
在训练多个时代的模型之后,Keras默认使用哪种参数配置来进行预测?
在训练多个时代的模型之后,Keras默认使用哪种参数配置来进行预测?
提问于 2022-02-04 10:33:48
我有一个关于Keras的一般性问题。当训练人工神经网络(例如多层感知器或LSTM)的训练、验证和测试数据分离(例如70 %,20 %,10 %)时,我想知道训练后的模型最终使用哪种参数配置来进行预测?
在这里,我经历了一个经历了11个时代的训练过程:
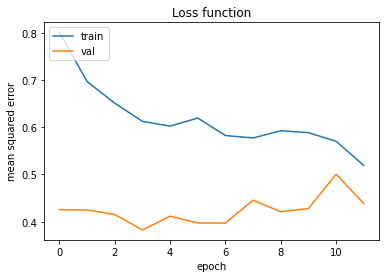
我可以考虑三种可能的参数配置(当然还有其他的):
- 导致训练数据集中的最小错误的配置(将在11世纪之后)
- 在最后一个时代之后的配置(这将在11世纪之后,就像在1.)
- ,它导致验证数据集中的最小错误(将在第3个时代之后)
。
例如,如果您只是构建模型而没有如下所示:
# Build the model and train it
optimizer_adam = tf.keras.optimizers.Adam(lr= 0.001)
model = keras.models.Sequential([
keras.layers.LSTM(10, return_sequences=True, input_shape=[None, numberOfInputFeatures]),
keras.layers.LSTM(10, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(numberOfOutputNeurons))
])
model.compile(loss="mean_squared_error", optimizer=optimizer_adam, metrics=['mean_absolute_percentage_error'])
history = model.fit(X_train, Y_train, epochs=11, batch_size=10, validation_data=(X_valid, Y_valid))
# Predict the values from the test dataset
Y_pred = model.predict(X_test)您能告诉我哪种配置用于预测Y_pred = model.predict(X_test)行中测试数据集的值
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-02-04 11:06:31
这将是上一个时代之后的配置(您已经提到的第二个可能的配置)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70984921
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号