
R中的LSTM seq2seq模型似乎没有使用经过训练的模型进行预测。
对于一个项目,我试图创建一个函数,可以将拉丁字母中的名称“翻译”为IPA (音标)。
我在R的sequence2sequence模型中找到了一个用于字符级机器翻译的例子:https://github.com/rstudio/keras/blob/main/vignettes/examples/lstm_seq2seq.R
我正在使用使用以下在线服务生成的数据进行培训:https://clarin.phonetik.uni-muenchen.de/BASWebServices/interface/Grapheme2Phoneme
我现在的剧本在下面。不要全读,我会在下面高亮显示相关的部分。我把整个剧本都收录了,仅供参考。培训数据可以在这里下载:https://file.io/ut4IkeLRqyIa
library(keras)
library(data.table)
library(stringr)
# Clear the workspace
rm(list = ls())
# Set initial parameters
batch_size = 64 # Batch size for training.
epochs = 3 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
num_samples = 3500 # Number of samples to train on.
# Load the training data
load("./data_seq2seq/ipa_abc_ENG.rda")
## Vectorize the data.
input_texts <- dataset[[2]]
target_texts <- paste0('\t',dataset[[1]],'\n')
input_texts <- lapply( input_texts, function(s) strsplit(s, split="")[[1]])
target_texts <- lapply( target_texts, function(s) strsplit(s, split="")[[1]])
input_characters <- sort(unique(unlist(input_texts)))
target_characters <- sort(unique(unlist(target_texts)))
num_encoder_tokens <- length(input_characters)
num_decoder_tokens <- length(target_characters)
max_encoder_seq_length <- max(sapply(input_texts,length))
max_decoder_seq_length <- max(sapply(target_texts,length))
cat('Number of samples:', length(input_texts),'\n')
cat('Number of unique input tokens:', num_encoder_tokens,'\n')
cat('Number of unique output tokens:', num_decoder_tokens,'\n')
cat('Max sequence length for inputs:', max_encoder_seq_length,'\n')
cat('Max sequence length for outputs:', max_decoder_seq_length,'\n')
input_token_index <- 1:length(input_characters)
names(input_token_index) <- input_characters
target_token_index <- 1:length(target_characters)
names(target_token_index) <- target_characters
encoder_input_data <- array(
0, dim = c(length(input_texts), max_encoder_seq_length, num_encoder_tokens))
decoder_input_data <- array(
0, dim = c(length(input_texts), max_decoder_seq_length, num_decoder_tokens))
decoder_target_data <- array(
0, dim = c(length(input_texts), max_decoder_seq_length, num_decoder_tokens))
for(i in 1:length(input_texts)) {
d1 <- sapply( input_characters, function(x) { as.integer(x == input_texts[[i]]) })
encoder_input_data[i,1:nrow(d1),] <- d1
d2 <- sapply( target_characters, function(x) { as.integer(x == target_texts[[i]]) })
decoder_input_data[i,1:nrow(d2),] <- d2
d3 <- sapply( target_characters, function(x) { as.integer(x == target_texts[[i]][-1]) })
decoder_target_data[i,1:nrow(d3),] <- d3
}
##----------------------------------------------------------------------
## Create the model
##----------------------------------------------------------------------
## Define an input sequence and process it.
encoder_inputs <- layer_input(shape=list(NULL,num_encoder_tokens))
encoder <- layer_lstm(units=latent_dim, return_state=TRUE)
encoder_results <- encoder_inputs %>% encoder
## We discard `encoder_outputs` and only keep the states.
encoder_states <- encoder_results[2:3]
## Set up the decoder, using `encoder_states` as initial state.
decoder_inputs <- layer_input(shape=list(NULL, num_decoder_tokens))
## We set up our decoder to return full output sequences,
## and to return internal states as well. We don't use the
## return states in the training model, but we will use them in inference.
decoder_lstm <- layer_lstm(units=latent_dim, return_sequences=TRUE,
return_state=TRUE, stateful=FALSE)
decoder_results <- decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense <- layer_dense(units=num_decoder_tokens, activation='softmax')
decoder_outputs <- decoder_dense(decoder_results[[1]])
## Define the model that will turn
## `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model <- keras_model( inputs = list(encoder_inputs, decoder_inputs),
outputs = decoder_outputs )
## Compile model
model %>% compile(optimizer='rmsprop', loss='categorical_crossentropy')
## Run model
model %>% fit( list(encoder_input_data, decoder_input_data), decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
