从万亿基座到智能涌现——KIMI K2 & K2 Thinking 深度解析

从万亿基座到智能涌现——KIMI K2 & K2 Thinking 深度解析

唐国梁Tommy
发布于 2026-06-25 21:16:23
发布于 2026-06-25 21:16:23
一、KIMI K2 简介与核心理念
1.1 什么是 Kimi K2?
Kimi K2 是由月之暗面 (Moonshot AI) 推出的万亿参数级混合专家(MoE)大语言模型。
它不仅仅是一个模型,而是一个由两部分组成的完整系统: Kimi K2 Base (基础模型):一个拥有1.04万亿总参数的强大基础模型,通过创新的预训练技术构建。 Kimi K2 Thinking / Instruct (智能体):在基础模型之上,通过大规模智能体数据和强化学习训练出的“边思考边使用工具”的智能体。
1.2 核心范式转变:智能体智能 (Agentic Intelligence)
传统LLM:主要进行静态学习和响应,如CoT(思维链)是在模型内部的逻辑展开。
Kimi K2 Thinking:其范式转变为“思考 → 行动 → 再思考”。模型不仅能学习,还能在复杂动态环境中自主地感知、规划、推理和行动。
这种设计使其能超越静态数据的限制,通过自身的探索和工具使用来获取新能力。
二、K2 架构设计与工程权衡
Kimi K2 延续并优化了 MoE 架构,其核心思想是通过激活一小部分“专家”网络来处理信息,从而在巨大模型规模下保持高效推理。
2.1 核心架构:1T 参数 MoE
总参数量: 1.04万亿 (1.04T)。
激活参数量: 每个 token 推理时仅激活 320亿 (32B) 参数,实现了极高的计算效率。
专家系统 (MoE):
- • 专家数量: 384 个,体现了“更多、更小专家”的设计哲学,以实现知识的精细化分工。
- • 激活机制: 每个 token 会路由到 8 个选定专家 和 1 个共享专家 进行处理。
- • MoE 引入:仅首个 block 使用标准 FFN,从第二个 block 开始便引入 MoE 结构,更早地利用稀疏激活的优势来优化计算资源。
词汇表 (Vocabulary Size): 160k,更大的词汇表能更高效地编码多语言和专业术语,在处理长文本时减少 token 数量,节约成本。
上下文窗口 (Context Window): 支持高达 256k tokens,使其能够处理和记忆数百页的文档内容,为深度研究和长篇代码项目提供支持。
注意力机制 (Attention): 采用 MLA (Multi-head Latent Attention) 机制。
2.2 KIMI K2 vs DeepSeek R1
通过对比图中的 Kimi K2 和 DeepSeek R1,可以看出 Kimi K2 在多个关键维度上做出了独特的设计选择:
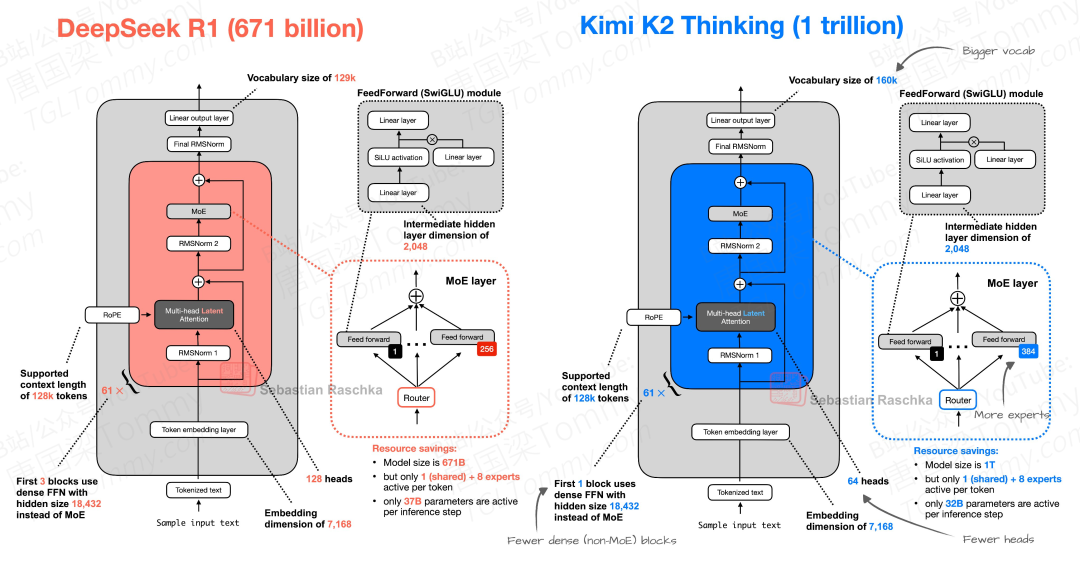
(左滑查看完整信息)
技术特征 | Kimi K2 Thinking | DeepSeek R1 (对比) | 设计意图分析 |
