
如何从脑电信号中提取ICA成分?
我跟踪这个问题的答案和本科学学习教程来去除脑电信号中的伪影。它们看起来很简单,我在这里肯定遗漏了一些显而易见的东西。
提取的成分和我的信号长度不一样。我有88个频道的几个小时的录音,所以我的信号矩阵的形状是( 88,8088516)。而ICA的输出为(88,88)。除了如此短,每个组件似乎捕捉非常大,噪音-外观偏转(因此,在88个组件中,只有一对实际上看起来像信号,其余看起来像噪音)。我还希望只有几个部件看起来很吵。我怀疑我在这里做了什么错事?
(通道x样品)的矩阵具有形状(88,8088516)。
示例代码(仅为最低工作目的使用随机矩阵):
import numpy as np
from sklearn.decomposition import FastICA
import matplotlib.pyplot as plt
samples_matrix = np.random.random((88, 8088516))
# Compute ICA
ica = FastICA(n_components=samples_matrix.shape[0]) # Extracting as many components as there are channels, i.e. 88
components = ica.fit_transform(samples_matrix) # Reconstruct signals
A_ = ica.mixing_ # Get estimated mixing matrix元件的形状为(88,88)。其中一幅图是这样的:
plt.plot(components[1])
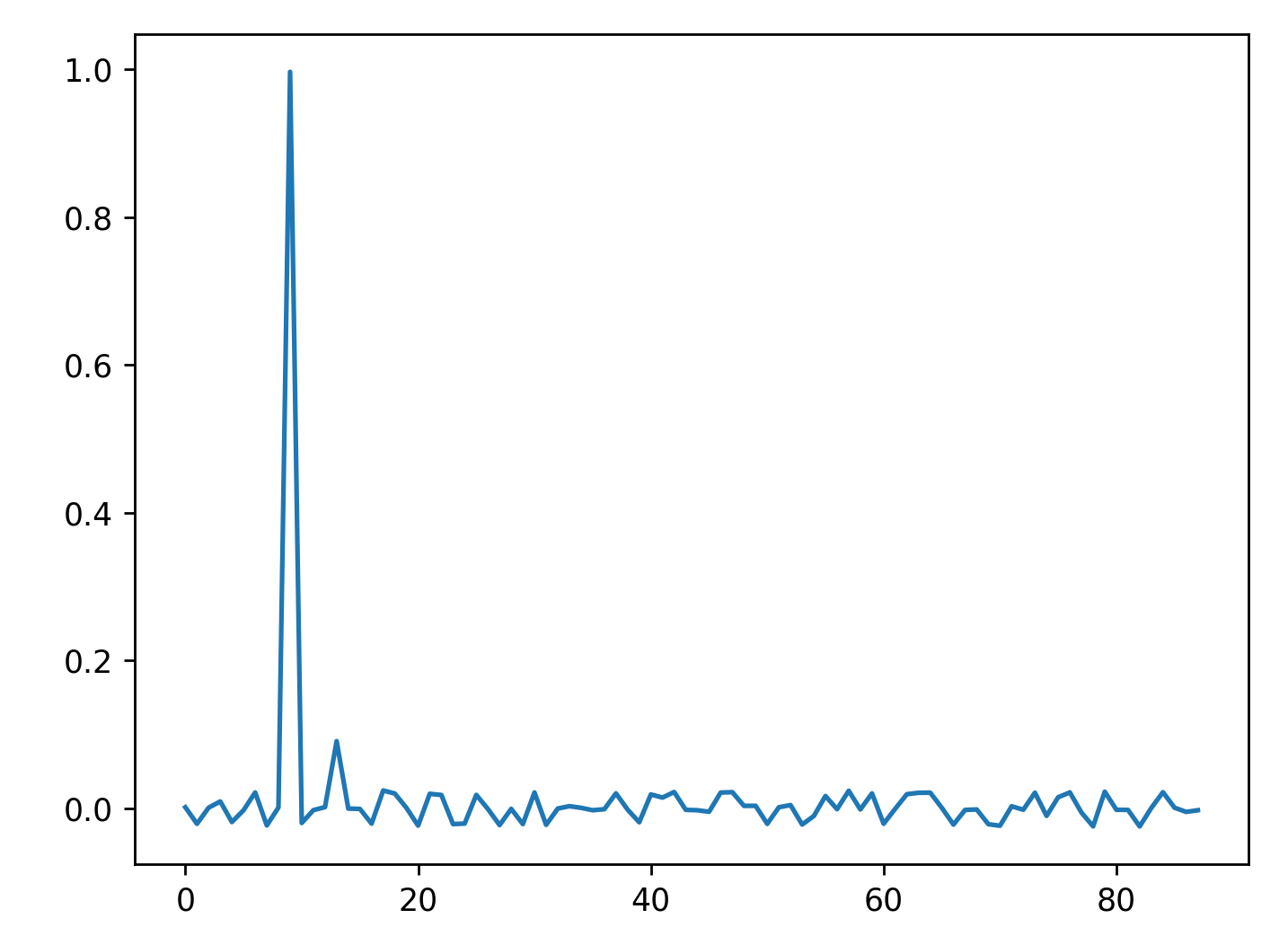
我原以为这些组件是与我原来的如这个问题的答案所示相同长度的时间序列。我真的不知道如何在这一点上推进组件去除和信号重建。
回答 1
Stack Overflow用户
发布于 2022-03-23 09:09:46
您需要在转置的fit_transform上运行samples_matrix,而不是samples_matrix本身(因此向方法提供一个8088516 x 88矩阵,而不是88x8088516 )。
ica.fit_transform(samples_matrix.transpose())或者更简单
ica.fit_transform(samples_matrix.T)这将给你一套8088516×88的信号(88个分量,每个信号只要原始信号)进行绘图。正如我在下面的评论中提到的,由于大矩阵反转等原因,我的设置建议最多不超过64个组件。
为了支持这个建议,我看了一下你的教程,他们设置了玩具问题如下:
n_samples = 2000
time = np.linspace(0, 8, n_samples)
s1 = np.sin(2 * time) # Signal 1 : sinusoidal signal
s2 = np.sign(np.sin(3 * time)) # Signal 2 : square signal
s3 = signal.sawtooth(2 * np.pi * time) # Signal 3: saw tooth signal
S = np.c_[s1, s2, s3]
S += 0.2 * np.random.normal(size=S.shape) # Add noise
S /= S.std(axis=0) # Standardize data
# Mix data
A = np.array([[1, 1, 1], [0.5, 2, 1.0], [1.5, 1.0, 2.0]]) # Mixing matrix
X = np.dot(S, A.T) # Generate observations它给出了一个X.shape of (2000,3)来分离这3个组件,表明这是FastICA方法的首选矩阵格式。
https://stackoverflow.com/questions/71583770
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号