## Below the model is saved. It's never referenced anywhere else in the code anymore, however.
## I'm unsure how to load it into a function that uses the model.
## Save model
#save_model_hdf5(model,'./data_seq2seq/s2s_abc_ipa_EN.h5')
#save_model_weights_hdf5(model,'./data_seq2seq/s2s-wt_abc_ipa_EN.h5')
##model <- load_model_hdf5('s2s.h5')
##load_model_weights_hdf5(model,'s2s-wt.h5')
##----------------------------------------------------------------------
## Next: inference mode (sampling).
##----------------------------------------------------------------------
## Here's the drill:
## 1) encode input and retrieve initial decoder state
## 2) run one step of decoder with this initial state
## and a "start of sequence" token as target.
## Output will be the next target token
## 3) Repeat with the current target token and current states
## Define sampling models
encoder_model <- keras_model(encoder_inputs, encoder_states)
decoder_state_input_h <- layer_input(shape=latent_dim)
decoder_state_input_c <- layer_input(shape=latent_dim)
decoder_states_inputs <- c(decoder_state_input_h, decoder_state_input_c)
decoder_results <- decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states <- decoder_results[2:3]
decoder_outputs <- decoder_dense(decoder_results[[1]])
decoder_model <- keras_model(
inputs = c(decoder_inputs, decoder_states_inputs),
outputs = c(decoder_outputs, decoder_states))
## Reverse-lookup token index to decode sequences back to
## something readable.
reverse_input_char_index <- as.character(input_characters)
reverse_target_char_index <- as.character(target_characters)
decode_sequence <- function(input_seq) {
## Encode the input as state vectors.
states_value <- predict(encoder_model, input_seq)
## Generate empty target sequence of length 1.
target_seq <- array(0, dim=c(1, 1, num_decoder_tokens))
## Populate the first character of target sequence with the start character.
target_seq[1, 1, target_token_index['\t']] <- 1.
## Sampling loop for a batch of sequences
## (to simplify, here we assume a batch of size 1).
stop_condition = FALSE
decoded_sentence = ''
maxiter = max_decoder_seq_length
niter = 1
while (!stop_condition && niter < maxiter) {
## output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
decoder_predict <- predict(decoder_model, c(list(target_seq), states_value))
output_tokens <- decoder_predict[[1]]
## Sample a token
sampled_token_index <- which.max(output_tokens[1, 1, ])
sampled_char <- reverse_target_char_index[sampled_token_index]
decoded_sentence <- paste0(decoded_sentence, sampled_char)
decoded_sentence
## Exit condition: either hit max length
## or find stop character.
if (sampled_char == '\n' ||
length(decoded_sentence) > max_decoder_seq_length) {
stop_condition = TRUE
}
## Update the target sequence (of length 1).
## target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[1, 1, ] <- 0
target_seq[1, 1, sampled_token_index] <- 1.
## Update states
h <- decoder_predict[[2]]
c <- decoder_predict[[3]]
states_value = list(h, c)
niter <- niter + 1
}
return(decoded_sentence)