|---|---|---|---|
总参数量 | 1万亿 (1T) | 6710亿 (671B) | 追求更高的模型容量和性能上限。 |
词汇表大小 | 160k | 129k | 更大的词汇表可以更高效地编码多语言文本和特殊符号,减少 token 数量,从而在处理长文本时节省计算资源。 |
注意力头 (Heads) | 64 个 | 128 个 | 减少注意力头数量可以降低注意力计算的复杂度和显存占用,从而加快推理速度。这是一种在性能和效率间的权衡。 |
MoE 专家数量 | 384 个 | 256 个 | “更多、更细颗粒度专家” = 更强专业分工;本质上是在做“知识稀疏化 + 专业化”而不是简单 scale up |
激活参数量 | 32B | 37B | 激活参数才是推理时真正动的算力;32B 意味着跑起来成本比其 1T 字面数字更低 |
非 MoE 层数 | 第 1 个 block 使用标准 FFN | 前 3 个 block 使用标准 FFN | MoE 层通常在模型的中后部效果更好。Kimi K2 更早地引入 MoE 结构(从第 2 个 block 开始),将更多计算量分配给稀疏激活的专家网络,进一步优化资源利用。 |
上下文长度 | 训练末期 128k,推理支持 256k | 支持 128k tokens | 在预训练后期使用 YaRN 方法将上下文窗口扩展到 128k,并最终支持高达 256k 的上下文。 |
注意力机制 | (Multi-head Latent Attention) | 多头注意力 | MLA 不是“缩头数”,而是把 Attention 的显式 Q/K/V 计算拆成 latent 压缩空间 → 减 KV / KV cache 占用、减显存带宽,长上下文推理稳定性更高; |
三、K2 预训练 —— 攻克“稳定性”与“效率”两大难题
训练万亿模型,核心挑战在于:如何在有限的高质量数据下提升词元效率 (Token-efficient),以及如何保证超大规模训练的稳定性 (Stability)。
3.1 难题一:稳定性 (MuonClip / QK-Clip)
在 Kimi K2 这样万亿参数规模 且在 15.5 万亿海量 Token 上进行预训练的工程中,训练稳定性是压倒一切的前提。一次训练崩溃(即“损失尖峰”)可能意味着数万美元的成本浪费和昂贵的训练回滚。
Kimi K2 团队在追求极致“词元效率” 时,遇到了一个致命的稳定性瓶颈,并为此设计了一套精妙的解决方案 (MuonClip)。
3.1.1 问题的根源:Logit 爆炸
注意力 Logit 是在进行 Softmax 操作之前,Query (Q) 和 Key (K) 向量点积的结果。
- • K2 选用了 Muon 优化器,因为它具有极高的词元效率,性能优于 AdamW。
- • 副作用:Muon 在规模化应用时,会导致“注意力 Logit 爆炸” (exploding attention logits),Logit 值可超过 1000。当这个值变得极大时,会导致 Softmax 的输出变得极其尖锐(接近 one-hot 分布),梯度会随之变得极大或极小(梯度爆炸或消失),最终导致训练过程出现损失尖峰 (loss spikes) 甚至完全发散 (divergence)。
