
如何检查我的模型是否过分适合与许多时代的训练。
我正在用100个时代来训练我的tensorflow model。
history = model.fit(..., steps_per_epoch=600, ..., epochs=100, ...)下面是在7/100上进行培训时的输出
Epoch 1/100
600/600 [==============================] - ETA: 0s - loss: 0.1443 - rmse: 0.3799
Epoch 1: val_loss improved from inf to 0.14689, saving model to saved_model/my_model
2022-06-20 20:25:11.552250: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: saved_model/my_model/assets
600/600 [==============================] - 367s 608ms/step - loss: 0.1443 - rmse: 0.3799 - val_loss: 0.1469 - val_rmse: 0.3833
Epoch 2/100
600/600 [==============================] - ETA: 0s - loss: 0.1470 - rmse: 0.3834
Epoch 2: val_loss did not improve from 0.14689
600/600 [==============================] - 357s 594ms/step - loss: 0.1470 - rmse: 0.3834 - val_loss: 0.1559 - val_rmse: 0.3948
Epoch 3/100
600/600 [==============================] - ETA: 0s - loss: 0.1448 - rmse: 0.3805
Epoch 3: val_loss did not improve from 0.14689
600/600 [==============================] - 341s 569ms/step - loss: 0.1448 - rmse: 0.3805 - val_loss: 0.1634 - val_rmse: 0.4042
Epoch 4/100
600/600 [==============================] - ETA: 0s - loss: 0.1442 - rmse: 0.3798
Epoch 4: val_loss did not improve from 0.14689
600/600 [==============================] - 359s 599ms/step - loss: 0.1442 - rmse: 0.3798 - val_loss: 0.1529 - val_rmse: 0.3910
Epoch 5/100
600/600 [==============================] - ETA: 0s - loss: 0.1461 - rmse: 0.3822
Epoch 5: val_loss did not improve from 0.14689
600/600 [==============================] - 358s 596ms/step - loss: 0.1461 - rmse: 0.3822 - val_loss: 0.1493 - val_rmse: 0.3864
Epoch 6/100
600/600 [==============================] - ETA: 0s - loss: 0.1463 - rmse: 0.3825
Epoch 6: val_loss improved from 0.14689 to 0.14637, saving model to saved_model/my_model
INFO:tensorflow:Assets written to: saved_model/my_model/assets
600/600 [==============================] - 368s 613ms/step - loss: 0.1463 - rmse: 0.3825 - val_loss: 0.1464 - val_rmse: 0.3826
Epoch 7/100
324/600 [===============>..............] - ETA: 2:35 - loss: 0.1434 - rmse: 0.3786"Epoch 2/100“表示"val_loss: 0.1559" > "loss: 0.1470”
Epoch 2/100
600/600 [==============================] - ETA: 0s - loss: 0.1470 - rmse: 0.3834
Epoch 2: val_loss did not improve from 0.14689
600/600 [==============================] - 357s 594ms/step - loss: 0.1470 - rmse: 0.3834 - val_loss: 0.1559 - val_rmse: 0.3948基于这个StackOverflow链接,上面写着"validation loss > training loss you can call it some overfitting":
Training Loss and Validation Loss in Deep Learning
If validation loss >> training loss you can call it overfitting.
If validation loss > training loss you can call it some overfitting.
If validation loss < training loss you can call it some underfitting.
If validation loss << training loss you can call it underfitting.那么,我的模型overfitting是在"Epoch 2/100“上吗?如果是,为什么“6/100时代”仍然显示"Epoch 6: val_loss improved from 0.14689 to 0.14637, saving model to saved_model/my_model"?
回答 2
Stack Overflow用户
发布于 2022-06-20 13:32:57
您可以绘制training_data和validation_data在培训结束时保存在history中的损失,并在进入overfitting或underfitting时进行检查。
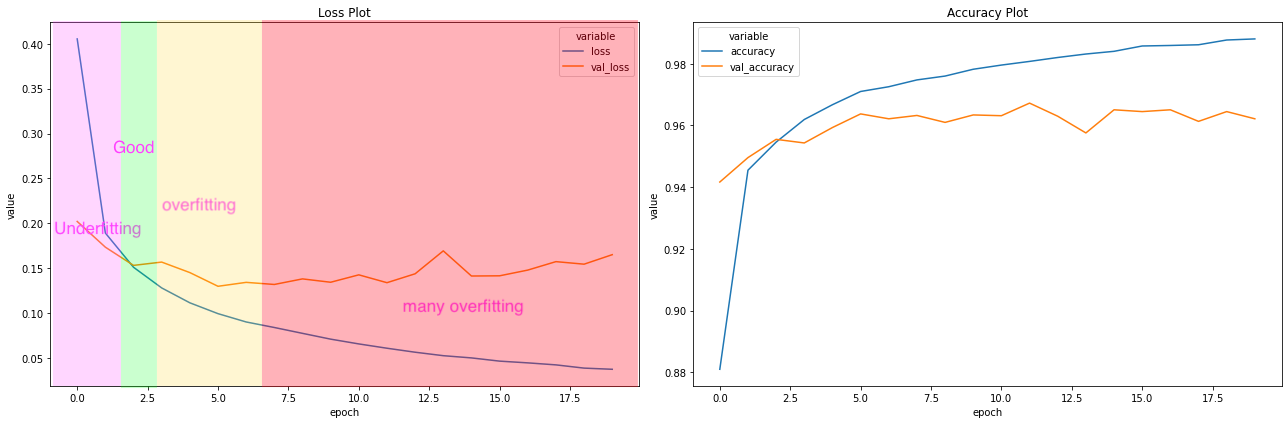
检查和绘制代码:
import matplotlib.pyplot as plt
import tensorflow as tf
import seaborn as sns
import pandas as pd
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1, 784).astype("float32") / 255
x_test = x_test.reshape(-1, 784).astype("float32") / 255
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
model = tf.keras.Sequential()
model.add(tf.keras.Input(shape=(784,)))
model.add(tf.keras.layers.Dense(32, activation='relu'))
model.add(tf.keras.layers.Dense(16, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer = 'adam',
loss ='categorical_crossentropy',metrics=['accuracy'],)
history = model.fit(x_train, y_train, epochs=20, batch_size=32, validation_split=0.2)
df = pd.DataFrame(history.history).rename_axis('epoch').reset_index().melt(id_vars=['epoch'])
fig, axes = plt.subplots(1,2, figsize=(18,6))
for ax, mtr in zip(axes.flat, ['loss', 'accuracy']):
ax.set_title(f'{mtr.title()} Plot')
dfTmp = df[df['variable'].str.contains(mtr)]
sns.lineplot(data=dfTmp, x='epoch', y='value', hue='variable', ax=ax)
fig.tight_layout()
plt.show()输出:
Stack Overflow用户
发布于 2022-06-20 13:39:55
在我看来,“过度拟合”的唯一信号是,您的验证损失开始增加,而火车损失仍在减少,而不是“验证损失>>培训损失”。
https://stackoverflow.com/questions/72687607
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号