
使用相同的边比较不同的histogram2d绑定
我有一个如下所示的数据集:
tsne_results_x tsne_results_y team_id
0 -22.796648 -26.514051 107
1 11.985229 40.674446 107
2 -28.231720 -49.302216 107
3 31.942875 -14.427114 107
4 -46.436501 -7.750005 107
76 24.252718 -20.551889 8071
77 2.362172 17.170067 8071
78 7.212677 -9.056982 8071
79 -5.865472 -32.999077 8071我想要存放tsne_results_x和tsne_results_y列,为此我使用numpy函数histogram2d
grid, xe, ye = np.histogram2d(df['tsne_results_x'], df['tsne_results_y'], bins=15)
gridx = np.linspace(min(df['tsne_results_x']),max(df['tsne_results_x']),15)
gridy = np.linspace(min(df['tsne_results_y']),max(df['tsne_results_y']),15)
plt.figure()
#plt.plot(x, y, 'ro')
plt.grid(True)
#plt.figure()
plt.pcolormesh(gridx, gridy, grid)
plt.colorbar()
plt.show()
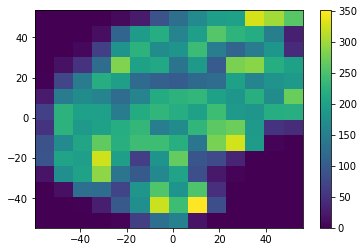
但是,正如您所看到的,我在数据框架中有几个team_id,我希望将一个团队的单个回收箱与整个数据框架进行比较。例如,对于一个团队,在一个特定的容器中,我希望将其除以包含所有团队的总数。
因此,我认为在一个特定的团队数据集上运行histogram2d,对整个数据集使用相同的行空间就可以做到这一点。没有,因为histogram2d将以不同的方式存储one_team_df,因为数据的范围不同。
one_team_df = df.loc[(df['team_id'] == str(299))]
grid_team, a, b = np.histogram2d(one_team_df['tsne_results_x'], one_team_df['tsne_results_y'], bins=15)
gridx = np.linspace(min(df['tsne_results_x']),max(df['tsne_results_x']),15)
gridy = np.linspace(min(df['tsne_results_y']),max(df['tsne_results_y']),15)
plt.figure()
#plt.plot(x, y, 'ro')
plt.grid(True)
#plt.figure()
plt.pcolormesh(gridx, gridy, grid_team)
#plt.plot(x, y, 'ro')
plt.colorbar()
plt.show()
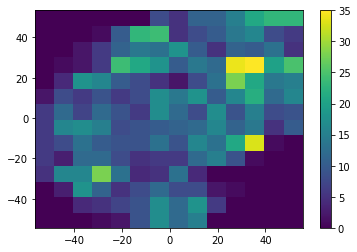
我想知道如何使这两种表述具有可比性。是否有可能运行histogram2d给出xedges和yedges?通过这种方式,我可以使用整个二进制化的边缘来对一个团队进行定位。
问候
回答 1
Stack Overflow用户
发布于 2022-03-04 12:01:04
binsint或array_like或int,int或数组,数组,可选bin规范:如果int,则为二维(nx=ny=bins)的回收箱数。如果为array_like,则为二维(x_edges=y_edges=bins)的bin边。如果int,int,则表示每个维度中的回收箱数(nx,ny = bins)。如果数组,数组,则每个维度中的bin边缘(x_edges,y_edges = bins)。一个组合的int,数组或数组,int,其中int是回收箱的数目,数组是bin边。
这意味着您可以指定您想要的回收箱。例如:
grid_team, a, b = np.histogram2d(
one_team_df['tsne_results_x'], one_team_df['tsne_results_y'],
bins=[np.linspace(-40,40,15), np.linspace(-40,40,15)]
)https://stackoverflow.com/questions/71351047
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号