3.1.2 现有方案的局限
在提出 QK-Clip 之前,K2 团队评估了两种已有的缓解策略,均不适用:
- • Logit Soft-cap (直接限制 Logit):这种方法治标不治本。虽然最终的 Logit 被限制了,但在此之前的 Q 和 K 点积结果可能已经非常大,这本身就可能在反向传播中引入数值问题。
- • Query-Key 归一化 (QK-Norm):通过对 Q 和 K 向量进行归一化来控制点积的大小。这个方法不适用于 Kimi K2 所采用的多头潜在注意力 (Multi-head Latent Attention, MLA) 架构。原因是,在 MLA 中,Key 矩阵在推理过程中不是被完全实例化 (materialized) 的,因此无法直接应用常规的 QK-Norm。
3.1.3 K2 的创新:QK-Clip
K2 团队提出了 QK-Clip,一种新颖的权重裁剪机制,其设计思想是从源头上控制 Logit 的增长。
核心思想:不干预 Logit,而是约束产生 Logit 的权重
- • QK-Clip 的工作方式是在优化器更新完权重之后 (post-update)。
- • 它不干扰当前训练步骤的前向和反向传播计算,而是将 Logit 作为一种“事后”的监控信号。
- • 通过重新缩放 (rescaling) Query () 和 Key () 的投影权重,来间接限制 Logit 的增长。
最大 Logit ()
为了决定何时以及如何干预,QK-Clip 需要一个监控指标。这个指标就是每个注意力头 在当前批次 (batch) 中的最大 Logit 值,定义如下:
- • 代表注意力头的索引。
- • 是注意力头的维度。
- • 代表当前训练批次的所有样本。
- • 和 分别是样本中第 个 token 的 Query 向量和第 个 token 的 Key 向量。
这个公式计算了单个注意力头在整个批次中所有 token 对之间点积的最大值。
干预机制:按需、按头的权重缩放
- • 触发条件:当某个头的 超过了预设的阈值 (在 Kimi K2 的训练中,),QK-Clip 机制就会被触发。
- • 最小化干预原则:K2 团队观察到,实践中只有一小部分注意力头会出现 Logit 爆炸。因此,为了避免不必要的干扰,QK-Clip 采用了按头 (per-head) 的缩放策略,而不是对整个层的所有头进行统一处理。
缩放因子计算:每个头独立计算其缩放因子
- • 计算缩放因子 。当 时,,权重不发生变化。当 时,,权重将被缩小。
- • 精确缩放:按比例 缩放 和 的特定组件,从源头控制 Logit 增长。
针对 MLA 架构的精细化应用
在 MLA 架构中,QK-Clip 精确地只对非共享的组件进行缩放,以避免跨头影响:
- • 头特定组件 ():按 进行缩放(使用平方根是为了将缩放效果均等地分配给 Q 和 K)。
- • 头特定旋转组件 ():按 进行缩放。
- • 共享旋转组件 ():保持不变,以避免对其他注意力头产生副作用。
