一文读懂 Intern-S1:为何它能成为科学领域最强的开源多模态大模型?

一文读懂 Intern-S1:为何它能成为科学领域最强的开源多模态大模型?

唐国梁Tommy
发布于 2026-06-25 21:09:18
发布于 2026-06-25 21:09:18
在过去几年里,我们见证了大型语言模型(LLM)的爆发式增长。从GPT系列到各种开源模型,它们在通用对话、编程、数学解题等领域的能力已经让人叹为观止。然而,AI领域存在一个公开的秘密:这些模型在真正硬核、高度专业的科学研究领域,表现往往不尽如人意。
这篇来自上海人工智能实验室的论文,《Intern-S1: A SCIENTIFIC MULTIMODAL FOUNDATION MODEL》,正是为了攻克这一难题而来。它不仅发布了一个名为Intern-S1的全新模型,更系统性地展示了一套将AI从“通才”培养成“科学专才”的完整方法论。

开源AI在科学领域的“失语”困境
在深入技术细节之前,我们必须先理解Intern-S1试图解决的问题有多么重要。
问题的核心:数据稀疏与能力不均
AI模型的强大,源于海量数据的滋养。在通用领域,互联网提供了近乎无限的文本和图像数据。但在专业科学领域,情况截然不同:

1. 数据“低资源”:
高质量、结构化的科学数据(如精确的分子结构、实验记录、高能物理的碰撞数据)相比于网络上的猫猫狗狗图片和日常对话,数量上是九牛一毛。
2. 模态多样且复杂:
科学研究远不止于文本。它涉及图像(显微镜图像、天文图像)、符号(数学公式、化学方程式)、序列数据(基因序列、时间序列信号)等多种模态。如何让模型统一理解这些高度专业的“语言”,是一个巨大的挑战。
3. 推理链条长且严谨:
科学发现需要严密的逻辑推理、假设验证和实验设计。这要求模型具备超长的推理链条和高度的准确性,远非简单的问答可比。
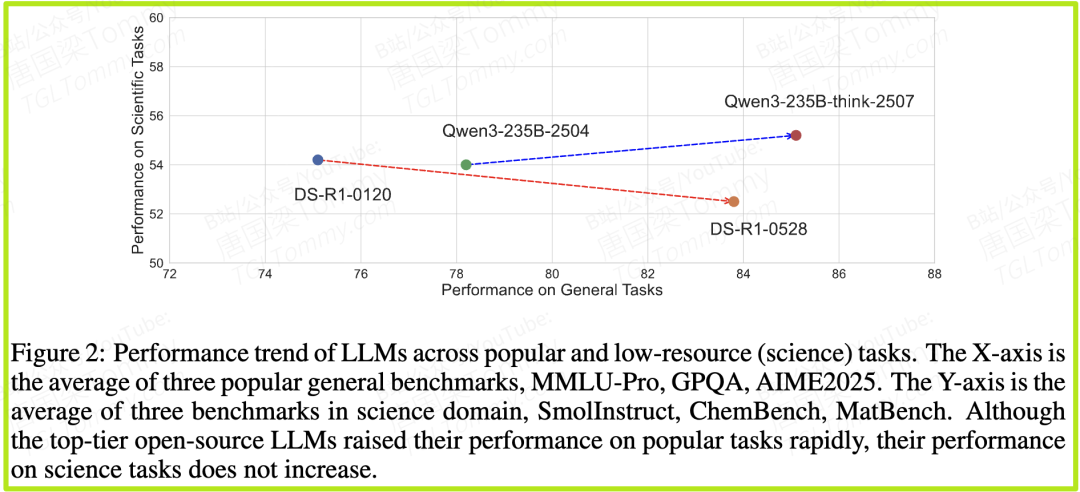
