
将曲线拟合成某些数据点
拟合曲线不符合预期的数据点(xH_data,nH_data)。有人知道这里有什么问题吗?
from scipy.optimize import curve_fit
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
xH_data = np.array([1., 1.03, 1.06, 1.1, 1.2, 1.3, 1.5, 1.7, 2., 2.6, 3., 4., 5., 6.])
nH_data = np.array([403., 316., 235., 160., 70.8, 37.6, 14.8, 7.11, 2.81, 0.665, 0.313, 0.090, 0.044, 0.029])*1.0e6
plt.plot(xH_data, nH_data)
plt.yscale("log")
plt.xscale("log")
def eTemp(x, A, a, B):
n = B*(A+x)**a
return n
parameters, covariance = curve_fit(eTemp, xH_data, nH_data, maxfev=200000)
fit_A = parameters[0]
fit_a = parameters[1]
fit_B = parameters[2]
print(fit_A)
print(fit_a)
print(fit_B)
r = np.logspace(0, 0.7, 1000)
ne = fit_B *(fit_A + r)**(fit_a)
plt.plot(r, ne)
plt.yscale("log")
plt.xscale("log")提前谢谢你的帮助。
回答 4
Stack Overflow用户
发布于 2022-03-11 07:13:25
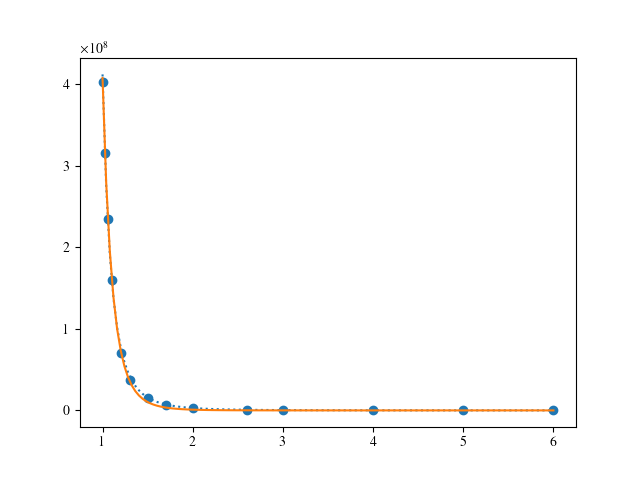
好的,这里有一个不同的方法。与往常一样,主要问题是对非线性拟合的初始猜测(关于细节,请检查这)。这里,用fit函数y( x ) = a ( x - c )^p,即int( y ) = ( x - c ) / ( p + 1 ) y + d = x y / ( p + 1 ) - c y / ( p + 1 ) + d的积分关系来求出它们,这意味着我们可以通过int y对x y和y的线性拟合得到c和p。一旦这些已知,a是一个简单的线性拟合。事实将证明,这些猜测已经相当不错了。然而,这些将作为初始值进入非线性拟合,提供最终的结果.详细地说,这是这样的:
import matplotlib.pyplot as plt
import numpy as np
from scipy.integrate import cumtrapz
from scipy.optimize import curve_fit
xHdata = np.array(
[
1.0, 1.03, 1.06, 1.1, 1.2, 1.3, 1.5,
1.7, 2.0, 2.6, 3.0, 4.0, 5.0, 6.0
]
)
nHdata = np.array(
[
403.0, 316.0, 235.0, 160.0, 70.8, 37.6,
14.8, 7.11, 2.81, 0.665, 0.313, 0.090, 0.044, 0.029
]
) * 1.0e6
def fit_func( x, a, c, p ):
out = a * ( x - c )**p
return out
### fitting the non-linear parameters as part of an integro-equation
### this is the standard matrix formulation of a linear fit
Sy = cumtrapz( nHdata, x=xHdata, initial=0 ) ## int( y )
VMXT = np.array( [ xHdata * nHdata , nHdata, np.ones( len( nHdata ) ) ] ) ## ( x y, y, d )
VMX = VMXT.transpose()
A = np.dot( VMXT, VMX )
SV = np.dot( VMXT, Sy )
sol = np.linalg.solve( A , SV )
print ( sol )
pF = 1 / sol[0] - 1
print( pF )
cF = -sol[1] * ( pF + 1 )
print( cF )
### making a linear fit on the scale
### the short version of the matrix form if only one factor is calculated
fk = fit_func( xHdata, 1, cF, pF )
