
双DQN的表现明显差于香草DQN
我有一个代理必须探索一个定制的环境。
环境是一个网格(水平100个方格,垂直100个方格,每个方格10米宽)。
在环境中,有许多用户(称为ue),他们的位置在每一集开始时都是随机的,并且在整个事件中是静止的。
每个用户需要的资源数量取决于代理的位置(代理与用户的距离越近,所需的资源就越少,越满意,用户的满意度就取决于给了它所需的资源的数量,如果它得到了所需的所有资源,那么它就会满足),因此代理必须找到满足最大用户数量的位置(代理不知道用户的位置)。
状态空间包含代理的当前位置、满意的用户数量和请求列表(每个用户所要求的资源类型)。
动作空间由9个动作组成(向前、向后、向两边、原地不动等)。
药物的位置在每一集开始时都是随机的。
在550集中,Epsilon从1下降到0.1。
奖励职能如下:
- 如果代理选择的操作使其所处的位置满足的用户比以前的位置更多,或者该代理选择的操作使其所处的位置满足与前一位置相同的用户数量,并且没有一个代理满足当前位置更多用户的位置,则那么奖励就会有价值2。如果代理选择了一个操作,使其达到与前一个位置相同的用户数量,而之前的位置上,代理满足的用户比当前位置更多,那么惩罚将是-0.001。如果代理选择了一个操作,使其所处的位置能够满足比前一个位置更少的用户,那么惩罚将是-0.002。
我用tau=1e-3在代码中使用目标网络的软更新。
我的问题是,双DQN的表现似乎比香草DQN差得多,我不知道为什么。应该表现得更好对吧?奖励函数有什么问题吗?还是我做错了什么?
到目前为止,平均报酬曲线是这样的:
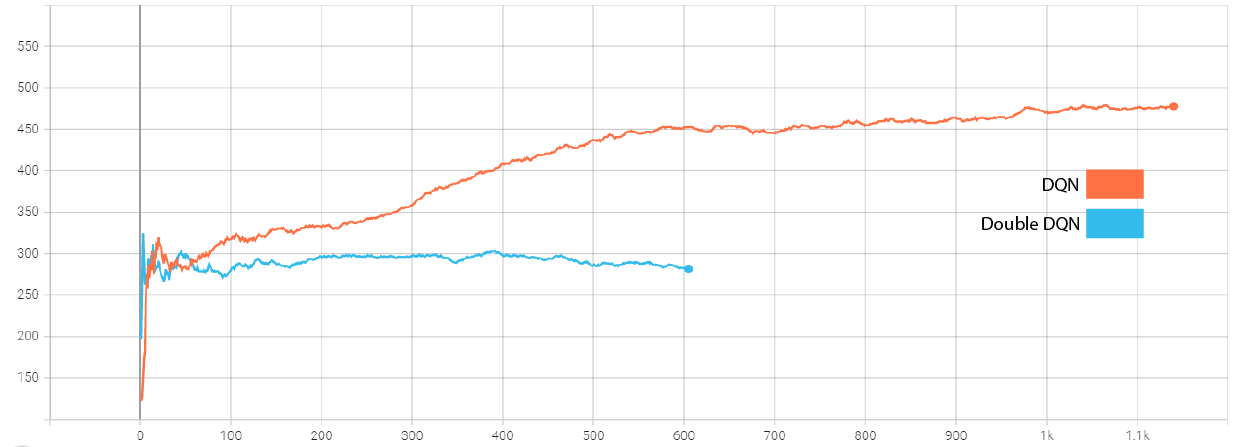
下面是我的双DQN代码:
DISCOUNT = 0.9 #0.99
REPLAY_MEMORY_SIZE = 10_000
MIN_REPLAY_MEMORY_SIZE = 10_000 # Minimum number of steps in a memory to start training
MINIBATCH_SIZE = 32 # How many steps (samples) to use for training
class DDQNAgent(object):
def __init__(self):
#self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_decay = 0.8
self.epsilon_min = 0.1
self.learning_rate = 10e-4 #0.0005 #0.25 #1e-4
self.tau = 1e-3
self.plot_loss_acc = PlotLearning()
# Main models
self.model_uav_pos = self._build_pos_model()
# Target networks
self.target_model_uav_pos = self._build_pos_model()
# Copy weights
self.target_model_uav_pos.set_weights(self.model_uav_pos.get_weights())
# An array with last n steps for training
self.replay_memory_pos_nn = deque(maxlen=REPLAY_MEMORY_SIZE)
tboard_log_dir_pos = os.path.join("logs", MODEL_NAME_POS_DDQN)
self.tensorboard_pos = ModifiedTensorBoard(MODEL_NAME_POS_DDQN, log_dir=tboard_log_dir_pos)
def _build_pos_model(self): # compile the DNN
# create the DNN model
dnn = self.create_pos_dnn()
opt = Adam(learning_rate=self.learning_rate) #, decay=self.epsilon_decay)
dnn.compile(loss="categorical_crossentropy", optimizer=opt, metrics=['accuracy'])
dnn.call = tf.function(dnn.call, jit_compile=True)
return dnn
''' Don't forget to normalize the inputs '''
def create_pos_dnn(self):
# initialize the input shape (The shape of an array is the number of elements in each dimension)
pos_input_shape = (2,)
requests_input_shape = (len(env.ues),)
number_of_satisfied_ues_input_shape = (1,)
# How many possible outputs we can have
output_nodes = n_possible_movements
# Initialize the inputs
uav_current_position = Input(shape=pos_input_shape, name='pos')
ues_requests = Input(shape=requests_input_shape, name='requests')
number_of_satisfied_ues = Input(shape=number_of_satisfied_ues_input_shape, name='number_of_satisfied_ues')
# Put them in a list
list_inputs = [uav_current_position, ues_requests, number_of_satisfied_ues]
# Merge all input features into a single large vector
x = layers.concatenate(list_inputs)
# Add a 1st Hidden (Dense) Layer
dense_layer_1 = Dense(512, activation="relu")(x)
# Add a 2nd Hidden (Dense) Layer
dense_layer_2 = Dense(512, activation="relu")(dense_layer_1)
# Add a 3rd Hidden (Dense) Layer
dense_layer_3 = Dense(256, activation="relu")(dense_layer_2)
# Output layer
output_layer = Dense(output_nodes, activation="softmax")(dense_layer_3)
model = Model(inputs=list_inputs, outputs=output_layer)
# return the DNN
return model