论文中的图2一针见血地指出了这个问题:尽管最顶尖的开源模型在通用任务(如MMLU-Pro、GPQA)上的性能不断攀升,但它们在科学任务(如SmolInstruct、ChemBench)上的表现却增长乏力,甚至陷入停滞。这表明,通用能力的提升,并不能自动转化为专业科学能力的增强。
Intern-S1,不止是一个更大的模型
Intern-S1的发布,带来了几个关键的创新点,它们共同构成了其强大的科学能力。
1. “通才-专才”一体化设计:
Intern-S1并非一个只懂科学的“偏科生”。它是一个拥有2410亿总参数(280亿激活参数)的庞大混合专家(MoE)模型,在训练之初就同时兼顾了通用知识和科学知识。这种设计确保了它在深入科学领域的同时,不会丧失与世界进行常识性交互和理解的能力。
2. 海量科学数据驱动:
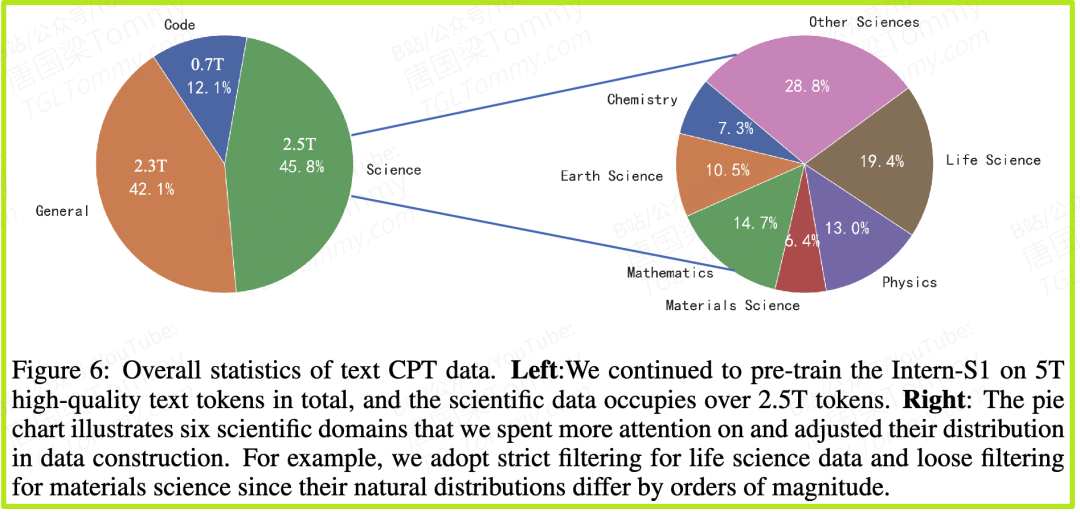
这是Intern-S1成功的基石。模型在总计5万亿(5T)tokens的数据上进行了持续预训练,其中超过一半(2.5T tokens)是专门搜集和清洗的科学数据。这个数据规模在开源科学模型中是前所未有的,为其注入了深厚的科学“血液”。
3. 架构层面的科学适配:
认识到科学语言的特殊性,Intern-S1在模型架构上进行了两项关键创新:
- • 动态分词器 (Dynamic Tokenizer):革命性地解决了标准LLM分词器处理科学符号(如化学式)效率低下的问题。
- • 多模态编码器:集成了强大的视觉和时间序列编码器,使其能直接“阅读”科学图像和信号数据。
4. 先进的强化学习框架:
为了让模型从“知道”科学知识,进化到“会用”科学知识解决问题,Intern-S1采用了一套名为 “奖励混合 (Mixture-of-Rewards, MoR)” 的强化学习框架。该框架能在一个统一的流程中,同时对超过1000种不同类型的任务进行优化,效率极高。
