GAIA 榜首,BrowseComp 第一:MiroThinker-H1 如何用核查机制打败 GPT-5 ?

GAIA 榜首,BrowseComp 第一:MiroThinker-H1 如何用核查机制打败 GPT-5 ?

唐国梁Tommy
发布于 2026-06-25 21:33:59
发布于 2026-06-25 21:33:59
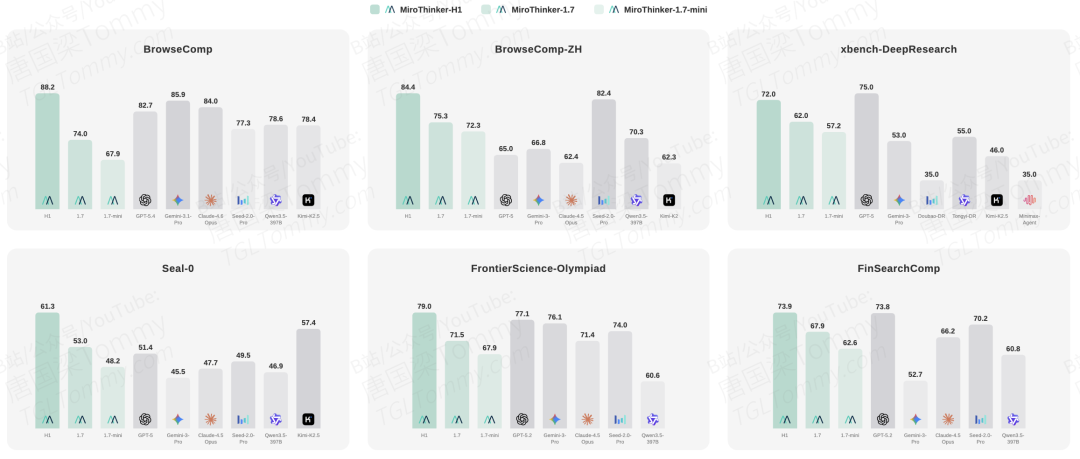
如果你最近关注 Deep Research Agent 领域,MiroThinker-1.7 & H1 这篇技术报告值得认真读一遍。它不是在已有 LLM 外面套一个检索模块,而是从训练阶段就把"Agent 能力"作为一等公民对待——包括如何规划、如何调用工具、如何在长轨迹中保持推理连贯性。在此基础上,H1 版本进一步引入了一个鲜少被系统探索的机制:把验证(verification)直接嵌入推理过程,而不是事后打分。结果在 BrowseComp 上拿到 88.2,GAIA 达到 88.5,超过 GPT-5 整整 12 个百分点。
交互轮次越多,不等于越有效
当前大多数 Deep Research Agent 的优化路径是:增加搜索轮次、增加上下文长度、增加并行工具调用。这条路有天花板:当每一步的质量不可靠时,更长的轨迹只会累积更多噪声,而不是接近答案。
