
来自tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))的NaN
我正在用resnet50作为编码器进行图像分割,并在tensorflow中用跳过层的解池层来制作解码器。
这是模型结构,
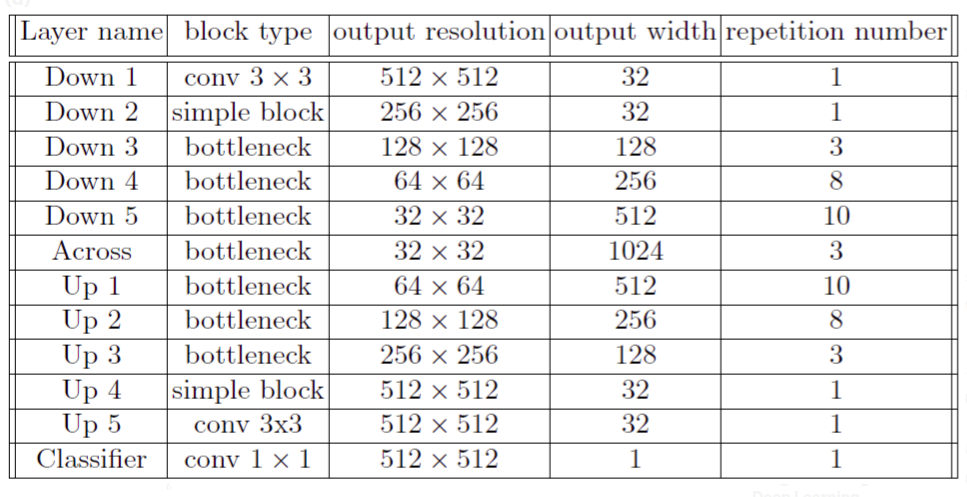
对于损失函数,我使用dice_coefficient和IOU公式,并将两者相加计算总损失。除了总损失外,我还从网络中添加了REGULARIZATION_LOSSES。
total_loss = tf.add_n([dice_coefficient_output+IOU_output]+tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES))
训练开始,在第一阶段,总损失在0.4左右,而在第二阶段,总损失显示为nan it。
在解码丢失值之后,tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)有每个层的值列表,在大多数层中,返回nan。
对于这个挑战,我尝试使用不同的标准化方法,比如缩放图像数据=0到1,-1比1,z-得分,但是nan出现在第二个时代。
我试图降低学习速度,改变l2 regularization中的重量衰减,但nan从第二个时代起保持不变。
最后,我减少了神经网络中的神经元,并开始训练,nan在第二个时期消失,而在第四个时期出现。
任何改进这个模型的建议,如何摆脱nan中的regularization_loss
谢谢
回答 1
Stack Overflow用户
发布于 2022-11-06 18:32:37
有两种可能的解决办法:
- 您可能对输入数据有问题。尝试在输入数据上调用assert np.any(np.isnan(x)),以确保您没有引入nan。还要确保所有目标值都是有效的。最后,确保数据是正确规范化的。您可能希望在-1,1,而不是0,255的范围内有像素,例如:
。
tf.keras.utils.normalize(data)
上面提到的其他相关选项是,通常情况下,渐变首先变成NaN。要看的前两件事是学习率降低和可能的梯度剪裁。
或者,您可以尝试先除以某个常量(可能等于数据的最大值?)这样做的目的是让这些值足够低,这样它们就不会产生很大的梯度。
- 标签必须在丢失函数的域中,所以如果使用基于对数的损失函数,所有标签都必须是非负的。
我见过很多东西使模特们产生了分歧。
学习率太高了。如果损失开始增加,然后发散到无穷大,你通常可以判断是否是这样。
我猜你的分类器使用了分类交叉熵代价函数。这涉及到获取预测的日志,当预测接近于零时,预测就会发散。这就是为什么人们通常在预测中增加一个小的epsilon值来防止这种差异。我猜RESNET可能会这样做,或者使用tensorflow选项。可能不是问题所在。
其他数值稳定性问题可能存在,如除以零,其中添加epsilon可以帮助。另一个不太明显的问题是,如果其导数可以发散的平方根,如果在处理有限精度数时不能适当地简化。我再一次怀疑这是分类器的问题。
输入数据可能有问题。尝试在输入数据上调用assert np.any(np.isnan(x)),以确保您没有引入nan。还要确保所有目标值都是有效的。最后,确保数据是正确规范化的。您可能希望在-1,1,而不是0,255范围内的像素。
否则,请参阅此链接:https://discuss.pytorch.org/t/getting-nan-after-first-iteration-with-custom-loss/25929/7
理解必须在丢失函数域中的标签的域适配:
https://stackoverflow.com/questions/74338536
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号