微软多模态Phi-4-reasoning-vision-15B:用200B token训出来的多模态推理模型,凭什么敢和1T+对打?

微软多模态Phi-4-reasoning-vision-15B:用200B token训出来的多模态推理模型,凭什么敢和1T+对打?

唐国梁Tommy
发布于 2026-06-25 21:31:30
发布于 2026-06-25 21:31:30
这篇报告解决的问题是:如何在显著更少的训练数据和推理计算开销下,构建一个在数学科学推理与GUI操控上竞争力强的多模态模型。核心贡献是系统化数据质量工程 + 动态分辨率视觉编码 + 混合推理/非推理训练模式的三位一体方案。如果你在做多模态模型训练、数据流水线设计,或者考虑在资源受限场景下部署推理型VLM,这篇报告值得仔细看。
VLM越来越大
但这条路走得通吗?
当前主流VLM的训练路线越来越重——Qwen3-VL、Kimi-VL、Gemma3这些模型的多模态训练数据规模普遍超过1T token,推理时生成的token数也在持续膨胀。这带来了明显的成本和延迟问题,在交互式场景或资源受限的部署环境中尤为突出。
Phi系列一直在走"少而精"这条路,从最早的"Textbooks Are All You Need"哲学延续至今。这次的Phi-4-reasoning-vision-15B:整个多模态训练只用了200B token,相比对标的1T+模型,量级差了5-10倍。它的目标不是刷所有benchmark的SOTA,而是在"精度 vs. 推理计算量"的Pareto前沿上找到更好的点。
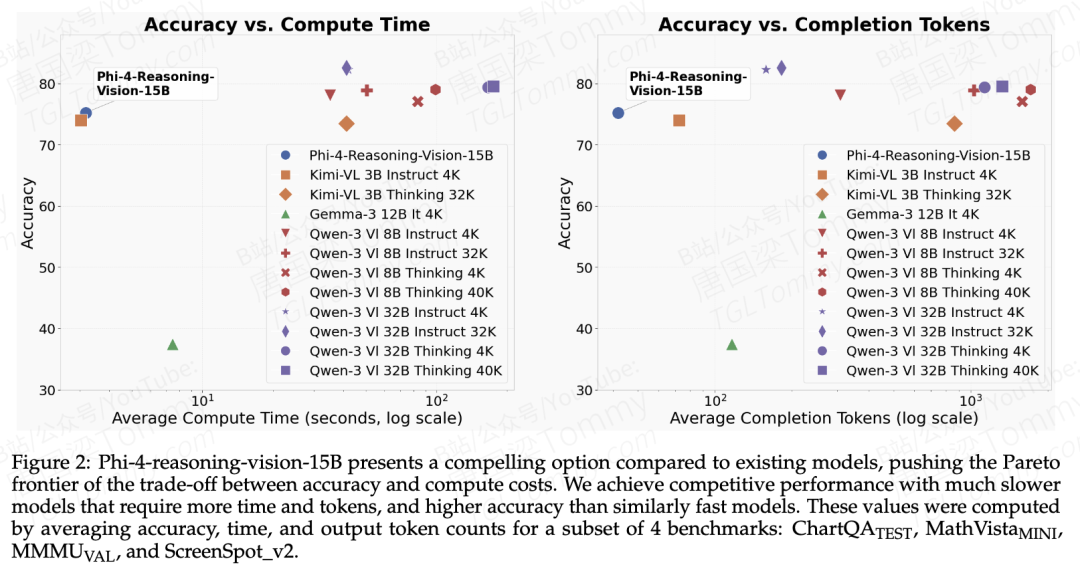
三个设计决策
每一个都有说法
Mid-fusion:不是没做早融合,是主动选择不做
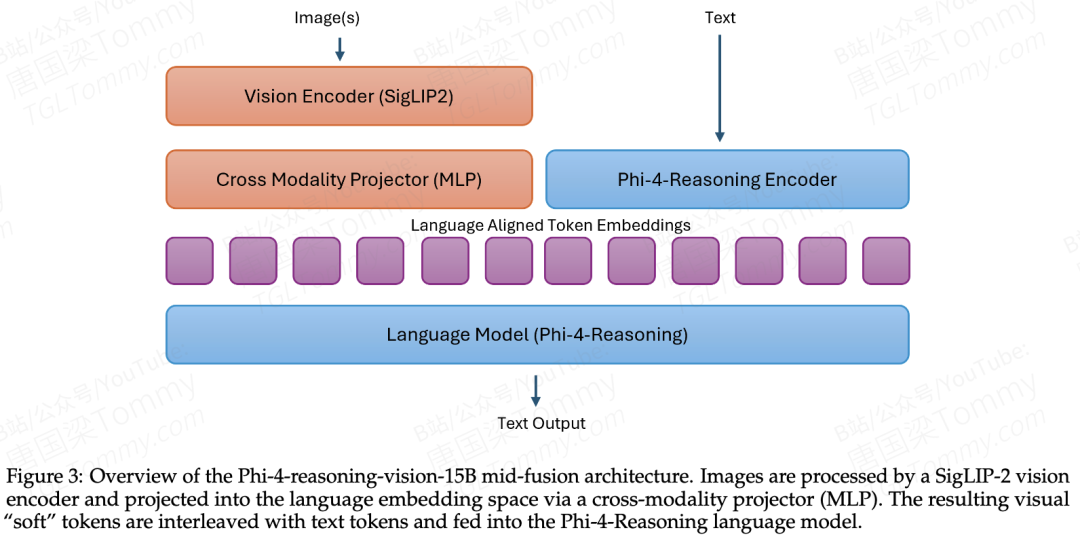