论文的实验数据非常直接。将 MiroThinker-1.5-30B 与同参数量的 1.7-mini 对比,后者在五个 agentic benchmark 上平均少用 43% 的交互轮次,但性能提升 16.7%。在 HLE(Humanity's Last Exam)这类长程任务上差距更明显:轮次减少 61.6%,性能反而高 17.4%。这组数字指向一个清晰的判断:提升每一步的可靠性,比延长轨迹长度更有价值。正是这个判断,决定了 MiroThinker-1.7 训练管线的设计逻辑。

四阶段训练管线:原子能力先于端到端策略
MiroThinker-1.7 基于 Qwen3 MoE 开源检查点,经过四个阶段训练:Agent 中训练(Mid-training)→ 监督微调(SFT)→ 偏好优化(DPO)→ 强化学习(GRPO)。
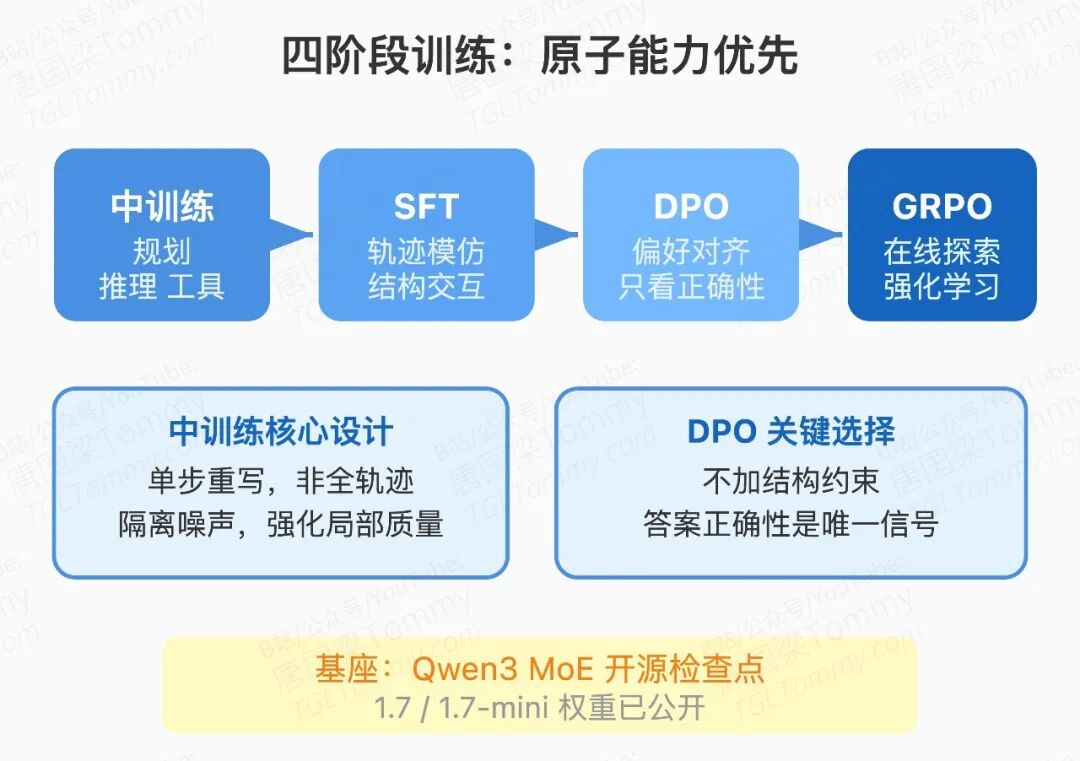
第一阶段是最值得关注的设计。通常做法是直接用完整轨迹做 SFT,但这会把每一步的噪声一起学进去。MiroThinker 的做法是先单独强化原子能力:冷启动规划(给定 query,直接生成结构化计划和第一次工具调用)、步骤推理(从轨迹中截取某一步 ,在完整前缀上下文 下重写该步输出)、答案聚合(在局部观测下汇总证据)。
训练目标是标准的下一 token 预测:
这种"单步重写"而非"全轨迹监督"的方式,使模型在噪声较高的真实轨迹上也能学到干净的局部行为,不会被一条烂轨迹整体污染。
