [==============================] - 2s 7ms/step - loss: 11.1693 - accuracy: 0.7795
Epoch 40/500
322/322 [==============================] - 2s 7ms/step - loss: 10.7022 - accuracy: 0.7919
Epoch 41/500
322/322 [==============================] - 2s 6ms/step - loss: 10.2527 - accuracy: 0.8106
11/11 [==============================] - 0s 2ms/step
Stack Overflow用户
发布于 2022-11-11 16:11:07
你最好的选择可能是建立更小的模型,比如简单的神经元很少的深神经网络(< 50),看看它有多好,用不同的学习速度迭代,就像很多。在从头开始开发一个模型时,添加复杂的知识很少有帮助。一旦你有了一个简单的工作模型,增加混乱是很容易的,但是为了看什么可行,最好从小开始
https://stackoverflow.com/questions/74404427
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号