MarkItDown:把测试资料变成 AI 可读 Markdown,知识库和 RAG 才能少踩坑

MarkItDown:把测试资料变成 AI 可读 Markdown,知识库和 RAG 才能少踩坑

沈宥
发布于 2026-06-24 15:09:27
发布于 2026-06-24 15:09:27
很多团队做 AI 知识库或 RAG 问答时,第一步就容易做错:直接把 PDF、Word、PPT、Excel 一股脑丢进系统,然后开始调 Prompt、换向量库、换模型。
但实际问题常常不在模型,而在原始资料没有被整理成稳定、可解析、可回归的文本资产。
测试团队手里通常有大量这类资料:
- PRD、接口文档、测试方案
- 缺陷复盘、上线 checklist
- Excel 用例、PPT 评审材料
- PDF 规范、Word 操作手册
这些文件如果不能稳定转成结构化文本,后面的检索、问答、用例生成都会变得不可靠。
Microsoft 开源的 MarkItDown 就是一个很适合测试团队关注的小工具。它不是一个花哨的 AI 应用,而是一个 Python 工具和命令行程序:把各种文件转换成 Markdown,方便 LLM、索引和文本分析流水线消费。
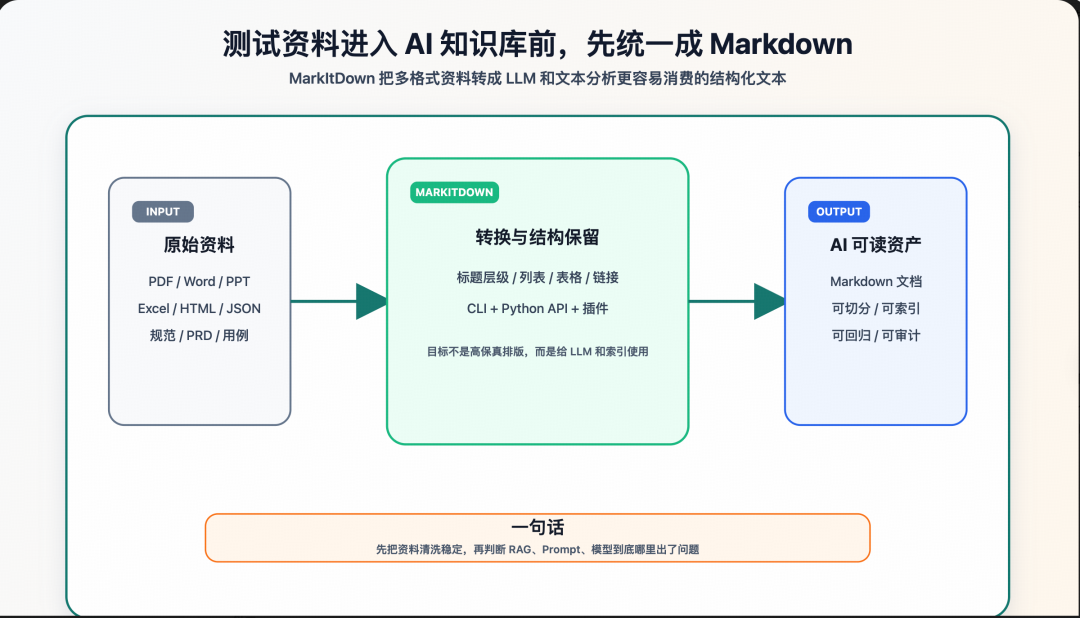
30 秒先看结论
如果你的团队正在做测试知识库、需求问答、用例生成、缺陷复盘检索,MarkItDown 值得先放进资料清洗链路。
它最适合解决三类问题:
- 多格式资料统一入口:PDF、Word、PowerPoint、Excel、HTML、CSV、JSON、XML 等都可以先转 Markdown
- 保留关键结构:标题、列表、表格、链接这些结构比纯文本更适合后续检索和 LLM 使用
- 批量处理更容易自动化:CLI 和 Python API 都能接进脚本、CI 或知识库构建流程
但它不是高保真排版转换工具。官方 README 也说得很清楚:输出虽然通常可读,但目标是供文本分析工具消费,不一定适合做人类阅读的精美文档。
一、它为什么适合测试团队?