第三阶段 DPO 的偏好判断只看答案正确性,没有对规划长度、步数模板做任何约束——论文明确指出,加结构性约束会引入系统性偏差,降低跨任务泛化能力。第四阶段用 GRPO 在线 RL 做探索,奖励函数 兼顾正确性与格式合规。为防止策略熵过早崩塌,引入动态 KL 惩罚系数 ,专门对负样本中的低概率 token 施加额外正则,优化目标为:
其中优势 是组内相对奖励,避免绝对奖励尺度对训练的影响。
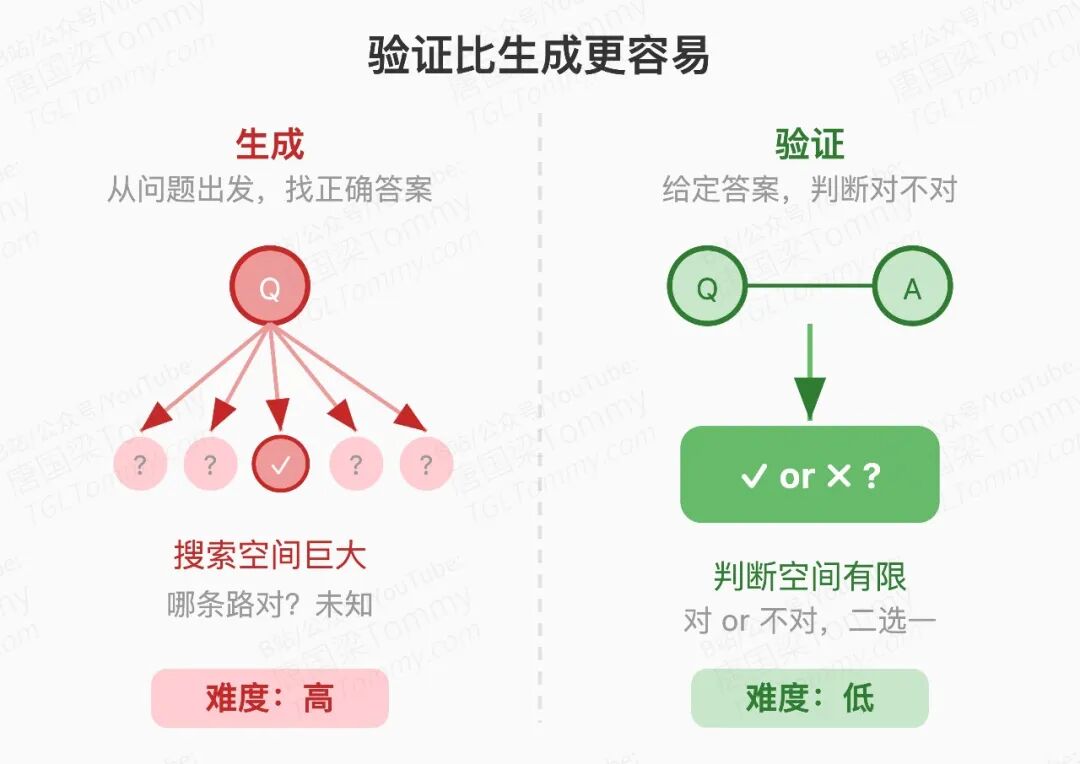
"验证比生成更容易"——H1 的核心思想
MiroThinker-H1 是在 1.7 基础上增加了两个验证器。这个设计背后有一个长期被低估的认知:验证的难度通常低于生成。给定一条推理链和最终答案,判断它对不对,比直接生成正确答案要容易得多。H1 将这个不对称性系统化地利用起来。
Local Verifier 作用在每一步。标准 ReAct 范式下,模型倾向于沿最高概率路径走,在难题上容易陷入"惯性思维"——反复确认自己已有的偏见,而不是真正探索。Local Verifier 在每步结束后介入,评估当前推理步骤的质量,必要时触发重试。实验用 BrowseComp 中 295 道 MiroThinker-1.7 经常失败的难题做测试:加入 Local Verifier 后,Pass@1 从 32.1 跳到 58.5(+26.4),同时交互步数从 1185.2 骤降至 210.8——不到原来的五分之一。这个步数减少并非设计目标,而是验证机制让每步更有效后的自然结果,我认为这恰恰是一个强信号。
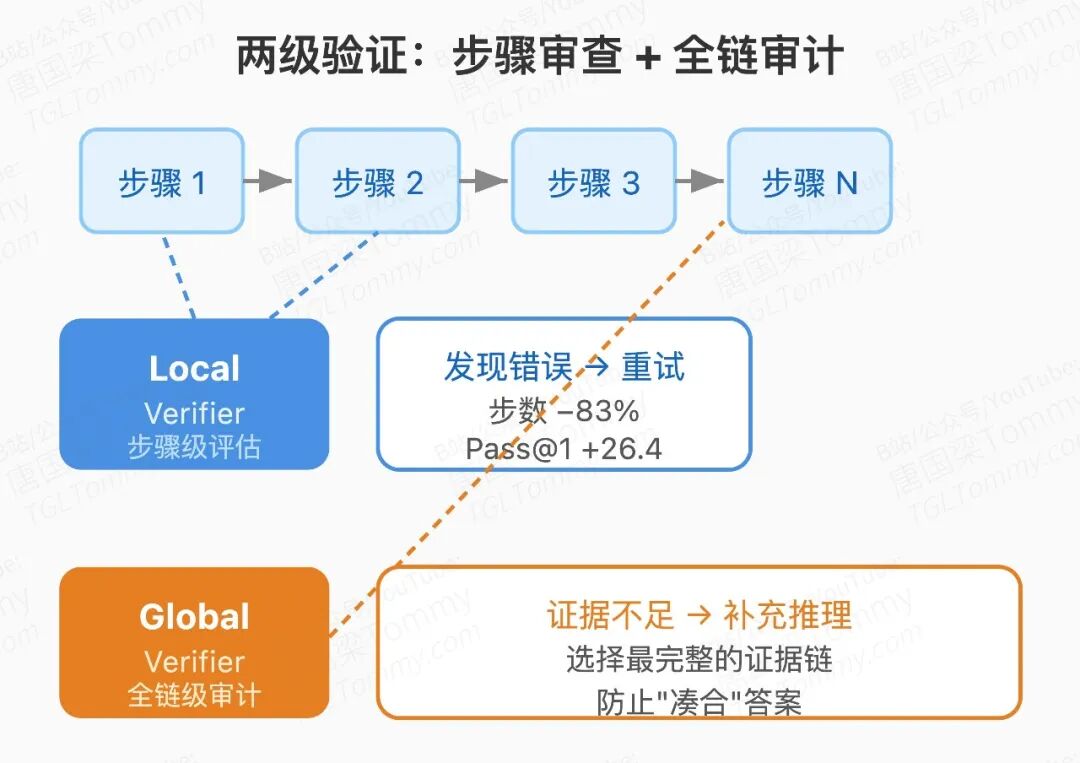