3.1.4 MuonClip 优化器的诞生
K2 团队将以下四个部分整合在一起,形成了一个完整的、稳定且高效的优化器,命名为 MuonClip:
- • 原始的 Muon 优化器(保证词元效率)
- • 权重衰减 (weight decay)
- • 一致性 RMS 匹配 (consistent RMS matching)
- • 新提出的 QK-Clip 机制(保证稳定性)
3.1.5 实验效果
效果立竿见影: 如图展示了 Kimi K2 在使用 MuonClip()训练时的最大 Logit 曲线。可以看到,在训练初期,Logit 值迅速增长并被精确地限制在 100。
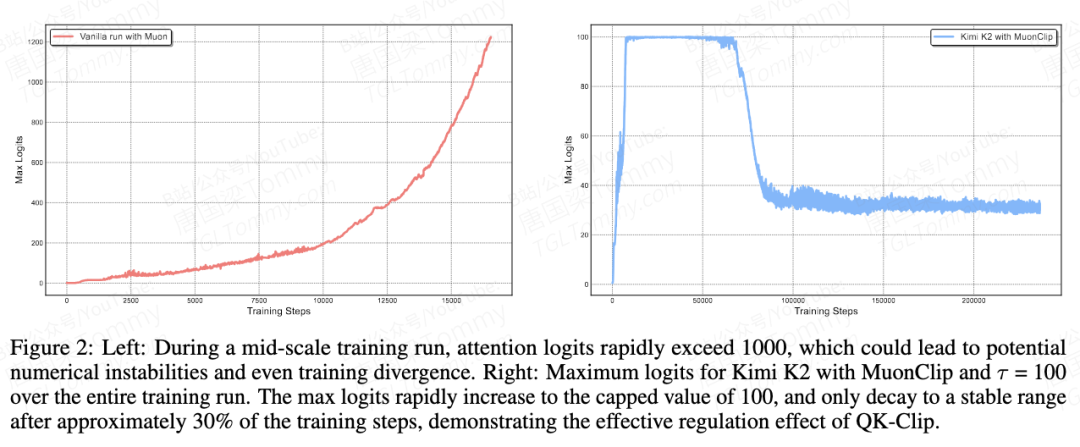
自适应与自失效 (Self-Disabling):随着训练的进行(约 30% 之后),模型的权重逐渐调整到更稳定的状态,最大 Logit 值自然地回落到 100 以下。此时,QK-Clip 的触发条件不再满足 (),它就自动停止了干预。这体现了其“最小化干预”的设计哲学——只在需要时发挥作用。
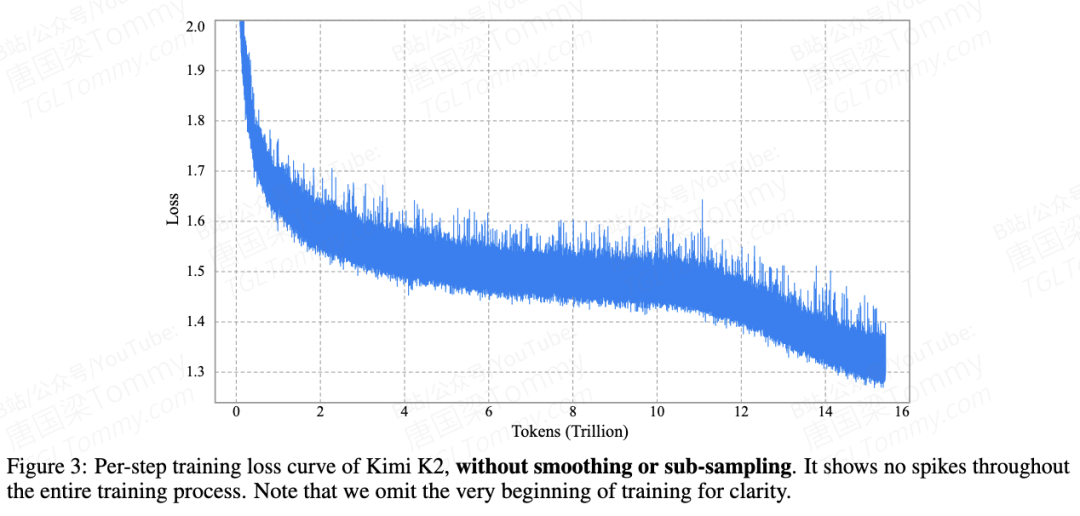
最终结果:MuonClip 成功地使 Kimi K2 在 15.5 万亿 Tokens 的预训练过程中实现了“零损失尖峰 (zero loss spike)”,保证了万亿模型训练的稳定性和效率。
3.2 难题二:词元效率 (Data Rephrasing)
挑战:高质量人类数据日益稀缺。
K2 的方案:设计“数据改写 (Rephrasing)”流水线,在不过拟合的前提下,充分利用高质量数据,增加词元效用。
流程:
- • 提示工程:引导 LLM 以多种风格和视角重写原文。
- • 分块生成:将长文档分块改写再拼接,保持全局连贯。
- • 忠实度验证:对比改写段落与原文的语义一致性,确保内容准确。

成果:实验证明,数据改写比简单地重复训练(多轮次)能带来更显著的性能提升。
四、K2 Thinking —— 智能体 (Agentic) 训练范式
K2 Base 是一个强大的基础模型,而 K2 Thinking 是通过一个精密的后训练 (Post-Training) 过程,将其进化为“智能体”。
K2 Thinking 核心理念: 端到端训练,使“函数调用 (API/工具)”成为模型推理流程中的一个原生动作。
4.1 阶段一:SFT (监督微调)
目标:教会模型如何使用工具。
挑战:真实世界的工具使用数据难以大规模获取。
K2 的方案:大规模智能体数据合成流水线 这是一个三阶段系统,用以模拟真实世界的工具使用场景:
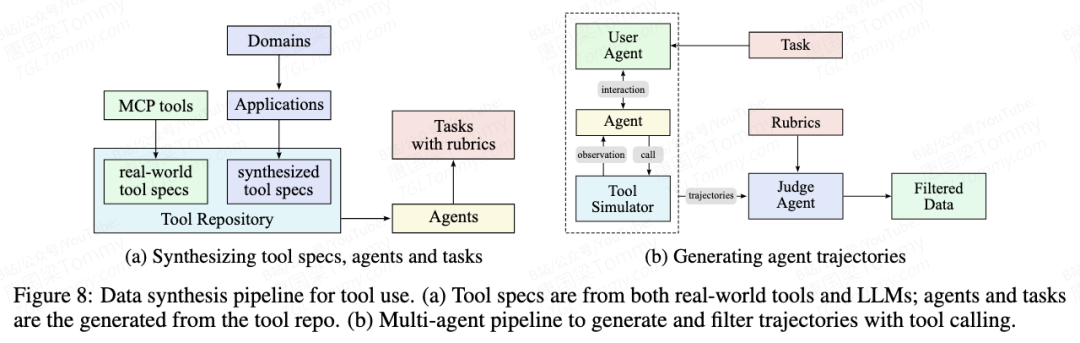
- 1. 工具规范生成 (Tool Spec Generation):
- • 构建一个庞大的工具库:包含 3000+ 真实世界工具 (如 GitHub 的 MCP) 和 20000+ 合成工具。
- 2. 智能体与任务生成 (Agent and Task Generation):