def remember_pos_nn(self, state, action, reward, next_state, done):
self.replay_memory_pos_nn.append((state, action, reward, next_state, done)) # list of previous experiences, enabling re-training later
def act_upon_choosing_a_new_position(self, state): # state is a tuple (uav_position, requests_array)
if np.random.rand() <= self.epsilon: # if acting randomly, take random action
return random.randrange(n_possible_movements)
pos = np.array([state[0]])
reqs = np.array([state[1]])
number_satisfaction = np.array([state[2]])
act_values = self.model_uav_pos([pos, reqs, number_satisfaction]) # if not acting randomly, predict reward value based on current state
return np.argmax(act_values[0]) #env.possible_positions[np.argmax(act_values[0])] # pick the action that will give the highest reward
def train_pos_nn(self):
print("In Training..")
# Start training only if certain number of samples is already saved
if len(self.replay_memory_pos_nn) < MIN_REPLAY_MEMORY_SIZE:
print("Exiting Training: Replay Memory Not Full Enough...")
return
# Get a minibatch of random samples from memory replay table
list_memory = list(self.replay_memory_pos_nn)
random.shuffle(list_memory)
minibatch = random.sample(list_memory, MINIBATCH_SIZE)
start_time = time.time()
# Enumerate our batches
for index, (current_state, action, reward, new_current_state, done) in enumerate(minibatch):
print('...Starting Training...')
target = 0
pos = np.array([current_state[0]])
reqs = np.array([current_state[1]])
number_satisfaction = np.array([current_state[2]])
pos_next = np.array([new_current_state[0]])
reqs_next = np.array([new_current_state[1]])
number_satisfaction_next = np.array([new_current_state[2]])
# If not a terminal state, get new q from future states, otherwise set it to 0
# almost like with Q Learning, but we use just part of equation here
if not done:
max_action = np.argmax(self.model_uav_pos([pos_next, reqs_next, number_satisfaction_next])[0])
target = reward + DISCOUNT * self.target_model_uav_pos([pos_next, reqs_next, number_satisfaction_next])[0][max_action]
else:
target = reward
# Update Q value for a given state
target_f = self.model_uav_pos([pos, reqs, number_satisfaction])
target_f = np.array(target_f)
target_f[0][action] = target
self.model_uav_pos.fit([pos, reqs, number_satisfaction], \
target_f, \
verbose=2, \
shuffle=False, \
callbacks=None, \
epochs=1 \
)
end_time = time.time()
print("Time", end_time - start_time)
# Update target network counter every episode
self.target_train()
def target_train(self):
weights = self.model_uav_pos.get_weights()
target_weights = self.target_model_uav_pos.get_weights()
for i in range(len(target_weights)):
target_weights[i] = weights[i] * self.tau + target_weights[i] * (1 - self.tau)
self.target_model_uav_pos.set_weights(target_weights)回答 1
Stack Overflow用户
发布于 2022-07-29 17:20:50
DDQN的性能可能比DQN差,原因可能很多。我可以在这里列举几个-
- 深层神经网络高度依赖于权值初始化。为了对两种算法进行适当的比较,您需要放置种子,以便权值初始化是相同的。
美联储(
- )也可以这么说,即奉行贪婪的政策。采取随机行动,在随机的时间步骤将导致您获得不同的奖励,这可能影响未来的政策。
- τ是一个需要调优的超参数。取决于对τ使用的值,您可以从DDQN.
得到不同的结果。
我相信如果您添加一些工作代码,您可以从SO社区获得更多的帮助,这是可以测试出来的。例如,健身房https://www.gymlibrary.ml/有许多标准和简单的环境,例如Cart极板,可以用于快速(<5分钟)代码原型开发。
https://stackoverflow.com/questions/73137635
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号