}
for (seq_index in 1:10) {
## Take one sequence (part of the training test)
## for trying out decoding.
input_seq = encoder_input_data[seq_index,,,drop=FALSE]
decoded_sentence = decode_sequence(input_seq)
target_sentence <- gsub("\t|\n","",paste(target_texts[[seq_index]],collapse=''))
input_sentence <- paste(input_texts[[seq_index]],collapse='')
cat('-\n')
cat('Input sentence : ', input_sentence,'\n')
cat('Target sentence : ', target_sentence,'\n')
cat('Decoded sentence: ', decoded_sentence,'\n')
}
# I wrote this custom function to test the predictions
# This was reverse engineered from the above code
decode_string <- function(x){
x_decode <- unlist(strsplit(x, ""))
d1_input <- sapply( input_characters, function(x) { as.integer(x == x_decode) })
d1 <- array(data = 0, dim = c(1,23,27))
d1[1, 1:nrow(d1_input),] <- d1_input
decode_sequence(d1)
}对模型进行培训,然后将其保存在这段代码中:
## Define the model that will turn
## `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model <- keras_model( inputs = list(encoder_inputs, decoder_inputs),
outputs = decoder_outputs )
## Compile model
model %>% compile(optimizer='rmsprop', loss='categorical_crossentropy')
## Run model
model %>% fit( list(encoder_input_data, decoder_input_data), decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
## Save model
save_model_hdf5(model,'s2s.h5')
save_model_weights_hdf5(model,'s2s-wt.h5')我希望在预测过程中使用对象“模型”。相反,它从零开始创建编码器模型和解码器模型(?):
encoder_model <- keras_model(encoder_inputs, encoder_states)
decoder_state_input_h <- layer_input(shape=latent_dim)
decoder_state_input_c <- layer_input(shape=latent_dim)
decoder_states_inputs <- c(decoder_state_input_h, decoder_state_input_c)
decoder_results <- decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states <- decoder_results[2:3]
decoder_outputs <- decoder_dense(decoder_results[[1]])
decoder_model <- keras_model(
inputs = c(decoder_inputs, decoder_states_inputs),
outputs = c(decoder_outputs, decoder_states))
## Reverse-lookup token index to decode sequences back to
## something readable.
reverse_input_char_index <- as.character(input_characters)
reverse_target_char_index <- as.character(target_characters)然后它用这些来做预测:
decode_sequence <- function(input_seq) {
## Encode the input as state vectors.
states_value <- predict(encoder_model, input_seq)
## Generate empty target sequence of length 1.
target_seq <- array(0, dim=c(1, 1, num_decoder_tokens))
## Populate the first character of target sequence with the start character.
target_seq[1, 1, target_token_index['\t']] <- 1.
## Sampling loop for a batch of sequences
## (to simplify, here we assume a batch of size 1).
stop_condition = FALSE
decoded_sentence = ''
maxiter = max_decoder_seq_length
niter = 1
while (!stop_condition && niter < maxiter) {
## output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
decoder_predict <- predict(decoder_model, c(list(target_seq), states_value))
output_tokens <- decoder_predict[[1]]
## Sample a token
sampled_token_index <- which.max(output_tokens[1, 1, ])
sampled_char <- reverse_target_char_index[sampled_token_index]
decoded_sentence <- paste0(decoded_sentence, sampled_char)
decoded_sentence
## Exit condition: either hit max length
## or find stop character.
if (sampled_char == '\n' ||
length(decoded_sentence) > max_decoder_seq_length) {
stop_condition = TRUE
}
## Update the target sequence (of length 1).
## target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[1, 1, ] <- 0
target_seq[1, 1, sampled_token_index] <- 1.
## Update states
h <- decoder_predict[[2]]
c <- decoder_predict[[3]]
states_value = list(h, c)
niter <- niter + 1
}
return(decoded_sentence)
}
for (seq_index in 1:10) {
## Take one sequence (part of the training test)
## for trying out decoding.
input_seq = encoder_input_data[seq_index,,,drop=FALSE]
decoded_sentence = decode_sequence(input_seq)
target_sentence <- gsub("\t|\n","",paste(target_texts[[seq_index]],collapse=''))
input_sentence <- paste(input_texts[[seq_index]],collapse='')
cat('-\n')
cat('Input sentence : ', input_sentence,'\n')
cat('Target sentence : ', target_sentence,'\n')
cat('Decoded sentence: ', decoded_sentence,'\n')
}我在这里有什么不懂的?最后一个循环给我的结果是,当我为更多的时代训练模型时,结果明显的改善了。但是,当我从头开始加载模型时,我无法将它加载到预测器中。如何使用经过训练的翻译模型?