简单来说,Intern-S1的成功秘诀可以归结为:海量的专业数据 + 为科学优化的模型架构 + 高效的“能力训练”方法。接下来,我们将逐一拆解这些技术细节。
深入Intern-S1的技术“引擎室”
这一部分是技术含量最高,也是最精彩的。我们将深入探索Intern-S1是如何从模型、数据、训练三个层面构建起来的。
1. 模型架构:为科学“语言”量身定制
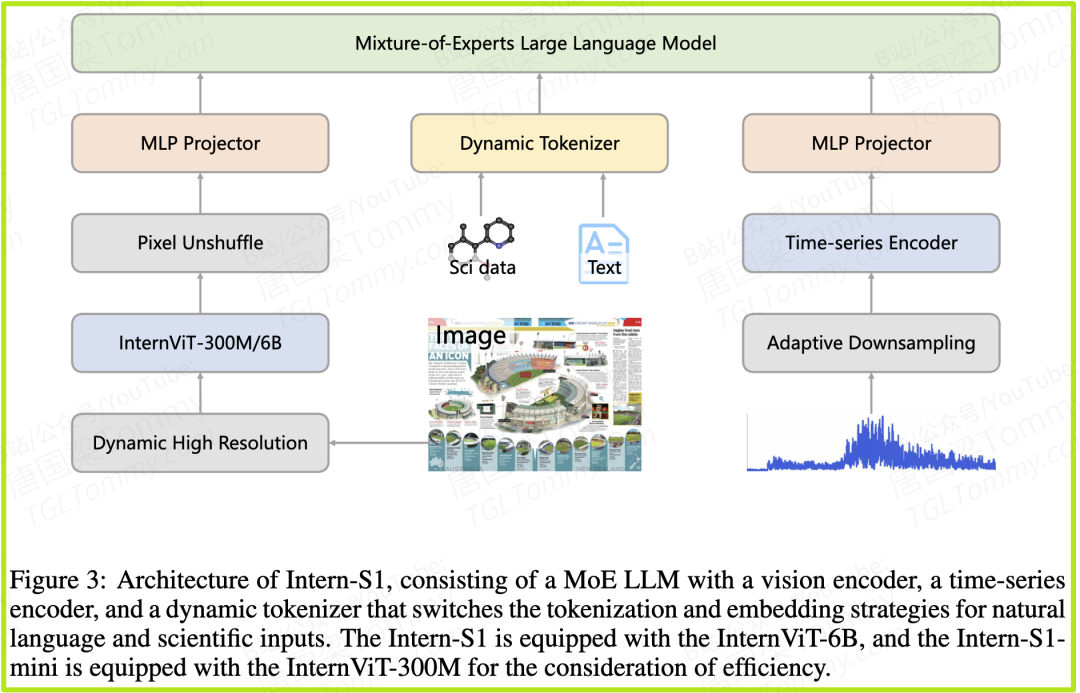
Intern-S1的架构是一个精心设计的多模态系统,其核心组件包括一个MoE语言模型、视觉编码器、时间序列编码器,以及最具创新性的动态分词器。
动态分词器 (Dynamic Tokenizer):让模型真正读懂“化学文”
这是理解Intern-S1的关键。标准的分词器(Tokenizer)是LLM的“眼睛”,它负责将文本切分成模型能理解的最小单元(token)。但这些分词器通常是为自然语言设计的。当它们遇到像化学中的SMILES分子式(例如C1CCCCC1代表环己烷)时,就会水土不服。
- • 传统方法的困境:标准分词器会把
C1CCCCC1拆成'C','1','C','C'... 这样的单个字符。这极其低效,就像让一个只懂英语的人去逐个字母地背诵化学式,完全无法理解其结构含义。这不仅浪费了大量的计算资源,也阻碍了模型学习其内在的化学规律。 - • Intern-S1的解决方案:动态分词器则像一个聪明的“多语言专家”。当它读到一段文本时,会首先进行“语言识别”。1️⃣模式检测:它会通过预设的规则或者特殊的标签(如
<SMILES>...</SMILES>)来判断某段字符串是自然语言、SMILES分子式,还是FASTA蛋白质序列。 2️⃣切换“词典”:一旦识别出这是一段SMILES分子式,它就会切换到一个专门为SMILES设计的“化学词典”(即专用的分词策略)来进行分词,将有意义的化学基团作为一个整体。 3️⃣统一表示:最后,它将不同部分(自然语言、化学式等)经过各自最优分词后的token序列拼接起来,送入模型。