- • 基于工具库,生成数千个具有不同能力、专业领域和行为模式的智能体。
- • 为它们设计从简单到复杂的任务,并配备明确的成功标准 (rubric)。
- 3. 轨迹生成 (Trajectory Generation):
- • 这是一个复杂的多组件系统,用于模拟智能体完成任务:
- • 用户模拟器:由 LLM 扮演不同沟通风格的用户。
- • 工具执行环境:一个复杂的工具模拟器(功能上等同于世界模型),负责执行工具调用并提供真实反馈。
- • 质量评估与过滤:由一个基于 LLM 的“法官”智能体,根据预设标准评估每个交互轨迹,只保留成功的轨迹用于训练。
混合方法 (Hybrid Approach):为弥补模拟环境的真实性不足,团队在编码和软件工程等关键领域,将模拟与真实执行沙盒相结合,确保模型能从真实世界的反馈中学习。
4.2 阶段二:RL (强化学习)
目标:在 SFT 基础上,进一步提升模型的词元效率和泛化能力,特别是在主观偏好任务和复杂推理任务上。
K2 的方案:通用强化学习框架 K2 的 RL 框架包含两大类奖励机制:
- 1. 可验证奖励的“Gym” (Verifiable Rewards Gym, RLVR)
- • 适用场景:有明确对错标准的任务。
- • 具体实现:
- • 数学/STEM:提供具有中等难度的高质量问答对。
- • 编码与软件工程:从 GitHub 收集问题,并利用可执行的单元测试来验证代码的正确性。
- • 忠实性 (Faithfulness):训练一个句子级别的忠实性判断模型,作为奖励模型来提升模型回答的事实准确性。
- 2. 自评奖励机制 (Self-Critique Rubric Reward)
- • 适用场景:没有唯一正确答案的主观任务 (如创意写作)。
- • 机制:K2 模型同时扮演“演员 (Actor)”(生成回答)和“评论家 (Critic)”(评估回答)两个角色。
- • 工作流程:
- • “评论家”K2 会根据一套预定义的规则 (Rubrics)(如清晰性、客观性、禁止奉承等),对“演员”K2 生成的多个回答进行比较和排序,从而产生偏好信号。
- • 闭环优化:“评论家”模型会利用来自“可验证奖励 Gym”的客观信号进行持续更新和校准。这确保了其主观判断力是建立在可验证的数据基础之上,实现了可靠对齐。
RL 算法改进:
- 1. 预算控制 (Budget Control):对超长回答进行惩罚,鼓励简洁高效。
- 2. PTX 损失 (PTX Loss):加入辅助的预训练损失,防止“灾难性遗忘”。
- 3. 温度衰减 (Temperature Decay):从探索转向利用,确保收敛。
五、推理、部署与能力边界
5.1 推理效率与部署优化
K2 不仅规模大,而且在设计之初就考虑了高效部署。
原生 INT4 量化:
- • K2 在后训练阶段采用了量化感知训练 (Quantization-Aware Training, QAT)。
- • 它对 MoE 组件实现了权重专用的 INT4 量化,使其成为一个原生支持 INT4 推理的模型。
- • 效果:生成速度提升约 2 倍,显著降低 GPU 显存占用,且性能几乎无损失。