aF = np.dot( nHdata, fk ) / np.dot( fk, fk )
print( aF )
#### using these guesses as input for a final non-linear fit
sol, cov = curve_fit(fit_func, xHdata, nHdata, p0=( aF, cF, pF ) )
print( sol )
print( cov )
### plotting
xth = np.linspace( 1, 6, 125 )
fig = plt.figure()
ax = fig.add_subplot( 1, 1, 1 )
ax.scatter( xHdata, nHdata )
ax.plot( xth, fit_func( xth, aF, cF, pF ), ls=':' )
ax.plot( xth, fit_func( xth, *sol ) )
plt.show()提供:
[-3.82334284e-01 2.51613126e-01 5.41522867e+07]
-3.6155122388787175
0.6580972107001803
8504146.59883185
[ 5.32486242e+07 2.44780953e-01 -7.24897172e+00]
[[ 1.03198712e+16 -2.71798924e+07 -2.37545914e+08]
[-2.71798924e+07 7.16072922e-02 6.26461373e-01]
[-2.37545914e+08 6.26461373e-01 5.49910325e+00]](注意a与c和p之间的高度相关性)和
Stack Overflow用户
发布于 2022-03-10 23:10:21
我知道有两件事可能对你有帮助
- 将
p0输入参数提供给curve_fit,并为函数提供一组合适的启动参数。这可以防止算法失控。 - 更改您要拟合的函数,使其返回
np.log(n),然后使其适合np.log(nH_data)。与现在一样,不拟合第一个数据点比不拟合最后一个数据点的惩罚要大得多,因为第一个数据点的值大约大10^2。因此,第一个数据点变得“更重要”,以适应该算法。取对数使它们更多地处于相同的尺度上,因此,对点数的加权是相等的。
继续玩吧。我对这些参数进行了很好的拟合。
[-7.21450545e-01 -3.36131028e+00 5.97293632e+06]Stack Overflow用户
发布于 2022-03-10 23:29:00
我想你就快到了,只要把它放进原木秤就行了,猜得不错。为了猜到你只需要加上一个情节
plt.figure()
plt.plot(np.log(xH_data), np.log(nH_data))你会发现它几乎是线性的。所以B是指数截距(即exp(20 5ish)),a是近似斜率(-5 5ish)。A是奇怪的,它是有物理意义,还是你只是把它扔进去了?如果没有物理意义的话,我会说把它处理掉。
from scipy.optimize import curve_fit
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
xH_data = np.array([1., 1.03, 1.06, 1.1, 1.2, 1.3, 1.5, 1.7, 2., 2.6, 3., 4., 5., 6.])
nH_data = np.array([403., 316., 235., 160., 70.8, 37.6, 14.8, 7.11, 2.81, 0.665, 0.313, 0.090, 0.044, 0.029])*1.0e6
def eTemp(x, A, a, B):
logn = np.log(B*(x + A)**a)
return logn
parameters, covariance = curve_fit(eTemp, xH_data, np.log(nH_data), p0=[np.exp(0.1), -5, np.exp(20)], maxfev=200000)
fit_A = parameters[0]
fit_a = parameters[1]
fit_B = parameters[2]
print(fit_A)
print(fit_a)
print(fit_B)
r = np.logspace(0, 0.7, 1000)
ne = np.exp(eTemp(r, fit_A, fit_a, fit_B))
plt.plot(xH_data, nH_data)
plt.plot(r, ne)
plt.yscale("log")
plt.xscale("log")https://stackoverflow.com/questions/71431511
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号