ollama v0.30.9更新详解:Cohere2Moe支持落地,LFM2思维链解析修复,超长上下文报错机制上线

ollama v0.30.9更新详解:Cohere2Moe支持落地,LFM2思维链解析修复,超长上下文报错机制上线

福大大架构师每日一题
发布于 2026-06-24 15:42:30
发布于 2026-06-24 15:42:30
在这里插入图片描述
在这里插入图片描述
在这里插入图片描述
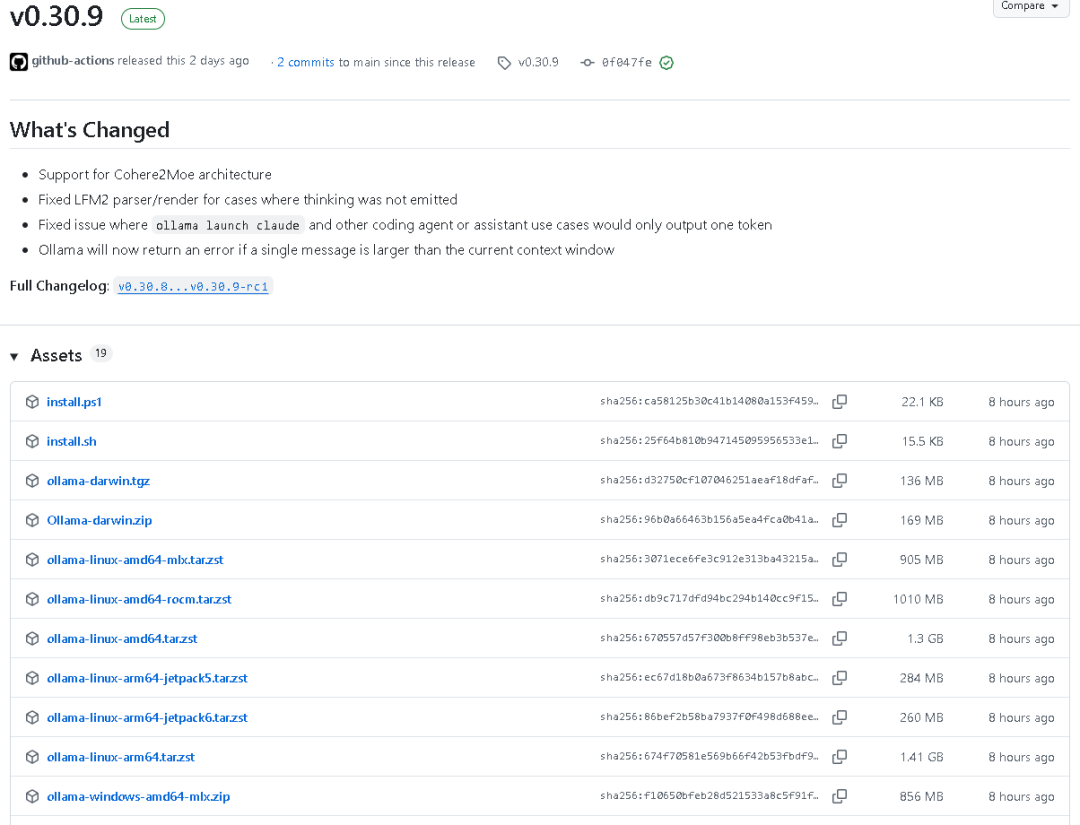
2026年6月17日,ollama 发布了 v0.30.9 最新版本。 从这次发布信息来看,虽然版本号只是一次常规迭代,但实际改动并不小,覆盖了模型架构支持、LFM2 解析与渲染修复、ollama 在启动 Claude 及其他 coding agent 或 assistant 场景下只输出一个 token 的问题修复,以及单条消息超过当前上下文窗口时直接返回错误的新机制。
从变更规模来看,本次版本一共包含 3 次提交,涉及 16 个文件,1 位贡献者,总代码层面为 280 行新增、103 行删除。 如果从工程角度看,这不是一次简单的 bugfix,而是一轮围绕兼容层、解析器、渲染器、调度器以及 llama-server 行为约束的系统性修订。
一、本次版本官方变更摘要
v0.30.9 的核心更新点可以概括为四项:
- • 支持 Cohere2Moe 架构
- • 修复 LFM2 在未输出 thinking 时的 parser 和 renderer 行为
- • 修复 ollama 在 launch Claude 以及其他 coding agent、assistant 使用场景下只输出一个 token 的问题
- • 当单条消息大于当前上下文窗口时,ollama 现在会直接返回错误
这四项看起来很简短,但背后实际牵涉到了多个模块:
- • llama.cpp 兼容层补丁组织方式调整
- • LFM2 parser 状态机重构
- • LFM2 renderer 对 thinking 字段的重建逻辑完善
- • prompt 超长时不再截断,而是显式报错
- • context shift 的默认策略发生变化
- • 针对大于 8k 上下文窗口的 context shift 处理做了调整
二、提交与改动规模概览
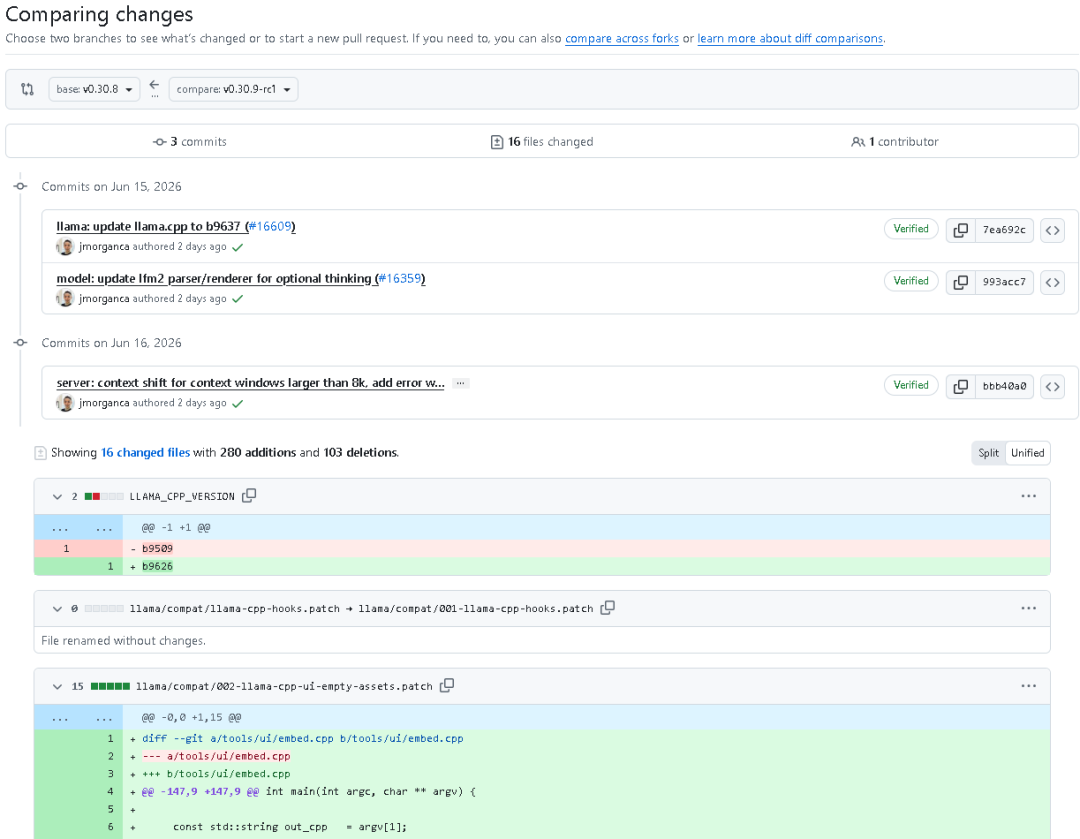
本次发布对应的提交时间集中在 2026年6月15日 和 2026年6月16日。
提交内容主要包括:
- • 更新 llama.cpp 到新版本
- • 更新 lfm2 parser 和 renderer,使 thinking 变为可选行为时也能正确处理
- • 调整 server 侧 context shift 策略,并新增上下文窗口超限错误处理
从 diff 信息看,本次更新共涉及这些方向:
- • 版本号调整
- • compat 补丁文件重命名和新增
- • compat 文档说明更新
- • patch 自动应用逻辑增强
- • laguna 架构兼容层修正
- • llama server prompt 长度处理逻辑变化
- • llama server 测试从“截断成功”改为“超限报错”
- • LFM2 parser 状态与流式解析行为大幅增强
- • LFM2 renderer 能够根据 Thinking 字段重建 think 标签
- • 调度器 context shift 默认决策逻辑改动
- • 多处测试同步更新
可以说,这个版本虽然改动文件数量不算夸张,但大部分都落在底层逻辑与边界行为上,因此对稳定性和兼容性影响非常直接。
三、支持 Cohere2Moe 架构:版本能力边界继续扩大
官方 changelog 的第一条就是:
- • Support for Cohere2Moe architecture
这说明 v0.30.9 新增了对 Cohere2Moe 架构的支持。 虽然在用户给出的 diff 片段中,没有展开 Cohere2Moe 具体实现文件的完整细节,但这项支持已经明确列入本次版本变更说明,意味着在模型架构适配层面,ollama 的兼容能力又向前推进了一步。
结合本次 compat 层的组织方式调整,可以看出新增架构支持并不是零散加入,而是继续沿用“补丁加兼容实现”的方式推进。这一点从 compat 目录的变更就很明显。