架构上选的是mid-fusion:SigLIP-2视觉编码器输出的视觉token经过MLP投影后与文本token拼接,喂给Phi-4-Reasoning语言模型。Early-fusion把图像patch和文本token丢进同一个transformer,跨模态注意力无限制地交互——表征理论上更丰富,但计算量、内存和数据需求大幅上升。对于"少数据、低延迟"目标来说,mid-fusion是更务实的选择,而不是一个技术妥协。
动态分辨率:感受野质量比token数更重要
这部分是报告里最有工程价值的ablation。他们在5B参数的小版本上测了四种图像处理方式:Dynamic-S²、Multi-crop(384×384切块)、Multi-crop with S²(1536×1536切块后做S²)、以及动态分辨率(NaFlex variant of SigLIP-2)。
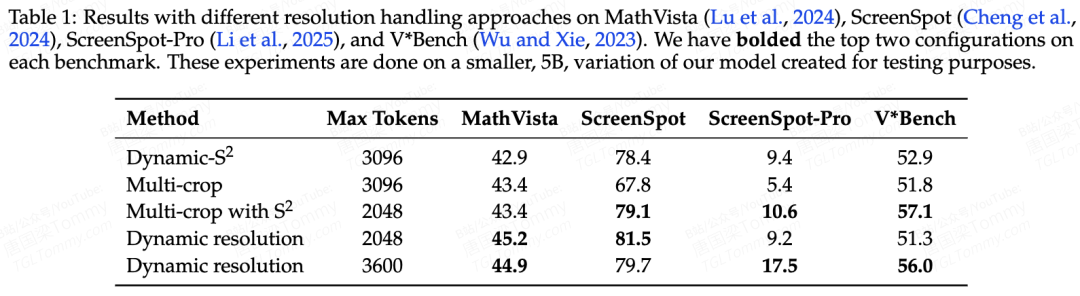
结论很清晰:动态分辨率 + 大token数(3600 max)在高分辨率benchmark上表现最好,ScreenSpot-Pro从9.2跳到17.5。一个反直觉的地方:Multi-crop with S²用2048 tokens反而比标准Multi-crop的3096 tokens在多个任务上更好——说明感受野的构造方式比堆token数量更关键。 S²-based方法受限于原始图像分辨率,平均只能用到最大token数的一半,这是个实际的效率陷阱。
20%的思考,80%的直接回答
这是这篇报告里最有讨论价值的设计。对OCR、图像描述这类感知型任务,强行加chain-of-thought不仅无益,有时反而有害;对数学和科学推理,多步思考又是明确有效的。如何在一个模型里同时处理这两类需求?