论文中的图4用数据证明了这一设计的优越性。在处理SMILES数据时,Intern-S1的分词器压缩比达到了2.64,而其他主流模型(如Qwen3, DeepSeek-R1)仅在1.5左右。这意味着Intern-S1可以用远少于对手的token来表示相同的化学信息,效率提升超过70%!这在处理动辄数万亿token的预训练中,节省的计算成本是惊人的。

视觉与时间序列编码器:超越文本的“感知力”
- • 视觉编码器 (Vision Encoder):Intern-S1采用了强大的InternViT-6B模型作为“眼睛”,能够处理高分辨率的科学图像。一个有趣的技术细节是Pixel Unshuffle,它能巧妙地将图像块的像素重排,从而在不丢失信息的前提下,将视觉token的数量缩减为原来的1/4,大大降低了处理图像的计算负担。
- • 时间序列编码器 (Time Series Encoder):这是一个专门为处理连续信号数据(如地震波、脑电图、天文光变曲线)设计的模块。它能捕捉数据中的时间依赖性,并将其压缩成LLM能够理解的表征。
这套多模态架构,使得Intern-S1成为了一个能够同时处理文本、图像和时间序列数据的“六边形战士”,为解决复杂的跨模态科学问题奠定了基础。
2. 数据策略:构建科学知识的“大教堂”
如果说架构是骨架,那么数据就是血肉。Intern-S1在数据工程上的投入,堪称“史诗级”。
分层级PDF解析:兼顾成本与质量的艺术
科学知识主要沉淀在海量的PDF论文中。但PDF的解析是个大难题,尤其是包含复杂公式、图表的页面。
- • 挑战:市面上的PDF解析工具,要么便宜但质量差(公式乱码),要么质量高但成本极其昂贵(例如使用强大的VLM模型逐页解析)。