四、llama.cpp 版本更新:底层依赖继续前进
本次有一个很基础但很重要的变化,就是 LLAMA_CPP_VERSION 从:
- • b9509
更新为:
- • b9626
也就是说,ollama v0.30.9 所依赖的 llama.cpp 版本进一步推进了。
这类变更的重要性在于,很多上层能力其实并不完全由 ollama 自己独立实现,尤其是模型加载、架构识别、UI 辅助工具、服务行为等,都会受到底层 llama.cpp 版本的直接影响。 因此,兼容层补丁、架构注册、工具链修复、上下文行为调整,往往都需要围绕这个版本基线同步演进。
这也是为什么本次更新里,compat 层相关文件变更这么集中。
五、compat 层补丁命名方式调整:从单补丁走向有序补丁集
本次一个非常明显的工程化调整,是补丁文件命名发生了变化。
原来的:
- •
llama/compat/llama-cpp-hooks.patch
现在重命名为:
- •
llama/compat/001-llama-cpp-hooks.patch
同时,新增了一个补丁文件:
- •
llama/compat/002-llama-cpp-ui-empty-assets.patch
此外,原来的:
- •
llama/compat/models/llama-cpp-laguna.patch
也重命名为了:
- •
llama/compat/models/003-llama-cpp-laguna.patch
这说明 compat 层已经从“某个单一补丁文件”的思路,转向“按数字顺序执行的一组补丁”的思路。 这个变化在文档和 CMake 逻辑中也有完整呼应。
原本 README 中对 patch 的说明,还是强调某一个 hooks patch。 更新后则明确指出:
- • 使用数字文件名顺序来应用补丁
- • 该目录下的所有
*.patch都会按数值顺序执行 - • 包括 hooks patch 和各个 models 架构 patch
这个变化的重要性非常高,因为它让 compat 层从“零散 patch”变成“可维护的 patch pipeline”。
也就是说,后续新增架构、修补 UI 工具、加 loader hooks,不需要继续把所有修改塞进一个 patch 文件里,而是可以按顺序拆分成多个补丁,既方便维护,也方便判断哪一步出问题。
六、新增 UI 空资源补丁:没有前端资源时也能生成空资产表
新增补丁 002-llama-cpp-ui-empty-assets.patch 的内容比较明确,修改的是:
- •
tools/ui/embed.cpp
改动核心有两点:
- •
asset_dir不再强制要求必须传入第三个参数,而是当argc == 4时才使用argv[3],否则设为空字符串 - •
use_gzip的判断增加了asset_dir非空校验
也就是:
原来逻辑默认认为一定存在资源目录。
现在则允许资源目录为空,并在这种情况下依然正常执行,只是不会去寻找 _gzip 目录。
这与 README 中新增的描述完全一致:
- • 让 llama.cpp UI embed helper 在没有 UI assets 的情况下,也能生成一个空的 asset table
这个改动的实际意义是:
在某些构建环境下,如果没有准备 UI 静态资源,以前可能会因为 embed 流程强依赖 asset 目录而出错。 而现在,构建过程可以在“无 UI 资源”条件下继续进行,自动生成空资源表,增强了构建兼容性和可移植性。
七、compat 文档更新:清楚界定补丁层与新架构层
llama/compat/README.md 的更新,不只是名称替换,而是对整个 compat 设计意图进行了更清晰的说明。
几个关键信息包括:
- •
001-llama-cpp-hooks.patch是在 llama.cpp 文件中增加小范围、附加式调用点的补丁 - •
002-llama-cpp-ui-empty-assets.patch用于在没有 UI assets 时生成空资产表 - •
compat.cmake和apply-patch.cmake用来按数字顺序应用当前目录下所有 patch - •
