
几个模型估计表-重新排列列和行(包括reprex)
几个模型估计表-重新排列列和行(包括reprex)
提问于 2022-11-01 05:29:57
我正在从几个模型中创建一个回归估计表。以下是数据:
structure(list(term = c("age_ceo_state__rf", "", "mktrf", "",
NA, NA), intercept = c("0.390***", "(19.455)", "0.673***", "(23.409)",
NA, NA), term_2 = c("age_ceo_state__rf", "", "age_firm_state__rf",
"", "mktrf", ""), intercept_2 = c("0.209***", "(9.449)", "0.405***",
"(15.511)", "0.417***", "(13.255)"), term_3 = c("age_ceo_state__rf",
"", "age_firm_state__rf", "", "mktrf", ""), intercept_3 = c("0.209***",
"(9.449)", "0.405***", "(15.511)", "0.417***", "(13.255)")), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -6L))现在的情况如下:
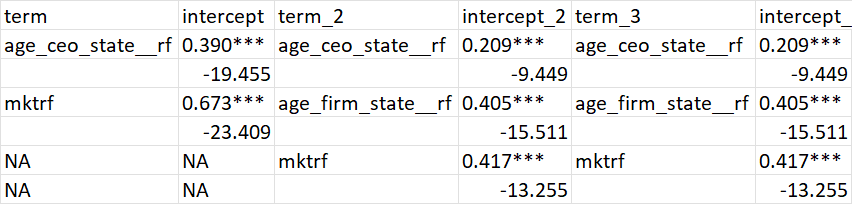
和目标表:
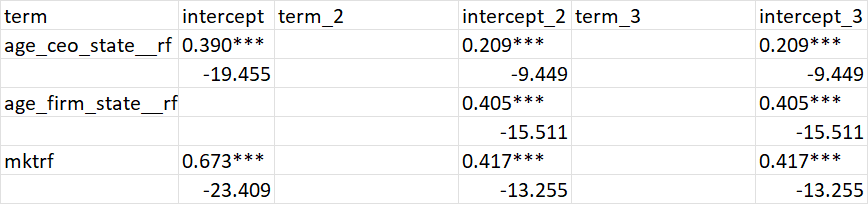
是的,项2和项3系数是相同的,即使它是一个不同的模型。我正在寻找一种编程方法来选择最完整的术语集,将它们移动到term 1列(注意术语更改的顺序),并将缺失的单元格设置为空白。这是一种常见的布局,很多回归报告包都使用这种布局;我无法用优雅和灵活的方式来移动这些术语。尽管这个问题没有直接涉及到modelsummary,但是作者可能对如何处理这个问题有深入的见解,但是很抱歉在回归表的R中标记了一个了不起的包。
回答 1
Stack Overflow用户
发布于 2022-11-01 06:16:38
这个相当笨拙。但我想你是在找这样的东西?
library(dplyr)
library(tidyr)
df %>%
mutate(id =as.integer(gl(n(),2,n()))) %>%
pivot_longer(starts_with("term")) %>%
group_by(id) %>%
add_count(value) %>%
mutate(x = value[n=max(n)]) %>%
ungroup() %>%
mutate(id1 =as.integer(gl(n(),max(id),n()))) %>%
group_by(id, id1) %>%
dplyr::slice(1) %>%
mutate(name = paste(name, id, sep="_")) %>%
ungroup() %>%
group_by(name) %>%
mutate(term = ifelse(row_number() == 2, NA_character_, x), .before=1) %>%
ungroup() %>%
select(-c(id, id1, value, n, name, x)) term intercept intercept_2 intercept_3
<chr> <chr> <chr> <chr>
1 age_ceo_state__rf 0.390*** 0.209*** 0.209***
2 NA (19.455) (9.449) (9.449)
3 age_firm_state__rf 0.673*** 0.405*** 0.405***
4 NA (23.409) (15.511) (15.511)
5 mktrf NA 0.417*** 0.417***
6 NA NA (13.255) (13.255)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74271887
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号