他们的路线是:从Phi-4-Reasoning(本身已是推理型语言模型)出发,在多模态训练阶段混入两类数据——约20%带<think>...</think>块的推理数据(覆盖数学、科学),和约80%以<nothink>token起始的非推理数据(覆盖描述、OCR、grounding等)。模型从数据分布里隐式学到了"何时需要思考"的判断,用户也可以通过显式注入token来覆盖默认行为。
对比几条备选路线:非推理LLM起步 + 多模态推理训练,数据负担重且推理能力天花板低;先做多模态再加推理,存在catastrophic forgetting风险;推理LLM起步但全量用推理数据,所有请求都会生成冗长思考链。混合模式在这几者之间取了一个工程上更实用的平衡点。
数据比架构更重要
这篇报告的真正论点
报告里用了大量篇幅讲数据处理,且明确将其列为"最主要的性能提升来源"。他们把训练数据按质量分成了几类:优质数据直接保留;题好答错的,用GPT-4o/o4-mini重新生成答案并做majority voting;题目质量差的直接丢弃,或仅用图像作为caption生成的seed;格式错误的做程序化修复。
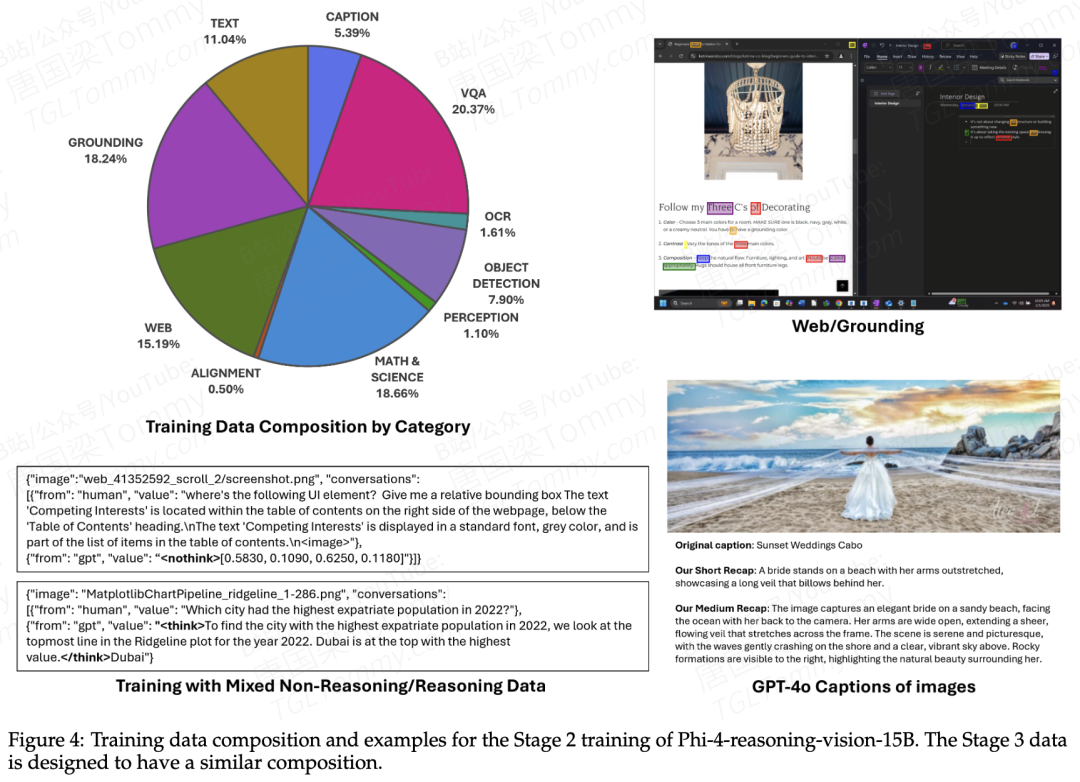
几个增强策略值得记:对所有数学/科学图像额外生成一份图像描述,让同一张图在训练集里出现两次(QA + caption);用多图scrambled matching格式增强多图注意力;用连续截图对生成"what's changed"数据用于CUA场景;对过度结构化的提示词做多样化改写来提升鲁棒性。
数据比例实验里还有一个有意思的发现:增加数学数据不会伤害CUA性能,反而对ScreenSpot-V2有轻微提升。在当前数据规模下,两类任务的表征是相互促进的——但作者也坦言这个结论在更大规模下是否成立还是开放问题。
88.2分的ScreenSpot-v2
背后是什么?