- • 注意:所有官方公布的基准测试成绩都是在 INT4 精度下测得的。
架构的工程取舍:
K2 的高效并不仅仅依赖量化,更源于其在模型架构层面的精妙取舍。
- 1. 减少注意力头 (Fewer Attention Heads)
- • 设计:K2 将注意力头的数量从(DeepSeek-V3 的)128 个减少到 64 个。
- • 原因:研究团队发现,在长上下文场景下,增加注意力头对性能的提升有限,但会显著增加推理的计算开销 和显存占用。
- • 优势:在 256k 这样的长上下文推理中,更少的头数意味着更小的 KV 缓存,从而显著降低显存占用,并加快推理速度。
- 2. 更早引入 MoE 结构 (Earlier MoE)
- • 设计:K2 仅在首个 block 使用传统的密集 FFN,从第二个 block 开始便引入 MoE 结构。
- • 优势:这比同类模型(如 DeepSeek R1 的前 3 个 block)更早地引入了稀疏激活。
- • 效果:此设计能将更多的计算量分配给稀疏激活的专家网络,从而进一步优化计算资源和推理效率。
5.2 核心能力:“测试时扩展”与“长调用链”
K2 Thinking 的 Agentic 训练,使其在推理时(Test-Time)展现出独特的能力。
测试时扩展 (Test-Time Scaling):
- • K2 Thinking 不仅在训练时扩展(更多参数、数据),还强调在推理时 (Inference Time) 扩展模型能力。
- • 这意味着可以给模型更多的“思考时间”或“调用次数”。
超长任务执行 / 工具调用链:
- • 行业瓶颈:此前模型在 30-50 步工具调用后,会出现性能下降或偏离目标。
- • K2 突破:K2 Thinking 能够稳定地完成 200–300 次连续工具调用,并在长流程中保持目标一致性与上下文连贯性。
- • 这使其能够执行“网页浏览 + 知识检索 + 编程”等真正复杂的多步组合任务。
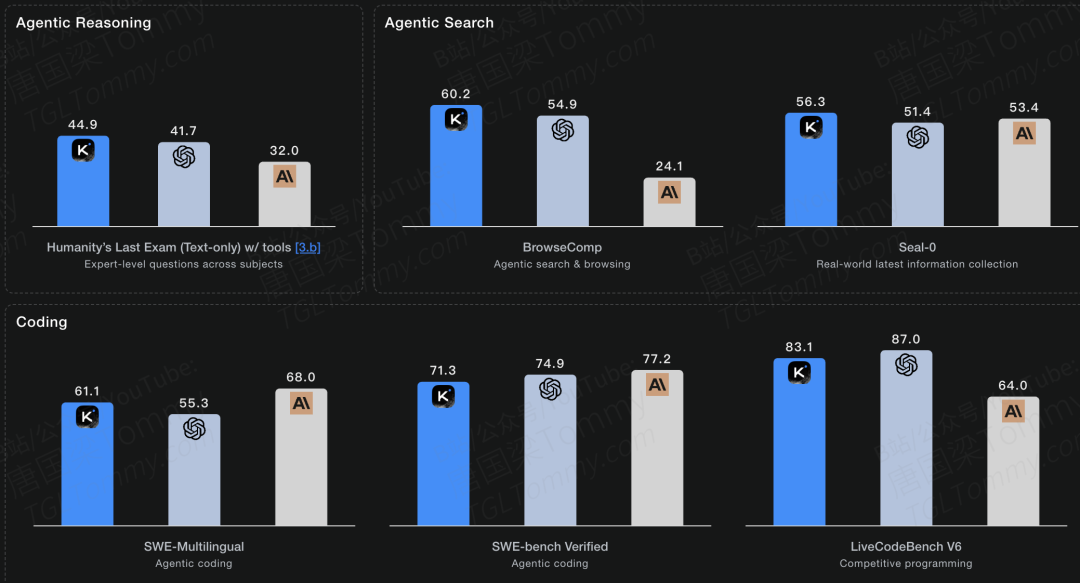
5.3 Kimi K2 Thinking (智能体) 评测
• 智能体工具使用 (τ²-Bench, ACEBench):K2 在多轮工具使用基准上树立了新的标杆,大幅超越了所有基线模型。
• 智能体编程 (SWE-bench):在真实世界的软件工程任务上,K2 取得了开源模型的最佳性能,显著缩小了与 Claude 等专有模型的差距。
• 开放式评估 (LMSYS Arena):截至2025年7月17日,Kimi-K2-Instruct 在超过3000次真实用户盲测中,被评为排名第一的开源模型和总排名第五的模型。
• 长上下文与事实性 (FACTS Grounding):在事实性基准上大幅超越所有对手。
Reasoning Tasks(左滑查看完整信息)
Benchmark | Setting | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 | Grok-4 |