- • Intern-S1的智慧流程 (图7):
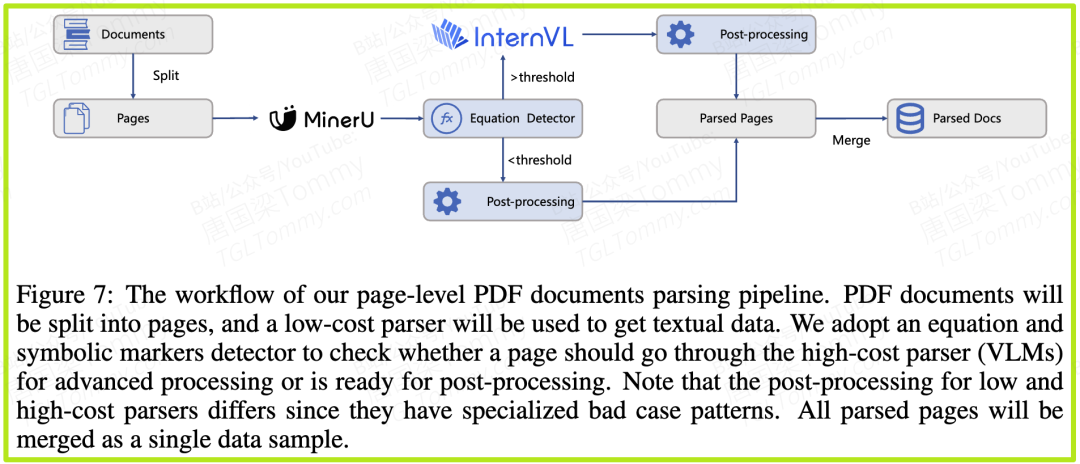
1️⃣初筛:首先用一个低成本、高速度的解析器(如MinerU)处理所有页面。
2️⃣“疑难杂症”检测:然后,用一个专门的检测器去识别哪些页面包含了大量的数学公式和符号标记——这些正是低成本解析器最容易出错的地方。
3️⃣专家会诊:只有这些被标记为“疑难”的页面,才会被送入一个高成本、高质量的VLM解析器(如InternVL)进行精细化处理。
4️⃣合并归档:最后,将两种解析结果进行后处理和合并。
通过这种“普通门诊+专家会诊”的分层策略,Intern-S1在保证了科学文献解析质量的同时,极大地控制了成本。数据显示,对于学术图书馆的文献,只有约5%的页面需要“专家会诊”,成本效益极高。
以领域为中心的Web数据解析:用AI来管理AI的数据
网络数据虽然庞大,但信噪比极低。如何从中淘出高质量的科学数据?
Intern-S1的“域名打包”策略 (图8):它不把网页当成独立的个体,而是以 网站域名(URL Domain) 为单位进行处理。
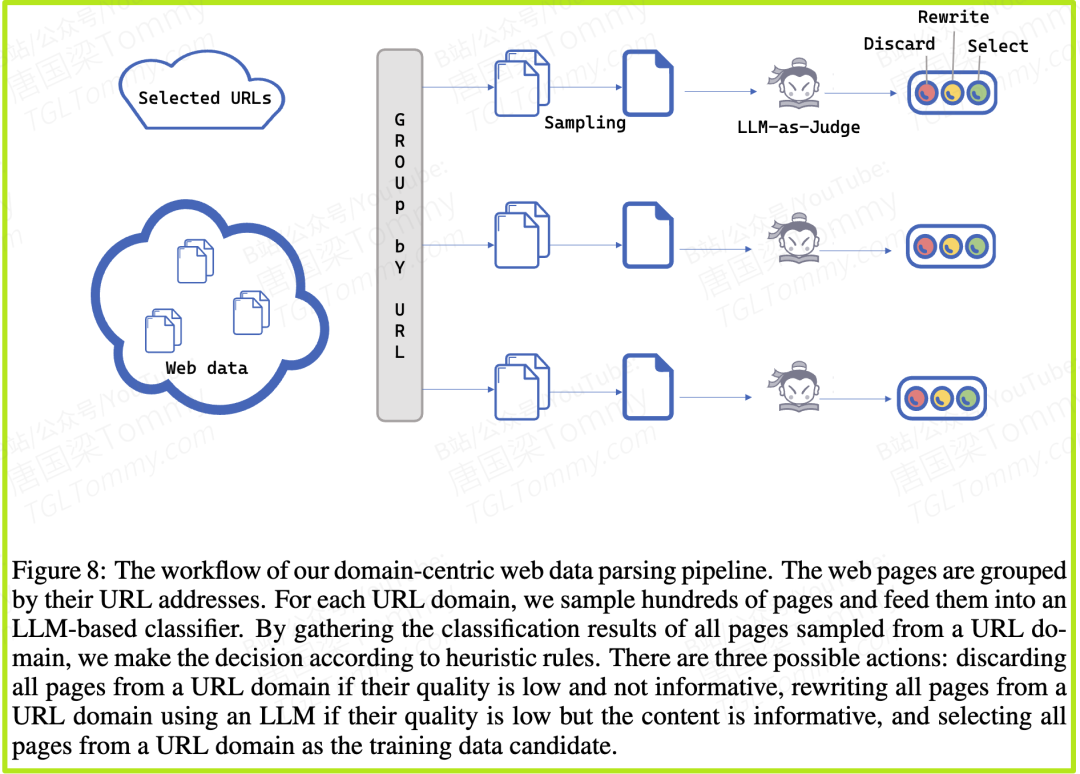
1️⃣抽样调查:对于一个网站(比如某个大学的物理系网站),系统会随机抽取几百个页面。
2️⃣LLM法官 (LLM-as-Judge):将这些抽样页面喂给一个强大的LLM“法官”进行质量评估,打上“高质量”、“低质量但内容有用”、“无用”等标签。
3️⃣批量决策:根据这个域名的整体评估结果,系统会做出统一决策:
- • 如果整体质量很高,就保留该域名下的所有页面。
- • 如果质量很差,就直接“拉黑”整个域名。
- • 如果内容有用但格式混乱,就调用一个LLM对该域名的所有页面进行统一的“重写”和“清洗”。
这种“先评审,后打包处理”的模式,使得数据处理的成本被大幅摊薄,能够以可接受的代价,对海量网络数据进行精细化管理。