Global Verifier 作用在整条推理链结束后。它审计证据链的完整性:如果支撑答案的证据不够充分,则要求 Agent 补充推理,而不是直接接受一个"凑合"的答案。从结果看,BrowseComp +14.2,SEAL-0 +8.3,FrontierScience-Olympiad +7.5,HLE +4.8,覆盖搜索密集型和复杂推理型任务,说明这个机制有不错的泛化性。
数字背后:真正的亮点与值得审视的地方
MiroThinker-H1 在多个主流榜单拿到第一:BrowseComp 88.2(超过 Gemini-3.1-Pro 的 85.9 和 Claude-4.6-Opus 的 84.0),BrowseComp-ZH 84.4,GAIA 88.5(超过 GPT-5 的 76.4 达 12.1 个百分点)。专业领域上,FrontierSci-Olympiad 79.0 超过 GPT-5.2-high(77.1)和 Gemini-3-Pro(76.1)。

有几点值得客观审视。
第一,基准测评中竞品结果均来自各家技术报告或 model card,未在统一环境下复现,横向对比存在一定不确定性;论文也在表格注释中如实说明了这一点。
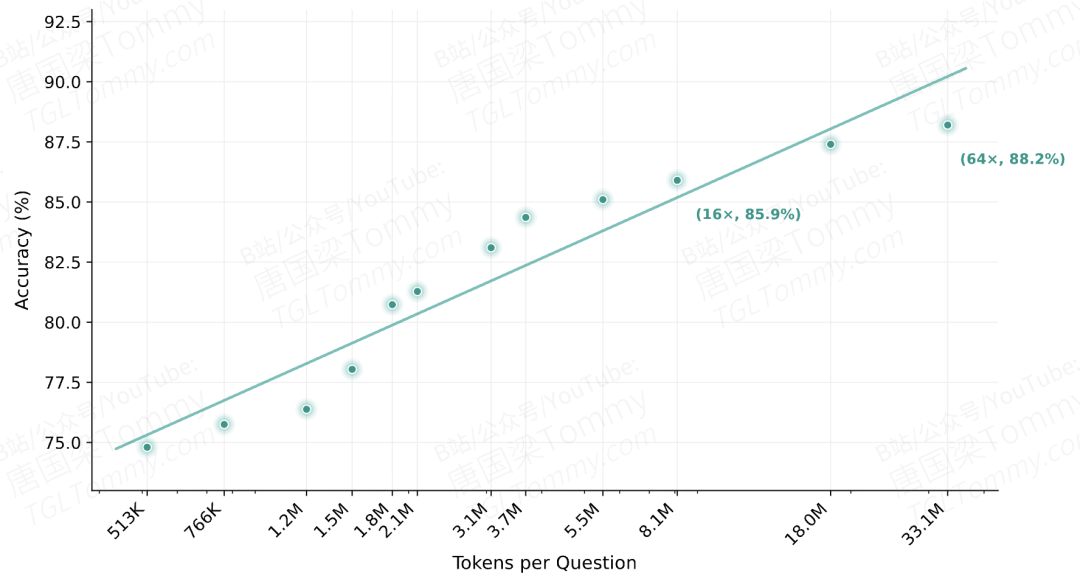
第二,H1 本质上是推理时计算扩展(test-time compute scaling):图 7 显示 BrowseComp 准确率随 token 预算近似对数线性增长,从 16× 的 85.9 到 64× 的 88.2,代价是 4 倍计算量。在生产环境中这个成本如何控制,论文没有详细讨论。
