
如何提高python中多个csv文件的读取速度
如何提高python中多个csv文件的读取速度
提问于 2022-03-08 06:58:31
这是我第一次创建一个代码来处理包含大量数据的文件,所以我被困在这里了。
我要做的是读取路径列表,列出所有需要读取的csv文件,从每个文件中检索头尾,并将其放入列表中。
我总共有621个csv文件,每个文件由5800行和251列组成。
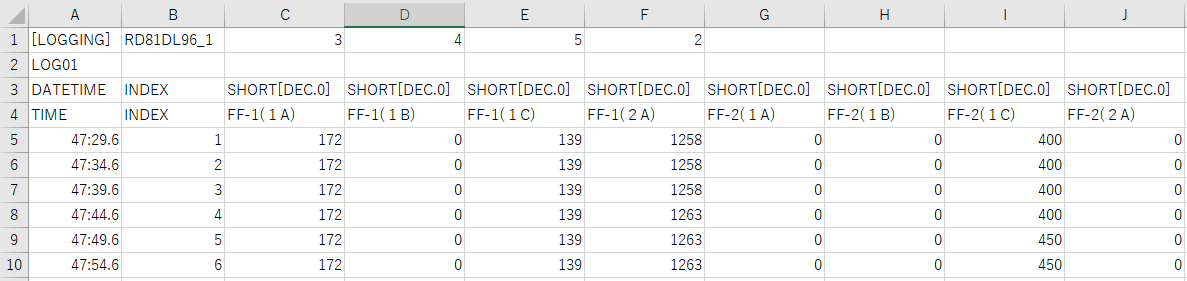
这是数据示例
[LOGGING],RD81DL96_1,3,4,5,2,,,,
LOG01,,,,,,,,,
DATETIME,INDEX,SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0],SHORT[DEC.0]
TIME,INDEX,FF-1(1A) ,FF-1(1B) ,FF-1(1C) ,FF-1(2A),FF-2(1A) ,FF-2(1B) ,FF-2(1C),FF-2(2A)
47:29.6,1,172,0,139,1258,0,0,400,0
47:34.6,2,172,0,139,1258,0,0,400,0
47:39.6,3,172,0,139,1258,0,0,400,0
47:44.6,4,172,0,139,1263,0,0,400,0
47:49.6,5,172,0,139,1263,0,0,450,0
47:54.6,6,172,0,139,1263,0,0,450,0问题是,虽然读取所有文件花了大约13秒(老实说,还是有点慢)。
但是当我添加一行附加代码时,这个过程花了很多时间才完成,大约4分钟。
下面的是代码的片段集:
# CsvList: [File Path, Change Date, File size, File Name]
for x, file in enumerate(CsvList):
timeColumn = ['TIME']
df = dd.read_csv(file[0], sep =',', skiprows = 3, encoding= 'CP932', engine='python', usecols=timeColumn)
# The process became long when this code is added
startEndList.append(list(df.head(1)) + list(df.tail(1))) 为什么会这样?我用的是dask.dataframe
回答 2
Stack Overflow用户
回答已采纳
发布于 2022-03-08 08:14:44
第一种方法只使用Python作为起点:
import pandas as pd
import io
def read_first_and_last_lines(filename):
with open(filename, 'rb') as fp:
# skip first 4 rows (headers)
[next(fp) for _ in range(4)]
# first line
first_line = fp.readline()
# start at -2x length of first line from the end of file
fp.seek(-2 * len(first_line), 2)
# last line
last_line = fp.readlines()[-1]
return first_line + last_line
data = []
for filename in pathlib.Path('data').glob('*.csv'):
data.append(read_first_and_last_lines(filename))
buf = io.BytesIO()
buf.writelines(data)
buf.seek(0)
df = pd.read_csv(buf, header=None, encoding='CP932')Stack Overflow用户
发布于 2022-03-08 10:07:10
目前,您的代码并没有真正利用Dask的并行化功能,因为:
df.head和df.tail调用将触发一个“计算”(也就是说,将您的Dask DataFrame转换为熊猫DataFrame --这就是我们在使用Dask进行懒惰评估时尽量减少的)。- for-循环是按顺序运行的,因为您正在创建Dask DataFrames并将它们转换为DataFrames,所有这些都在循环中。
因此,您当前的示例类似于仅在for-循环中使用熊猫,但是增加了从Dask到熊猫的转换开销。
由于您需要处理每个文件,我建议查看达克延迟,这里的elegant+ueful可能更多。以下(伪代码)将对您的每个文件并行处理熊猫操作:
import dask
import pandas as pd
for file in list_of_files:
df = dask.delayed(pd.read_csv)(file)
result.append(df.head(1) + df.tail(1))
dask.compute(*result)当我使用4个csv-文件时,dask.visualize(*result)的输出证实了并行性:
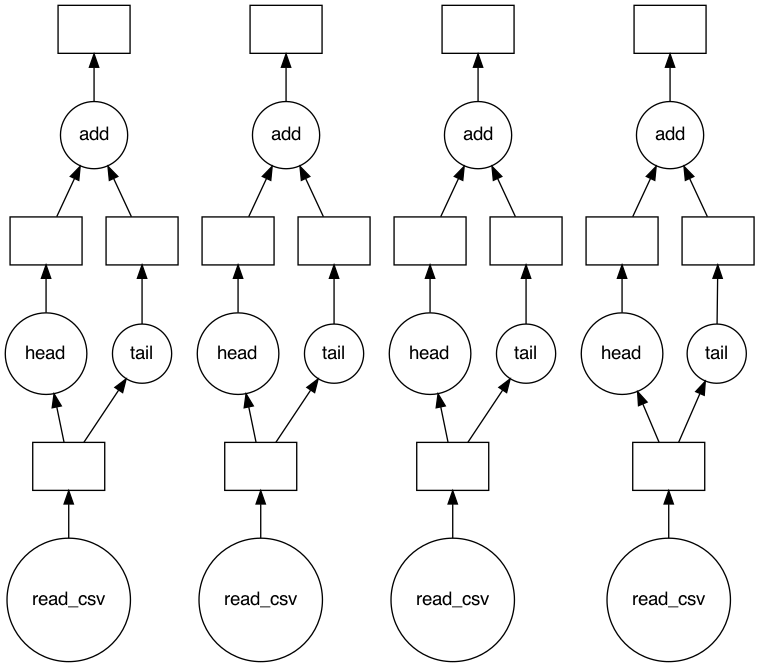
如果您真的想在这里使用Dask DataFrame,您可以尝试:
- 将所有文件读入一个Dask DataFrame,
- 确保每个Dask“分区”对应于一个文件,
- 使用Dataframe
apply获取head和tail值,并将它们附加到新的列表中 - 调用新列表上的计算
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/71391114
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号