models/目录是“新增架构层”,用于补充 llama.cpp 暂不支持的新架构 - • 上层 compat 文件主要负责“翻译和适配”,而 models 目录里的文件主要负责“新增架构”
这个描述非常关键,因为它帮助开发者理解:
- • 哪些 patch 是 llama.cpp 钩子层的
- • 哪些 patch 是架构扩展层的
- • 为什么要按顺序应用
- • 哪些文件是 Ollama 自己持有的 compat 逻辑
从工程维护角度说,这类文档更新的价值不低,因为它减少了后续继续迭代时的理解成本。
八、补丁应用脚本增强:按文件名排序,日志更清晰,失败信息更精准
llama/compat/apply-patch.cmake 这次修改非常值得关注。
核心变化包括:
- • 明确所有 patch 会按数字文件名顺序应用,而不仅仅是简单遍历
- • 先构造
_patch_entries,每个元素包含“文件名和完整路径” - • 对
_patch_entries排序后,再逐个提取PATCH_FILE - • 日志输出从笼统的“patch already applied, skipping”变为显示具体相对路径
- • 应用成功日志从“applied patch”变为“applied 某个具体 patch”
- • 出错日志也从输出完整路径,变成输出相对路径,信息更聚焦
这几个调整看似细碎,实际对构建调试帮助很大。
以前如果目录里 patch 变多,单看“已跳过”或者“已应用”很难知道是哪一个。 现在会明确显示具体的 patch 相对路径,问题定位成本明显下降。
另外,原逻辑虽然也能处理 *.patch,但现在进一步强调并落实了“按数字文件名顺序执行”的机制,这和补丁重命名成 001、002、003 形成了严格配套。
九、compat.cmake 同步更新:补丁文件路径改为新的编号名称
llama/compat/compat.cmake 的改动不多,但作用很明确:
- • 注释从“单个小 patch file”改成“小型有序 patch 集”
- •
OLLAMA_LLAMA_CPP_COMPAT_PATCH_FILE指向的新路径由llama-cpp-hooks.patch改成001-llama-cpp-hooks.patch
这意味着整个构建系统已经正式接受新的补丁命名规则,旧文件名不再是主路径。
十、laguna 兼容层修正:调用参数从成员变量改为方法
llama/compat/models/003-llama-cpp-laguna.patch 与 llama/compat/models/laguna.cpp 也有更新。
在 laguna.cpp 中,这一行发生了变化:
- • 原来使用
hparams.n_layer - • 现在改为
hparams.n_layer()
也就是:
ml.get_key_or_arr("laguna.attention.layer_types", hparams.is_swa_impl, hparams.n_layer(), false);
这通常意味着 n_layer 的访问方式发生了接口层调整,或者是需要通过方法而不是直接成员访问来获得层数。
虽然只是单行改动,但这种变化往往是为了适配底层结构定义变更,避免编译或运行时不一致。
同时,patch 文件重命名到 003 也说明 laguna 架构 patch 现在纳入统一的顺序补丁集管理。
十一、llama server prompt 处理逻辑变化:从自动截断改为直接报错
这次更新中,最值得用户关注的改动之一,就是 llm/llama_server.go 的 prompt 长度处理策略变了。
此前逻辑是这样的:
- • llama-server 拒绝恰好填满整个 slot context 的 prompt
- • 为尽量兼容旧 runner 行为,会预留 1 个 token 空间
- • 如果 token 数超过限制,就按
NumKeep保留前部,再丢弃中间一段,拼接尾部 - • 最终生成一个被截断后的 token 序列
- • 并记录 truncating input prompt 的 warning 日志
而在 v0.30.9 中,这套逻辑被彻底删除,改为:
- • 以
s.options.NumCtx作为当前 runner 的有效上下文长度 - • 这个值在 launch 阶段已经被模型训练上下文长度所限制