3. 训练与后训练:从“博学”到“精通”
拥有了好的架构和数据,如何高效地训练模型,并激发其解决问题的能力,是最后也是最关键的一环。

多阶段训练与超参数优化
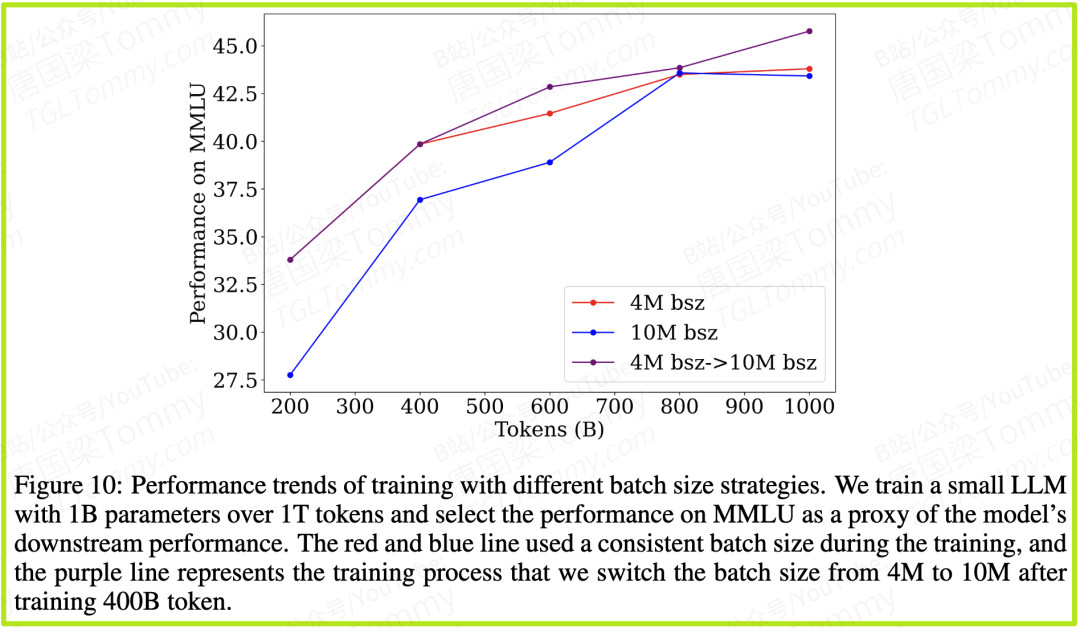
Intern-S1的训练过程井然有序,分为文本预训练、图文预训练、监督微调和强化学习四个阶段。其中一个有趣的发现是批量大小预热 (Batch Size Warmup)。研究团队通过实验(图10)发现,在训练初期使用较小的批量(Batch Size),模型性能更好;而在后期,切换到更大的批量则能提升训练效率。因此,他们采取了先小后大的策略,实现了性能和效率的双赢。
强化学习 (RL):为模型注入“灵魂”
预训练让模型变得“博学”,而强化学习则教它如何“致用”。Intern-S1的RL阶段是其成为科学问题解决者的关键。
奖励混合 (MoR) 框架 (图12):这是RL阶段的核心。面对数千种任务,如何设定奖励机制是一个难题。MoR框架将任务分为两类:
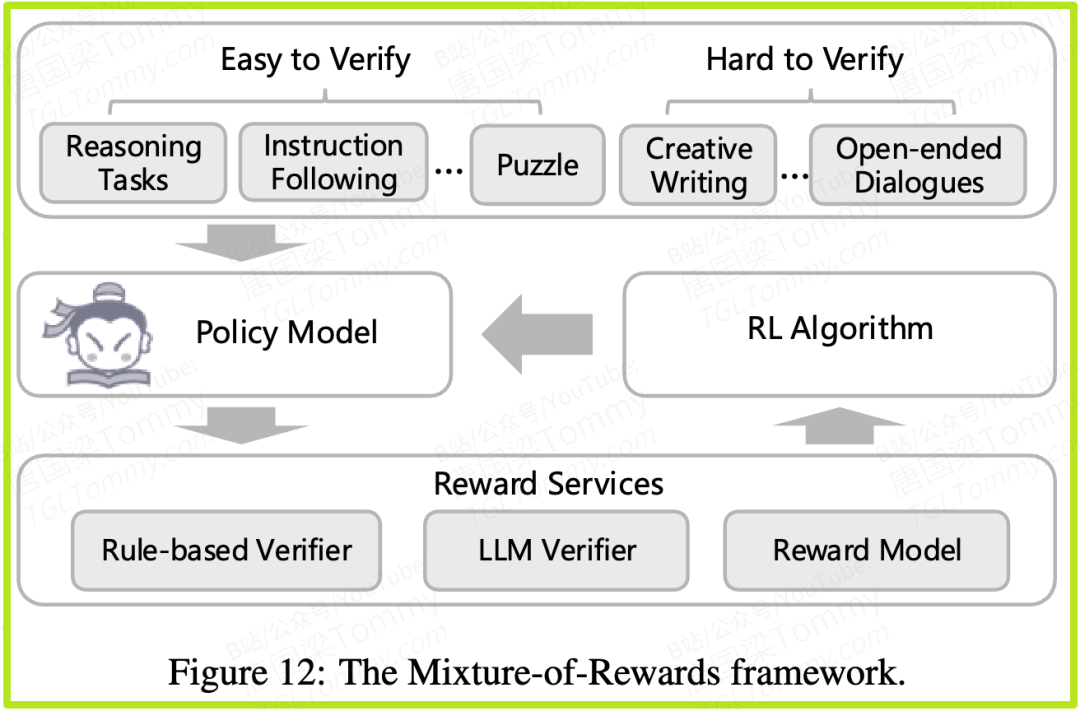
- • 易于验证的任务:如数学计算、代码生成。这类任务有明确的正确答案。MoR会使用一个验证器模型(LLM Verifier)或基于规则的检查器(Rule-based Verifier)来直接判断模型的输出是否正确,并给出奖励。
- • 难以验证的任务:如创意写作、开放式对话。这类任务没有标准答案。MoR会使用一个训练好的奖励模型(Reward Model),它能判断哪个回答更符合人类的偏好。
通过这个统一的框架,Intern-S1可以在一个训练流中,同时学习解决数学题、写代码、进行科学对话等多种技能。
