
使用CUDF数据CUDF的列表操作
我有一个Cudf dataframe,它看起来像这样
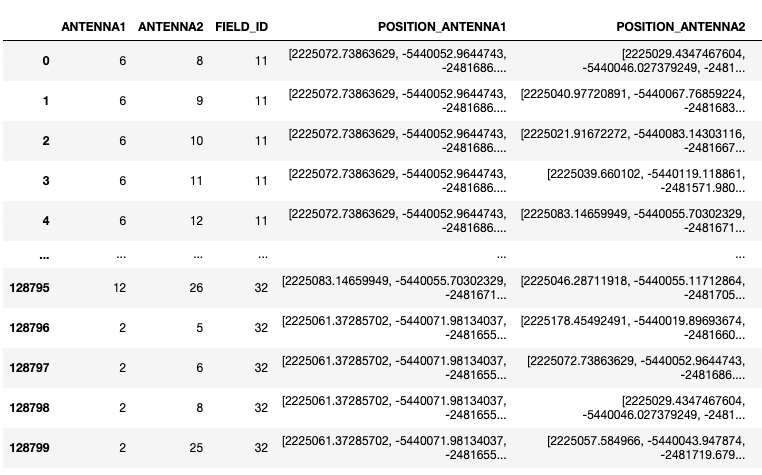
列POSITION_ANTENNA1和POSITION_ANTENNA2的d类型是列表,我希望构造一个列= POSITION_ANTENNA1 - POSITION_ANTENNA2.然而,这给了我一个错误。
Lists concatenation for this operation is not yetsupported
但是,如果我正在将数据转换为Pandas,那么它工作得很好。有没有办法做简单的列表操作,而不把它转换成熊猫。
编辑:
这是我要做的手术
df_merged['BASELINE'] = df_merged.POSITION_ANTENNA1-df_merged.POSITION_ANTENNA2我得到了这个错误

但是,如果我做了以下操作,它就可以正常工作了。
df_merged['BASELINE'] = df_merged.POSITION_ANTENNA1.to_pandas()-df_merged.POSITION_ANTENNA2.to_pandas()回答 2
Stack Overflow用户
发布于 2022-05-25 15:52:37
如果不访问示例数据,这个问题很难可靠地解决,但是下面的代码片段应该是适应实际用例的良好起点。
作为一般建议,我建议首先使用pandas解决一个较小的问题(因为dask和cudf都提供了对熊猫数据进行操作的能力):
from pandas import DataFrame, concat
df = DataFrame({"a": [[1, 2], [3, 4]], "b": [[5, 7], [9, 11]]})
def calculate_difference(df):
# create dfs using https://stackoverflow.com/a/35491399/10693596
_a = DataFrame(df["a"].tolist(), columns=["0", "1"], index=df.index)
_b = DataFrame(df["b"].tolist(), columns=["0", "1"], index=df.index)
_diff = _a - _b
return concat([df, _diff], axis=1)
print(calculate_difference(df))
# a b 0 1
# 0 [1, 2] [5, 7] -4 -5
# 1 [3, 4] [9, 11] -6 -7在该函数中,我们首先依靠this answer将数据转换为具有一致索引的列,然后找出列值的差异。
假设上面的结果生成了所需的结果,我们可以跨数据块映射函数(因为操作是按行执行的,因此不需要跨分区进行数据交换):
from dask.dataframe import from_pandas
# will use the pandas example to provide meta (highly recommended)
meta = calculate_difference(df)
ddf = from_pandas(df, npartitions=1)
ddf = ddf.map_partitions(calculate_difference, meta=meta)
print(ddf.compute())
# a b 0 1
# 0 [1, 2] [5, 7] -4 -5
# 1 [3, 4] [9, 11] -6 -7对于dask cudf,您可以将dask cudf转换为dask dataframe:
from dask_cudf import from_cudf
# assuming df is a cudf dataframe
ddf = from_cudf(df, npartitions=2)
# will use the pandas example to provide meta (highly recommended)
meta = calculate_difference(df.head(3))
ddf = ddf.map_partitions(calculate_difference, meta=meta)Stack Overflow用户
发布于 2022-07-01 23:59:57
SultanOrazbayev是对的(+1ed):您不能用在dataframe中格式化数据的方式来做您想做的事情。就我个人而言,我会将POSITION_ANTENNA1和POSITION_ANTENNA2分解成两个独立的数据文件,对两个不同的数据执行减法操作,然后将结果放入您想要的cudf数据帧中,并删除两个天线数据帧作为空间。
请在cuDF中提出一个功能请求,这样我们就可以跟踪和优先考虑这一使用。
https://stackoverflow.com/questions/72379710
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号