|---|---|---|---|---|---|---|---|
HLE (Text-only) | no tools | 23.9 | 26.3 | 19.8* | 7.9 | 19.8 | 25.4 |
w/ tools | 44.9 | 41.7* | 32.0* | 21.7 | 20.3* | 41.0 | |
heavy | 51.0 | 42.0 | - | - | - | 50.7 | |
AIME25 | no tools | 94.5 | 94.6 | 87.0 | 51.0 | 89.3 | 91.7 |
w/ python | 99.1 | 99.6 | 100.0 | 75.2 | 58.1* | 98.8 | |
heavy | 100.0 | 100.0 | - | - | - | 100.0 | |
HMMT25 | no tools | 89.4 | 93.3 | 74.6* | 38.8 | 83.6 | 90.0 |
w/ python | 95.1 | 96.7 | 88.8* | 70.4 | 49.5* | 93.9 | |
heavy | 97.5 | 100.0 | - | - | - | 96.7 | |
IMO-AnswerBench | no tools | 78.6 | 76.0* | 65.9* | 45.8 | 76.0* | 73.1 |
GPQA | no tools | 84.5 | 85.7 | 83.4 | 74.2 | 79.9 | 87.5 |
General Tasks(左滑查看完整信息)
Benchmark | Setting | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|
MMLU-Pro | no tools | 84.6 | 87.1 | 87.5 | 81.9 | 85.0 |
MMLU-Redux | no tools | 94.4 | 95.3 | 95.6 | 92.7 | 93.7 |
Longform Writing | no tools | 73.8 | 71.4 | 79.8 | 62.8 | 72.5 |
HealthBench | no tools | 58.0 | 67.2 | 44.2 | 43.8 | 46.9 |
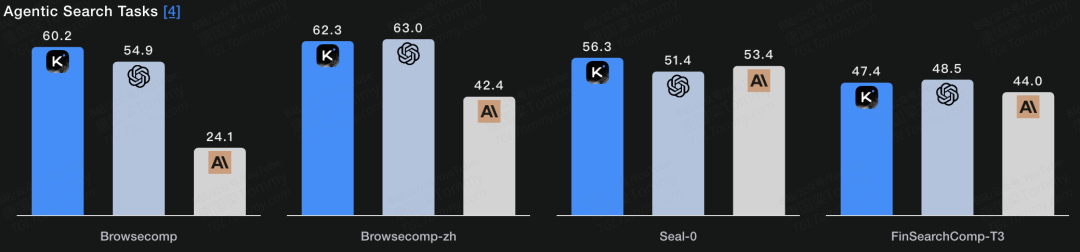
Agentic Search Tasks(左滑查看完整信息)
Benchmark | Setting | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|
BrowseComp | w/ tools | 60.2 | 54.9 | 24.1 | 7.4 | 40.1 |
BrowseComp-ZH | w/ tools | 62.3 | 63.0* | 42.4* | 22.2 | 47.9 |
Seal-0 | w/ tools | 56.3 | 51.4* | 53.4* | 25.2 | 38.5* |
