
在R中成对数据的两列中按匹配条件创建一个新列
在R中成对数据的两列中按匹配条件创建一个新列
提问于 2022-08-24 21:30:48
为了总结数据,我尝试用条件词创建一个新列,以匹配两个具有相同因素的列。
这就是数据文件的外观。

这就是我想总结的
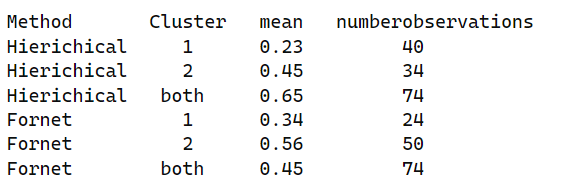
这是我提议的不起作用的代码:
probe$Cluster<-"cluster"
for (i in 1:length(probe)){
if(is.na(probe[i,4])){
probe[i,9]<-probe[i,6]}
if(is.na(probe[i,6])){
probe[i,9]<-probe[i,4]}
if(identical(probe[i,4],probe[i,6])){
probe[i,9]<-probe[i,4]}}
if(!identical(probe[i,4],probe[i,6])){
probe[i,9]<-probe[i,4]
rep(probe[i,1:9]%>%probe[i,9]<-probe[i,6}
#Then create a summary of this like this:
Sum<-probe%>%group_by(Method,Cluster)%>% summarise(mean(relation, na.rm
=FALSE),numberobservations=length(unique(GenA)))%>%data.frame()谢谢你的建议
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-08-24 21:38:31
如果没有我可以加载的样本数据(不需要重新输入图片),就无法进行验证,但是看起来您需要这样做:
library(dplyr)
probe %>%
mutate(Cluster = coalesce(ClusterA, ClusterB) %>% # use 1st non-NA from cols
group_by(Method, Cluster) %>%
summarize(mean = mean(relation, na.rm = TRUE),
numberobservations = n(), .groups = "drop")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73479670
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号