和非thinking模型的对比中(Table 5),Phi-4-reasoning-vision-15B整体处于15B参数区间的中游:AI2D(84.8)、MathVista(75.2)、ScreenSpot-v2(88.2)表现不错,但MMMU(54.3)、MathVerse(44.9)、MathVision(36.2)与Qwen3-VL-32B差距明显。15B vs 32B的参数差距在宽泛通用任务上难以弥补,这在预期之内。
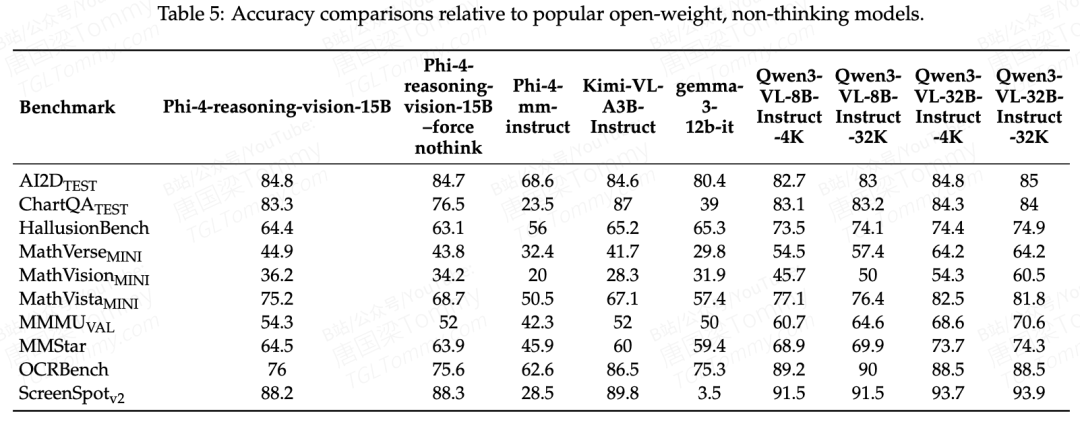
ScreenSpot-v2的88.2值得单独关注。 GUI grounding是CUA场景的核心能力,这个分数意味着在这类任务上,15B模型已经接近一些更大的模型,而这正是报告想重点强调的方向。
强制thinking vs 强制nothink的对比(Table 6)也印证了混合模式更稳健的判断:MathVerse在thinking模式下从44.9升到53.1,但AI2D则从84.8跌至79.7。混合默认行为在整体平均上优于任何单一模式,尽管在某些特定任务上确实不是最优解。
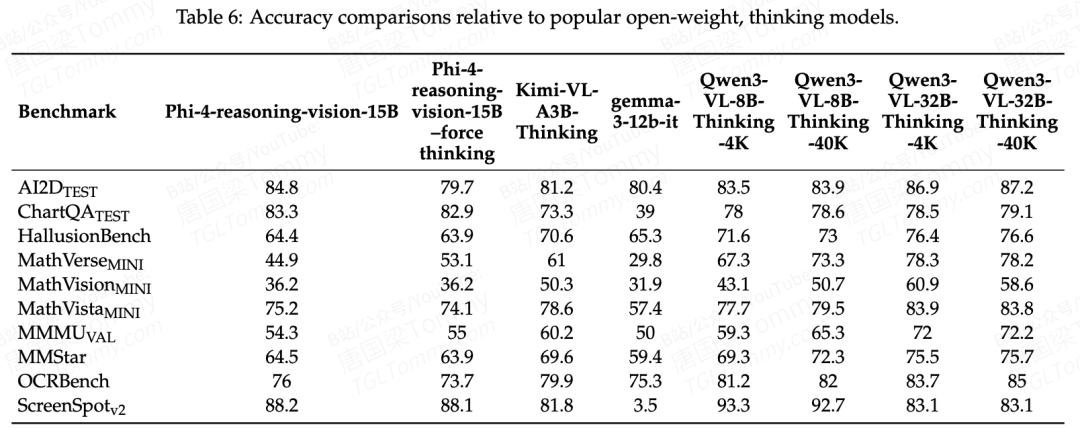
值得留意:所有数字都是作者自测结果,可能低于各模型在leaderboard上报告的数字。他们承诺公开所有evaluation log,这个透明度本身就值得赞赏。
这个方向能用在哪?