FinSearchComp-T3 | w/ tools | 47.4 | 48.5* | 44.0* | 10.4 | 27.0* |
Frames | w/ tools | 87.0 | 86.0* | 85.0* | 58.1 | 80.2* |
Coding Tasks(左滑查看完整信息)
Benchmark | Setting | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|
SWE-bench Verified | w/ tools | 71.3 | 74.9 | 77.2 | 69.2 | 67.8 |
SWE-bench Multilingual | w/ tools | 61.1 | 55.3* | 68.0 | 55.9 | 57.9 |
Multi-SWE-bench | w/ tools | 41.9 | 39.3* | 44.3 | 33.5 | 30.6 |
SciCode | no tools | 44.8 | 42.9 | 44.7 | 30.7 | 37.7 |
LiveCodeBenchV6 | no tools | 83.1 | 87.0* | 64.0* | 56.1* | 74.1 |
OJ-Bench (cpp) | no tools | 48.7 | 56.2* | 30.4* | 25.5* | 38.2* |
Terminal-Bench | w/ simulated tools (JSON) | 47.1 | 43.8 | 51.0 | 44.5 | 37.7 |
5.4 智能代理能力的落地形式
K2 Thinking 在“代理型任务”中展现强势:如“网页浏览+知识检索+工具使用+编程”组合任务。
案例来源 : https://moonshotai.github.io/Kimi-K2/thinking.html
案例-1 : Component-heavy Website
案例-2 : Math Explainer
案例-3 : Simulation of virus attacking cells in bloodstream
六、总结与展望
Kimi K2 Thinking 不再是一个单纯的语言模型,而是一个功能强大、可开源部署的智能代理核心。
它通过 “MoE 架构 + Agentic 训练 + 原生量化” 的技术路线,成功地在模型规模、推理性能和运行效率之间取得了精妙的平衡。
• 架构:1T MoE、32B 激活、64个注意力头、160k 词表。
• 训练:MuonClip 优化器实现15.5T Tokens 零损失尖峰;Data Rephrasing 提升词元效率。
• 智能:大规模智能体数据合成;RLVR 与自评奖励相结合的 RL 框架。
• 部署:原生 INT4 QAT;支持200-300步的超长工具调用链。
Kimi K2 极大地推动了开源模型在复杂任务自动化领域的发展,将模型的能力从“对话”提升到了“行动”的层次。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号