
我正在使用dask数据文件读取相当大的csv文件。我想从df中提取一些特定的列,对此有什么方法吗?
我正在使用dask数据文件读取相当大的csv文件。我想从df中提取一些特定的列,对此有什么方法吗?
提问于 2022-05-09 07:45:20
我有大约3GB大的csv文件,我想阅读它与达克。我想对这个数据执行一个操作,就是选择一些包含特定数据的列。
例如:
我想得到df中的所有I。
ids = ['SW00003062', 'SW00003063', 'SW00003067', 'SW00003072']从这个达斯克数据中心:
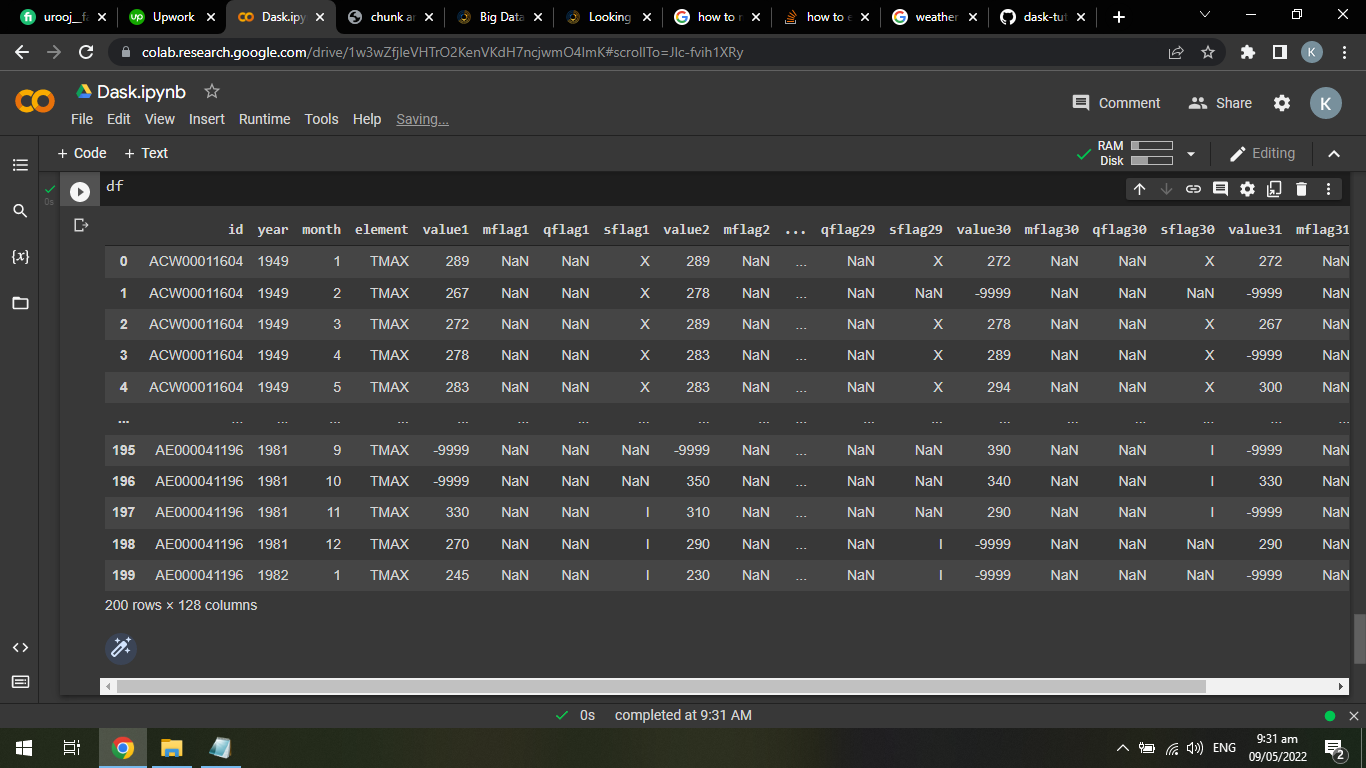
只需获取包含id列表id的dataframe
回答 2
Stack Overflow用户
发布于 2022-05-09 09:21:30
这个怎么样?
import pandas
random_name = pandas.read_csv("insert file name")
random_name["column title"] #this should give you your column of choice
list = random name["column title"].to_list() #turns column to listStack Overflow用户
发布于 2022-05-09 10:40:36
达斯克的语法与熊猫非常相似,这意味着大多数熊猫指令都得到了支持。对于您的需求,您可以执行以下操作:
df = pd.DataFrame(
{
'size': random.random(size=100),
'label': random.choice(['a', 'b', 'c'], size=100, replace=True)
}
)
dask_df = dd.from_pandas(df, npartitions=2)
# to get the unique values from a column
dask_df.label.unique().compute()
# to index a column based on condition
dask_df.loc[dask_df.label == 'a', :].compute()注意,dask将一个操作存储为一个task,要实际执行这些任务,就必须对表达式调用compute()函数。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72168550
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号