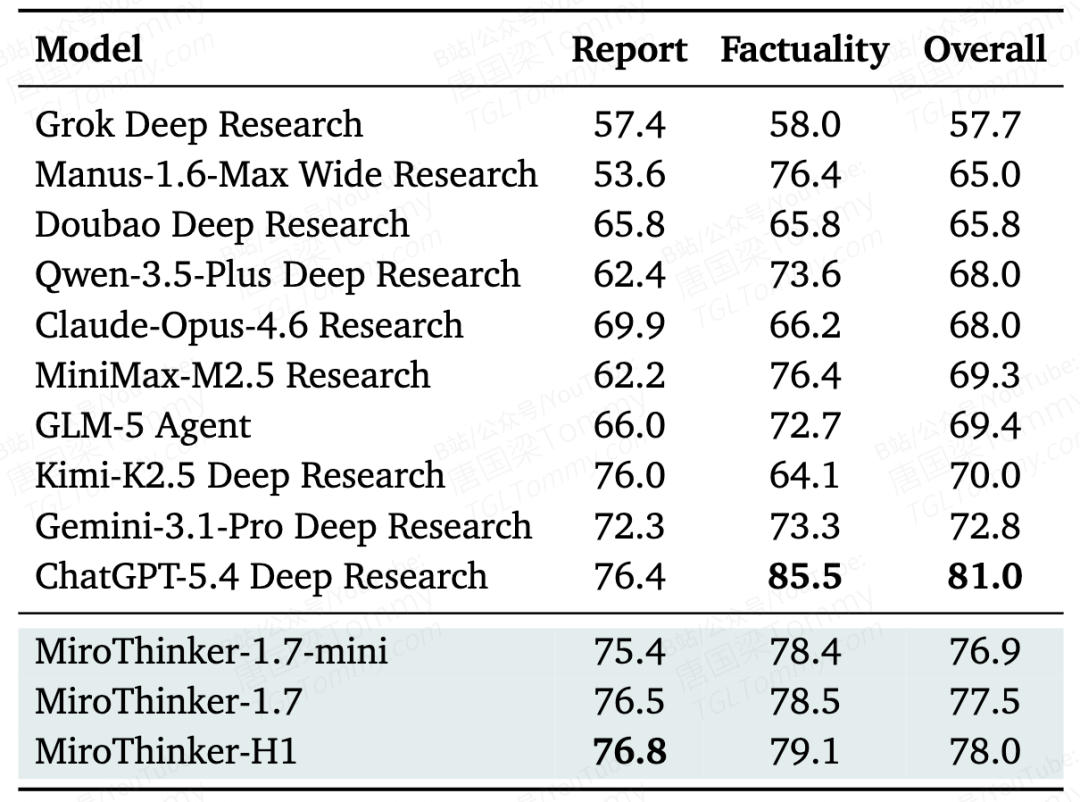
第三,长报告评估(Table 3)上 MiroThinker-H1 整体得分 78.0,低于 ChatGPT-5.4 Deep Research 的 81.0,说明在报告生成这一维度上仍有差距。
对从业者的参考价值:哪些设计思路可以复用
MiroThinker-1.7 和 1.7-mini 的模型权重已开源(Qwen3 MoE 基座),GitHub 仓库同步公开。对于正在构建 Agent 系统的从业者,我认为以下几点有直接参考价值:

其一,上下文管理策略。滑动窗口 保留最近 5 步观测,但完整保留全部 thought-action 轨迹,并对每步工具输出做截断 。这是一个工程上可操作的平衡点,在长轨迹任务上值得借鉴。
其二,训练时原子能力与端到端策略分离。先用单步重写数据强化规划和推理的局部质量,再用完整轨迹做 SFT 和 RL,比直接端到端训练噪声更低。这个思路对资源有限、数据质量参差不齐的团队尤其实用。
其三,验证器作为推理时插件。Local Verifier 和 Global Verifier 并不需要重新训练基础模型,而是在推理框架层面引入。这意味着它们在原则上可以独立于模型迭代,适合作为已有 Agent 系统的增量改进。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号