- • 应对MoE模型的RL挑战:在MoE模型上进行RL训练尤其困难,因为其稀疏激活的特性会导致训练过程非常不稳定。团队采用了OREAL算法,并结合了KL散度约束。简单来说,就是在常规的RL损失函数之外,增加了一个“熵控制”项,防止模型在学习过程中过早地变得“固执己见”(即探索性下降太快),从而确保训练的稳定性和最终性能。其最终的损失函数形式如下: 这个公式包含了对“好”样本的学习(SFT loss)、对“坏”样本的惩罚(Policy Gradient loss),以及保持探索能力的熵控制项(KL-Cov loss),三者共同引导模型走向最优。
通过以上这一整套精密、环环相扣的方法论,Intern-S1被成功地锻造成为了一个面向科学发现的强大工具。
实验结果与分析:数据证明一切
Intern-S1在一系列通用和科学领域的权威基准测试中,交出了一份惊艳的成绩单。
1. 通用推理能力:跻身顶级,毫不逊色
在表2 (General Reasoning Benchmarks) 中,我们可以看到:
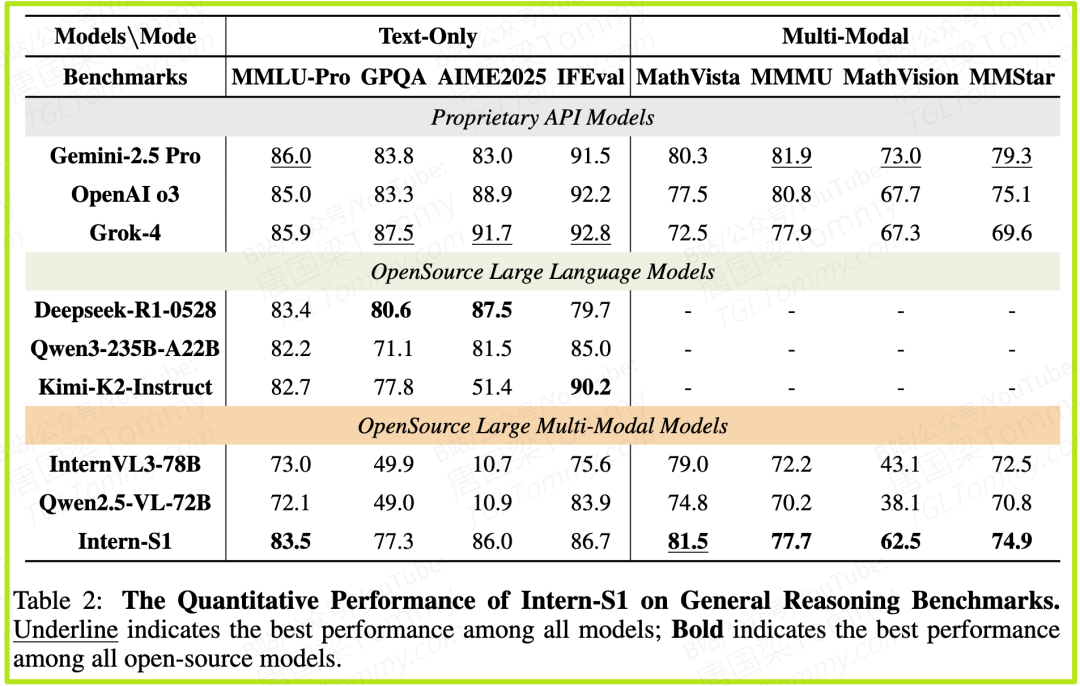
Intern-S1在所有8个通用基准上,都是表现最好的开源多模态模型。
在MMLU-Pro(83.5)和GPQA(77.3)等考验综合知识的测试中,它与最强的纯语言模型Deepseek-R1(83.4 / 80.6)不相上下。
在AIME2025数学竞赛(86.0)和MathVista视觉数学(81.5)上,它甚至超越了许多强大的对手,后者更是取得了全场最佳成绩。
这证明了Intern-S1的“通才-专才”设计是成功的。它在专攻科学的同时,没有以牺牲通用能力为代价。
2. 科学推理能力:断层式领先,定义新标杆
这部分是Intern-S1真正大放异彩的地方。
纯文本科学任务 (表3):
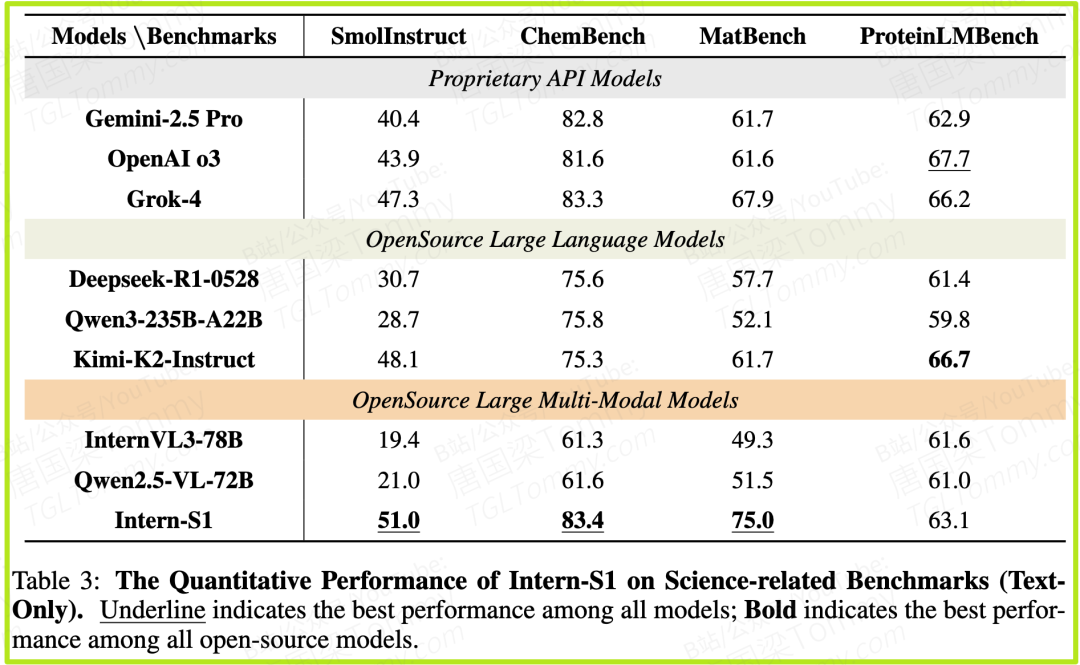
- • 在SmolInstruct(化学)、ChemBench(化学)和MatBench(材料科学)这三个基准上,Intern-S1不仅是开源模型的第一,甚至超越了所有顶尖的闭源模型。