不能用在哪?
Phi-4-reasoning-vision的定位非常清晰:资源受限、延迟敏感、需要数学/科学推理和GUI操控能力的场景。如果你需要通用多模态问答的SOTA,这不是最佳选择;如果你在做CUA、教育场景的多模态推理、或者需要在消费级GPU上部署,这是目前开源模型里性价比最高的选项之一。
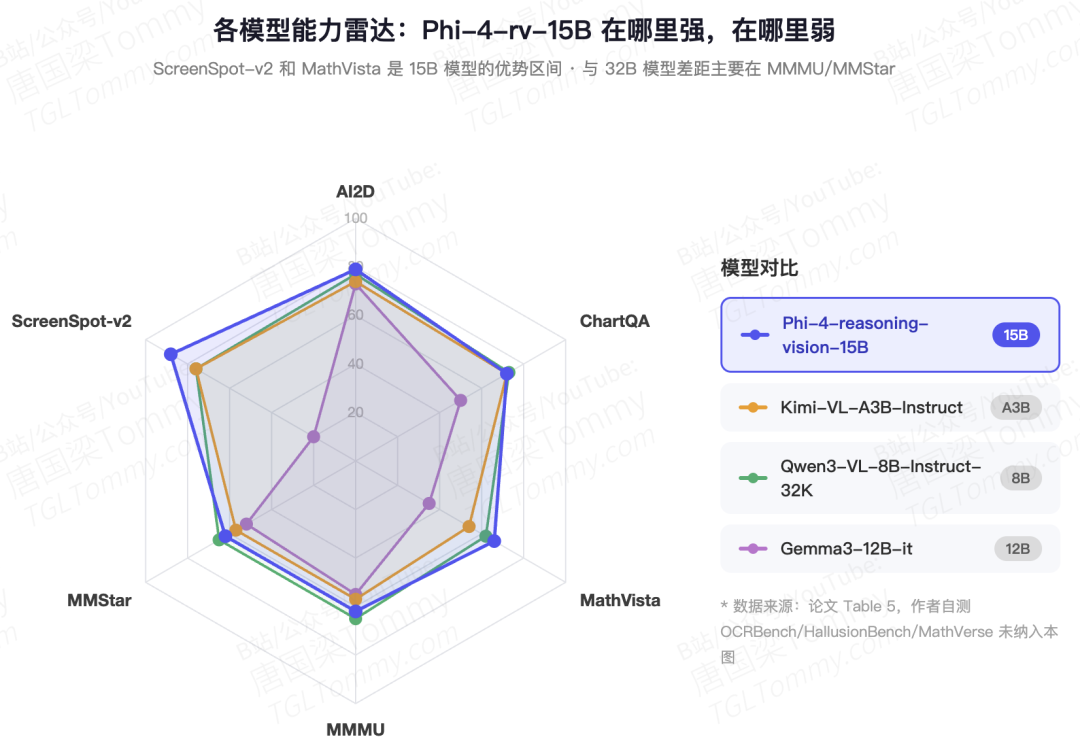
和近期工作的关系上:Qwen3-VL在scaling上走的是另一极端;Kimi-VL在thinking模型上投入更重;Gemma3有自己的pan-and-scan路线。Phi-4-reasoning-vision更像是一个"最优工程解"的展示,而不是某个单一技术突破的论文。 这个定位决定了它的参考价值主要在于方法论层面,而不是benchmark刷分。
混合推理模式的边界仍然模糊——模型何时选择思考、何时直接回答,是从数据分布隐式学到的,不总是最优的。 作者也承认这一点,并将"确定理想数据比例"列为开放问题。20/80的分配是一个经验起点,不是最终答案。
模型已在HuggingFace和Microsoft Foundry开放,训练数据计划近期部分开源。这篇报告最值得带走的一句话:多模态模型的性能天花板,目前更多由数据质量决定,而不是参数规模。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号