- • 如果
len(tokens) >= s.options.NumCtx,则直接返回一个api.StatusError - • 错误码是
http.StatusBadRequest - • 错误信息是:
the prompt is longer than the context length currently available to the model; shorten the prompt or adjust the context length in settings
也就是说,现在不再偷偷帮你截断输入,而是明确拒绝超限 prompt。
这个变化非常重要,因为它代表设计思路发生了变化:
- • 旧逻辑强调“尽量兼容并兜底”
- • 新逻辑强调“明确边界并主动报错”
这样做的优点是:
- • 用户不会在不知情的情况下丢失部分 prompt token
- • coding agent、assistant 这类对上下文完整性敏感的场景更稳定
- • 调试 prompt 失败原因时更直观
- • 避免被截断后模型行为异常却难以察觉
这也与 changelog 中“当单条消息大于当前上下文窗口时会返回错误”完全一致。
十二、对应测试同步改变:不再测试截断,而是测试拒绝请求
llm/llama_server_test.go 的测试名称也直接改了:
- • 从
TestLlamaServerCompletionTruncatesPromptAsTokens - • 改为
TestLlamaServerCompletionRejectsPromptOverContext
这说明测试意图已经完全变化。
新的测试重点验证:
- • 超长 prompt 会返回指定错误
- • 错误类型必须是
api.StatusError - • 状态码必须是
400 Bad Request - • 错误消息必须与预期完全一致
- •
/completion接口不应该被调用
也就是说,当 tokenized prompt 已经超过上下文长度时,流程会在进入 completion 前就被拦截掉。
旧测试里还会检查被截断后的 token 数组是否符合预期,例如保留哪些 token。 这些检查现在全部删除,因为新的行为已经不再是“截断后继续生成”,而是“直接拒绝”。
这个改动对使用者来说非常关键,特别是依赖长 prompt、长 system message 或长上下文拼接的应用,要开始适应“超限显式报错”的新规则。
十三、修复 ollama 启动 Claude 等 coding agent 只输出一个 token 的问题
官方 changelog 中还有一条非常关键:
- • Fixed issue where ollama launch claude and other coding agent or assistant use cases would only output one token
虽然用户给出的 diff 片段没有单独展开这条问题在某个具体文件中的完整上下文说明,但结合本次上下文处理与 context shift 策略调整,可以看到该问题已经作为本版本核心修复项之一被明确列出。
也就是说,这次更新除了提升稳定性和兼容性,还直接修复了某些 assistant、coding agent 典型场景下输出异常短、只生成一个 token 的问题。 对于依赖这类场景的用户,这个修复价值非常直接。
十四、LFM2 parser 重大修复:thinking 现在是真正“可选”的了
本次版本中,LFM2 parser 的修复是最系统的一部分之一。 核心目标就是修复“模型没有输出 thinking 时”的解析行为。
以前逻辑中的初始状态是:
- •
LFM2CollectingThinking
这意味着一旦 thinking 功能开启,parser 会默认认为模型会进入 thinking 采集模式。
但现实问题在于,LFM2 模型并不是每次都会输出 <think> 标签。
有些回合会直接回答,没有显式思维段。
因此这次新增了一个全新的初始状态:
- •
LFM2LookingForThinking
它的注释写得很清楚:
- • 当 thinking 启用时,这是初始状态
- • LFM2 模型只有在真正进行推理时才会输出显式
<think>标签 - • 如果是直接回答,则根本不会有这个标签