- • 尤其是在MatBench上,它的得分高达75.0,而之前的开源模型最高只有49.3(InternVL3-78B),闭源模型最高为67.9(Grok-4)。这是一个巨大的飞跃,充分展示了其在材料科学领域的深厚积累。
多模态科学任务 (表4):
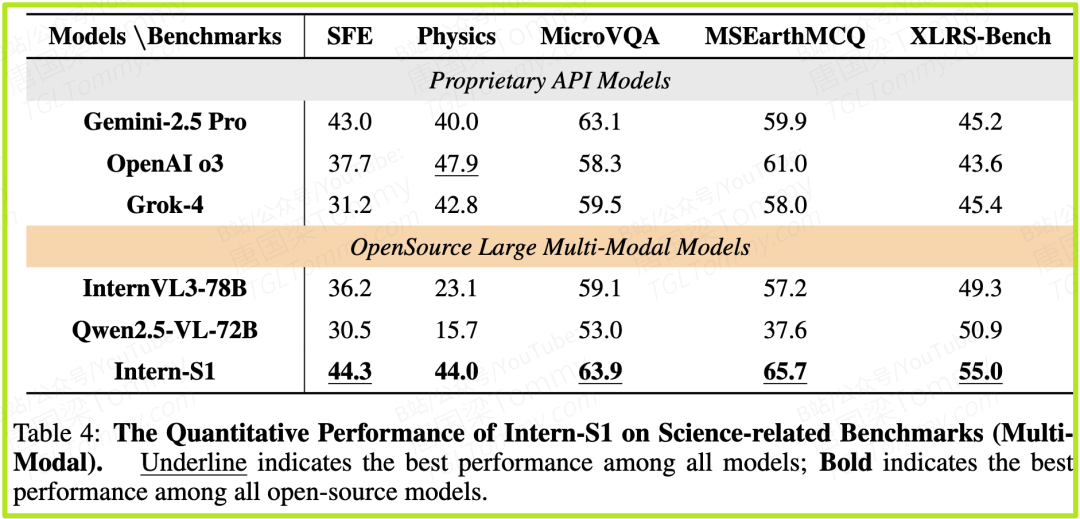
- • 在5个多模态科学基准中,Intern-S1在SFE(科学家第一视角考试)、MicroVQA(显微镜图像问答)、MSEarthMCQ(地球科学)和XLRS-Bench(遥感图像) 这4个任务上取得了全场最高分。
- • 例如,在MSEarthMCQ上,Intern-S1得分65.7,而强大的Gemini-2.5 Pro和OpenAI o3分别为59.9和61.0。
这些数据无可辩驳地证明,Intern-S1成功地弥合了开源模型在科学领域的性能鸿沟,并在多个细分方向上树立了新的SOTA(State-of-the-art)标准。 其在数据和架构层面的创新,被证明是极其有效的。
总而言之,Intern-S1不仅仅是一个性能强大的新模型,它更像是一份详细的“蓝图”,告诉我们如何系统性地构建一个能够深入科学腹地的AI。它标志着开源AI力量在硬核科研领域的一次华丽“亮剑”,也让我们离“AI科学家”的梦想,又近了一步。
论文名称:Intern-S1: A Scientific Multimodal Foundation Model
第一作者:上海 AI Lab
论文链接:https://arxiv.org/abs/2508.15763
最新日期:2025年8月21日
github:https://github.com/InternLM/Intern-S1.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号