
联邦学习中的不平衡客户端规模
我正在应用联邦学习对多个文件使用。问题是,每个文件中的数据大小(记录数)是不同的。
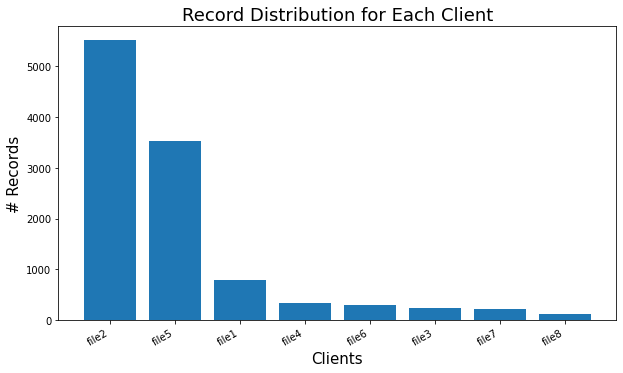
- 在联邦学习培训中,是否存在针对每个客户的不同规模的问题?如果我有办法克服它呢?
- 有什么方法可以让我看到每个客户端在联合计算培训时的表现吗?
回答 1
Stack Overflow用户
发布于 2022-06-03 18:30:19
在联邦学习培训中,是否存在针对每个客户的不同规模的问题?如果我有办法克服它呢?
这取决于各种因素,其中一个很大的因素是客户端上的数据分布。例如,如果每个客户端数据看起来非常相似(例如,实际上相同的分布,IID),那么使用哪个客户端并不特别重要。
如果不是这样,一种常见的技术是限制客户端每一轮对其数据集采取的最大步骤数,以促进更平等地参与培训过程。在TensorFlow和TFF中,可以使用tf.data.Dataset.take来限制最大迭代次数。在TFF中,这可以应用于使用tff.simulation.datasets.ClientData.preprocess的每个客户端。这将通过教程使用TFF的ClientData中的示例进行讨论。
有什么方法可以让我看到每个客户端在联合计算培训时的表现吗?
客户端可以返回单独的度量来报告它们的表现,但默认情况下不会这样做。在中,metrics_aggregator默认为tff.learning.metrics.sum_then_finalize,后者通常创建度量的全局平均值。没有开箱即用的解决方案,但我们可以实现一个“最终-然后-样本”,很可能满足这一需求。重用tff.aggregators.federated_sample并以源代码 for sum_then_finalize为例将是一个很好的起点。
https://stackoverflow.com/questions/72467705
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号