- • 因此 parser 在一开始要先观察输出到底是不是以
<think>开头,再决定后续进入 thinking 还是 content 采集状态
这实际上是在修复一个非常本质的问题:
- • 不能因为“启用了 thinking”就假设“模型一定会输出 thinking 标签”
十五、LFM2 初始化逻辑变化:不再默认进入 thinking 采集
在 setInitialState 中,原来当 thinking 启用时会做两件事:
- •
p.state = LFM2CollectingThinking - •
p.needsThinkingLeadingTrim = true
而现在改为:
- •
p.state = LFM2LookingForThinking
注释说明得也很明确:
- • thinking 已启用
- • 但模型是否进行 reasoning 是按 turn 决定的
- • 要等待一个前导
<think>标签 - • 如果没有,就把后续作为 direct answer 处理
这个改动让 parser 的初始化行为更符合 LFM2 的真实输出模式。
十六、LFM2 在最终 chunk 的处理更聪明:不再无意义等待不完整 think 标签
Add 方法里新增了一段重要逻辑:
- • 当
done为 true,且当前状态仍然是LFM2LookingForThinking - • 会把 buffer 左侧空白去掉
- • 如果去掉空白后并不是以
<think>开头 - • 就将其直接视为 content
- • 重置 buffer 并切换到
LFM2CollectingContent
这意味着:
如果流式输出已经结束,但 parser 还在犹豫“会不会出现 think 标签”,那么到了最后一个 chunk,它必须做出判断。
而只要最终并没有形成 <think> 前缀,就不能继续把内容扣在缓冲区里,而要把它当作直接回答释放出来。
这对于 direct answer 场景尤其关键,避免了 thinking 模式下正常回答被错误吞掉或延迟输出。
十七、LFM2 状态机新增分支:显式区分 reasoning turn 和 direct answer turn
在 eat() 中,新增了 LFM2LookingForThinking 分支,逻辑非常完整:
- • 先忽略前导空白
- • 如果以
<think>开头,就切入LFM2CollectingThinking - • 如果当前只有空白,或者只是
<think>的部分前缀,比如<th,则继续等待更多数据 - • 如果已经足够判断不是
<think>,那就认定这是 direct answer - • 重置 buffer,把去掉前导空白后的内容作为 content 继续处理
这个设计非常适合流式场景,因为流式输出里标签经常会被拆开分片,比如:
- •
<th - •
ink>
以前如果 parser 没有中间态,就很容易误判。 现在它会在“部分前缀”阶段保持等待,在“足够判断不是 think 标签”时立即切到 direct answer。
十八、LFM2 测试全面补强:大量样例围绕“没有 thinking 标签”的情况展开
model/parsers/lfm2_test.go 这次增加和调整了大量测试用例,几乎可以看作对 parser 行为的重新校验。
重点变化包括:
- • 过去多个“thinking_content”类测试输入中,缺失开头
<think>标签,现在统一补上 - • 新增
direct_answer_with_thinking_enabled- • 输入是直接答案
- • 即使 thinking 启用,也应正确解析为 content
- • 新增
direct_answer_with_tool_call- • 没有 think 标签,直接内容后面跟 tool call
- • 应正确提取普通内容和工具调用
- • 新增
streaming_direct_answer- • 流式直接回答应在 thinking 模式下也正常输出
- • 新增
streaming_thinking_split_open_tag- • 开始标签拆分在多个 chunk 中,也必须正确识别
- • 新增
streaming_direct_answer_starting_with_angle- • 当直接回答以