编辑:所以脚本中引用了3个keras模型。"main“模型,也就是"encoder_model”和"decoder_model“。我已经对其中的每一个进行了总结(),并得到了以下结果:
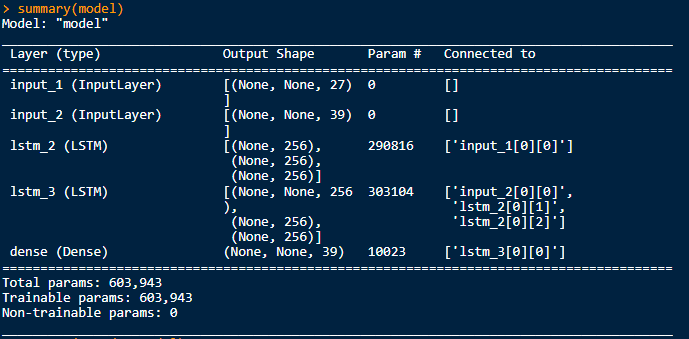
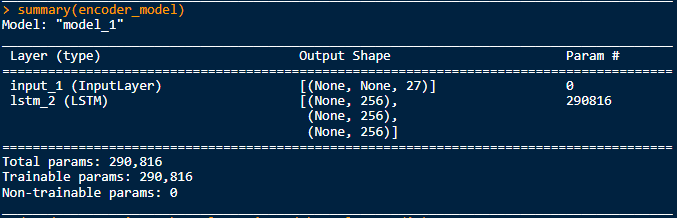
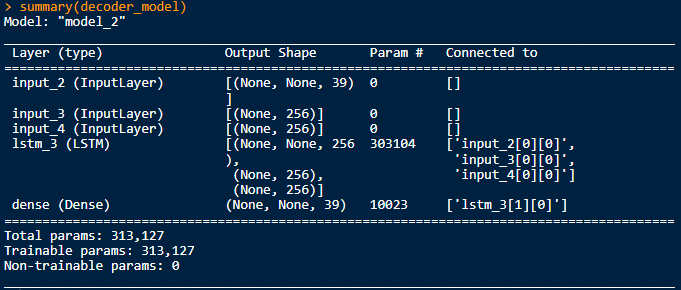
看起来,“主”模型包含编码器和解码器模型所需的所有形状和状态信息。如何从主模型中提取编码器模型?解码器呢?
回答 1
Stack Overflow用户
发布于 2022-11-13 15:38:03
要在经过训练的模型中获取层,可以使用函数get_layer。要获得输入,可以使用$input,对于输出,可以使用$output,如下所示:
> model
Model: "model"
__________________________________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==========================================================================================================================
input_1 (InputLayer) [(None, None, 37)] 0 []
input_2 (InputLayer) [(None, None, 29)] 0 []
lstm (LSTM) [(None, 256), 301056 ['input_1[0][0]']
(None, 256),
(None, 256)]
lstm_1 (LSTM) [(None, None, 256), 292864 ['input_2[0][0]',
(None, 256), 'lstm[0][1]',
(None, 256)] 'lstm[0][2]']
dense (Dense) (None, None, 29) 7453 ['lstm_1[0][0]']
==========================================================================================================================
Total params: 601,373
Trainable params: 601,373
Non-trainable params: 0
__________________________________________________________________________________________________________________________
> encoder_model
Model: "model_1"
__________________________________________________________________________________________________________________________
Layer (type) Output Shape Param #
==========================================================================================================================
input_1 (InputLayer) [(None, None, 37)] 0
lstm (LSTM) [(None, 256), 301056
(None, 256),
(None, 256)]
==========================================================================================================================
Total params: 301,056
Trainable params: 301,056
Non-trainable params: 0
__________________________________________________________________________________________________________________________使用get_layer的代码
> # encoder model
> keras_model(inputs = get_layer(model, 'input_1')$input,
+ outputs = get_layer(model, 'lstm')$output)
Model: "model_15"
__________________________________________________________________________________________________________________________
Layer (type) Output Shape Param #
==========================================================================================================================
input_1 (InputLayer) [(None, None, 37)] 0
lstm (LSTM) [(None, 256), 301056
(None, 256),
(None, 256)]
==========================================================================================================================
Total params: 301,056
Trainable params: 301,056
Non-trainable params: 0
__________________________________________________________________________________________________________________________https://stackoverflow.com/questions/74376974
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号