<开头时,前期会与<think>存在歧义 - • 必须等到足以排除
<think>后再输出为普通内容
- • 当直接回答以
- • 初始化测试中,期望状态从
LFM2CollectingThinking改成LFM2LookingForThinking - • 边界测试中,
empty_thinking_content被改成empty_thinking_block- • 输入由单独
</think>改为合法的<think></think>Just content
- • 输入由单独
- • 新增
direct_answer_with_leading_whitespace- • direct answer 前导空白会被处理掉
这些测试变化说明,本次修复不是打补丁式地修一两个条件判断,而是把 LFM2 thinking 机制按“可选思考、可直接回答、支持流式拆标签”的真实行为重新梳理了一遍。
十九、LFM2 renderer 修复:可从 Thinking 字段重建 think 标签
除了 parser,model/renderers/lfm2.go 也有明显增强。
这次先新增了两个常量:
- •
lfm2ThinkingOpenTag = "<think>" - •
lfm2ThinkingCloseTag = "</think>"
最关键的逻辑新增是:
当满足以下条件时:
- •
r.IsThinking为 true - • 当前消息角色是
assistant - •
message.Thinking不为空 - •
content中又还没有包含</think>
则会自动把 content 重建为:
- •
<think>+ Thinking +</think>+ content
官方注释写得也非常清楚:
- • 从分离的 Thinking 字段中重建 inline 的
<think>...</think>块 - • 让 reasoning turn 能以模型自己的原始格式 round-trip
- • thinking 应位于 tool calls 和 content 之前
- • direct answer 因为没有 Thinking 字段,所以不会添加标签
- • 非 thinking renderer 永远不应发送 think 标签,即使是末尾 assistant prefill 也不行
这个变化说明,renderer 现在能更正确地处理“消息对象里的 Thinking 字段”和“模型原始模板里的 think 标签”之间的转换关系。
二十、过去 assistant 消息的 reasoning 清理逻辑同步调整
此前 renderer 就有一段逻辑,用于在不保留历史 thinking 时,去掉旧 assistant 消息中的 reasoning 内容。
不过那时是直接查找字面量 </think>。
现在逻辑更统一了:
- • 使用
lfm2ThinkingCloseTag - • 注释说明 reasoning 是一个干净的前缀块
- • 去掉 close tag 之前的所有内容后,tool calls 和 content 可以完整保留
这个改动配合前面的“Thinking 字段重建”就很顺了:
- • 先按需要把 Thinking 字段重建回
<think>...</think> - • 再根据是否保留历史 thinking 决定要不要剥离旧轮次 reasoning
这样不仅逻辑更统一,也避免了 thinking 信息在多轮历史中的格式不一致问题。
二十一、LFM2 renderer 测试新增多种关键场景
model/renderers/lfm2_test.go 这次增加了大量测试,重点围绕“Thinking 字段重建”和“是否保留历史 thinking”两个问题。
新增的重要测试包括:
- •
thinking_field_reconstructed_when_enabled- • 当 renderer 开启 thinking,且消息带有 Thinking 字段时,输出应重建
<think>reason</think>
- • 当 renderer 开启 thinking,且消息带有 Thinking 字段时,输出应重建
- •
thinking_field_stripped_for_non_last_when_disabled- • 当不保留过去 thinking 时,非最后一个 assistant 的 reasoning 应被剥离
- •
thinking_precedes_tool_calls- • thinking 必须位于 tool call 之前
- •
direct_answer_history_has_no_think_tags- • direct answer 的历史消息不应平白出现 think 标签
- •
non_thinking_renderer_drops_thinking_metadata_on_prefill- • 非 thinking renderer 即使遇到带 Thinking 字段的 assistant prefill,也绝不能输出 think 标签
- •
arbitrary_roles_are_rendered_verbatim- • 任意角色应按原样渲染
这些测试与 parser 侧的修复共同说明: v0.30.9 不是只修“解析”,而是把“解析”和“渲染”两个方向都对齐了,保证有 thinking 和没 thinking 的两类 LFM2 输出都能闭环工作。
二十二、server 调度策略变化:context shift 默认行为被重新定义
server/sched.go 的改动,是本次另外一个核心变化。
之前存在一个常量:
- •
contextShiftSmallContextLimit = 8192
旧的 resolveContextShift 逻辑是:
- • 如果用户显式设置了
shift,就以它为准 - • 否则只有在
numCtx > 0 且 numCtx < 8192时,默认启用 context shift
也就是说:
- • 小上下文默认 shift
- • 大于等于 8k 的上下文默认不 shift
而现在,这整套逻辑被简化成:
- •
resolveContextShift(shift *bool) bool { return shift == nil || *shift }
也就是:
- • 未设置时,默认启用
- • 显式 false 时关闭
- • 显式 true 时开启
不再依赖上下文长度,也不再区分是否大于 8k。
这就是 changelog 中“context shift for context windows larger than 8k”的关键落地点。 它意味着对于更大的 context window,默认策略不再自动禁用 shift,而是统一按“默认开启、除非明确关闭”的方式处理。
二十三、多处 context shift 计算同步改造:不再传入 numCtx
由于 resolveContextShift 的签名变了,调度流程中多个调用点也全部更新:
- •
getRunner中不再传opts.NumCtx - •
load中不再传effectiveModelContext(launchOpts.NumCtx, f) - • 已加载 runner 回写
req.opts.NumCtx后,也不再用effectiveNumCtx再判断 shift - •
needsReload中也不再依据optsNew.NumCtx重新推导 context shift
简而言之,现在 context shift 的决定权只取决于:
- • 用户是否显式传了
shift
如果没有显式关闭,那么默认就是开。
这使得调度逻辑更简单,也减少了不同上下文大小下行为不一致的问题。
二十四、context shift 测试同步重写:从“小上下文启用、大上下文禁用”改为“默认启用”
server/sched_test.go 的测试也对应重写了。
旧测试覆盖的是:
- • 小上下文默认启用
- • 大上下文默认禁用
- • 非法上下文默认禁用
- • 显式 false 覆盖默认
- • 显式 true 覆盖默认
新测试改成只验证三种情况:
- • 未设置时默认启用
- • 显式 false 禁用
- • 显式 true 启用
这意味着“8192 这个阈值”在行为层面已经不再是决策依据。
二十五、本次更新如何理解:不是加功能那么简单,而是在统一边界行为
把所有改动串起来看,v0.30.9 的价值并不只是新增了某个模型架构,或者修了一个 parser bug。 它更像是在统一几个关键边界:
- • 构建兼容层如何按顺序组织和应用
- • 没有 UI 资源时构建是否还能通过
- • LFM2 在“有 thinking”和“没 thinking”之间如何稳定切换
- • renderer 如何把 Thinking 字段还原成模型模板需要的标签格式
- • prompt 超长时是悄悄截断还是明确报错
- • context shift 是否还要受 8k 上下文阈值影响
这些看似分散,但本质上都围绕一件事:
- • 让 ollama 的行为更确定、更可解释、更接近真实模型输出与运行边界
二十六、本次版本所有重点变更清单汇总
为了便于快速复盘,可以把 v0.30.9 的变更完整总结为以下内容:
- • 发布时间为 2026年6月17日
- • 本次发布为 v0.30.9
- • 支持 Cohere2Moe architecture
- • 修复 LFM2 在未输出 thinking 时的 parser 和 renderer
- • 修复 ollama launch claude 以及其他 coding agent、assistant 场景下只输出一个 token 的问题
- • 当单条消息大于当前上下文窗口时,ollama 会直接返回错误
- • 共 3 次提交
- • 共 16 个文件变更
- • 共 1 位贡献者
- • 共 280 行新增、103 行删除
- •
LLAMA_CPP_VERSION从 b9509 更新到 b9626 - •
llama-cpp-hooks.patch重命名为001-llama-cpp-hooks.patch - • 新增
002-llama-cpp-ui-empty-assets.patch - •
llama-cpp-laguna.patch重命名为003-llama-cpp-laguna.patch - • compat README 改为强调数字顺序 patch 集
- • patch 应用脚本新增按文件名顺序应用、日志更清晰、失败信息更精确
- • compat.cmake 中 patch 路径同步更新
- •
embed.cpp支持没有 UI assets 时生成空资产表 - •
laguna.cpp中hparams.n_layer改为hparams.n_layer() - • llama server 不再对超长 prompt 自动截断,而是直接报 400 错误
- • 新错误文案明确提示缩短 prompt 或调整上下文长度设置
- • completion 超限测试从“截断成功”改为“请求被拒绝”
- • LFM2 parser 新增
LFM2LookingForThinking初始状态 - • thinking 启用时不再默认认为一定有 think 标签
- • 流式解析中支持拆分
<think>开标签 - • 对 direct answer、tool call、前导空白、角括号起始内容等场景新增测试
- • LFM2 renderer 新增 Thinking 字段重建
<think>...</think>逻辑 - • thinking 内容优先于 tool calls
- • 非 thinking renderer 不会输出 think 标签
- • 历史 assistant thinking 剥离逻辑更统一
- • context shift 解析逻辑从依赖上下文大小改为默认启用
- • 大于 8k 上下文窗口也不再默认关闭 context shift
- • 调度器和测试全部同步到新策略
二十七、结语
代码地址:github.com/ollama/ollama
如果只看 changelog,ollama v0.30.9 似乎是一次“支持新架构加若干修复”的常规更新。 但从具体 diff 来看,这个版本真正有价值的地方在于,它对多个底层边界行为做了统一和纠正:
- • 兼容层补丁管理更规范
- • 构建链在无 UI 资源时更稳
- • LFM2 thinking 机制终于真正兼容“可能有思考,也可能没有思考”的实际输出模式
- • renderer 与 parser 形成更完整的双向闭环
- • prompt 超限从隐式截断转为显式报错
- • context shift 的默认策略也变得更直接一致
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号