MarkItDown 官方 README 对它的定位是:轻量 Python 工具,用于把各种文件转换成 Markdown,面向 LLM 和相关文本分析流水线。它强调保留重要文档结构,比如 headings、lists、tables、links。
这句话对测试团队很关键。
因为测试资料往往不是“纯文本”,而是很多结构化信息:
- 表格里有字段约束
- 标题里有模块层级
- 列表里有前置条件和验收点
- 链接里有接口文档和原型地址
如果转换后只剩一坨无层次文本,后续 AI 很容易答偏。
下面是当前 GitHub 仓库首屏,可以看到项目归属 Microsoft,README 也明确写了它面向 LLM 和文本分析流水线。
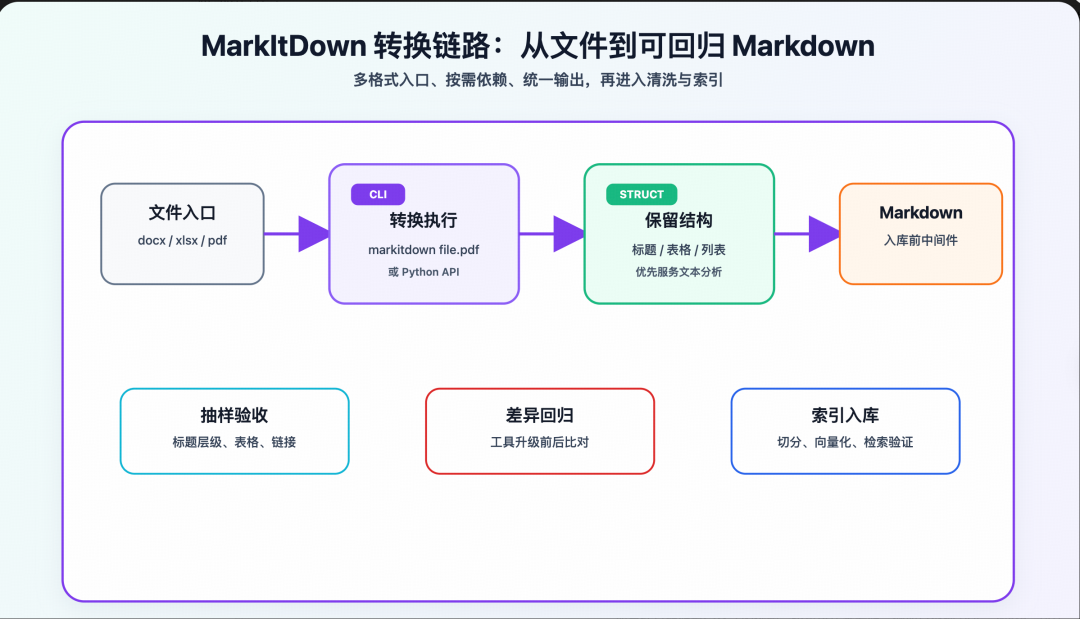
二、支持哪些资料类型?
根据官方 README,MarkItDown 当前支持的转换来源包括:
- PowerPoint
- Word
- Excel
- Images(EXIF metadata 和 OCR)
- Audio(EXIF metadata 和 speech transcription)
- HTML
- CSV、JSON、XML 等文本格式
- ZIP 文件
- YouTube URLs
- EPubs
对测试团队来说,优先级最高的一般是:
docx:需求文档、操作手册、测试方案xlsx:测试用例、接口字段表、兼容性矩阵pptx:评审材料、业务流程说明pdf:规范、外部接口文档、审计材料html/json/xml/csv:接口返回、配置、导出数据
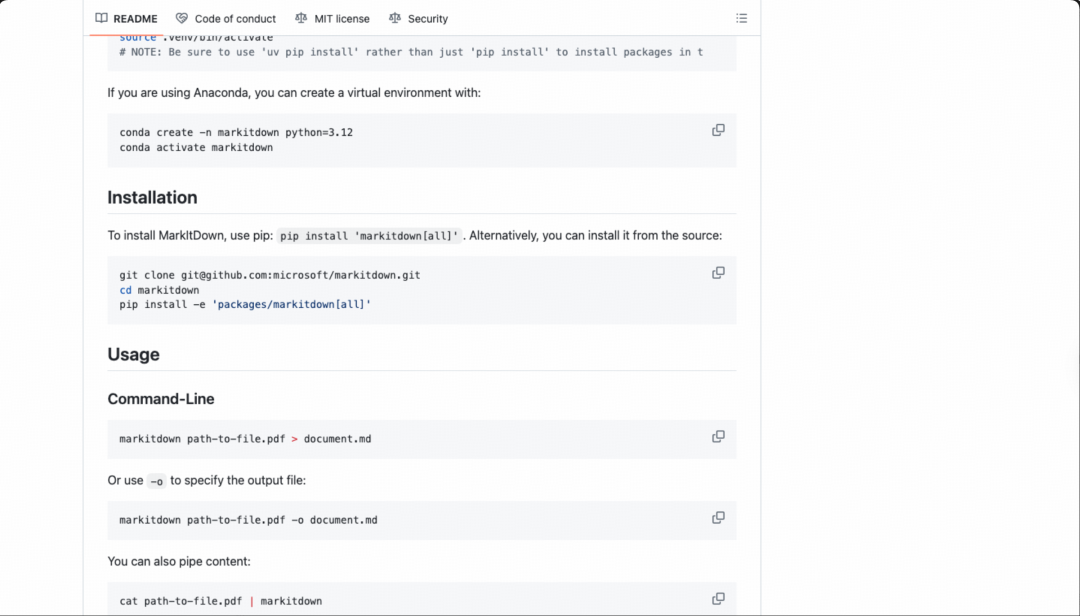
三、安装和最小使用方式
官方 README 给出的安装方式:
pip install 'markitdown[all]'
如果你只想装部分格式的依赖,也可以按需安装。例如只处理 PDF、Word、PPT:
pip install 'markitdown[pdf, docx, pptx]'
命令行转换一个 PDF:
markitdown path-to-file.pdf > document.md
指定输出文件:
markitdown path-to-file.pdf -o document.md
也可以通过管道输入:
cat path-to-file.pdf | markitdown
官方 README 里也给了 Python API:
from markitdown import MarkItDown
md = MarkItDown(enable_plugins=False)
result = md.convert("test.xlsx")
print(result.text_content)
下面这张截图是 README 的用法区,能看到命令行、可选依赖、插件和 Python API 这些入口。
四、测试团队怎么接进工作流?
不要把 MarkItDown 当成“单次转换工具”。它更适合放在知识库构建或测试资产整理流程里。
推荐链路是:
- 收集原始资料:PRD、用例、缺陷复盘、接口文档
- 用 MarkItDown 统一转成 Markdown
- 对 Markdown 做规则清洗:去目录、去页眉页脚、拆大文件、统一标题层级
- 进入索引、向量库或知识库
- 针对问答和用例生成结果做回归验证
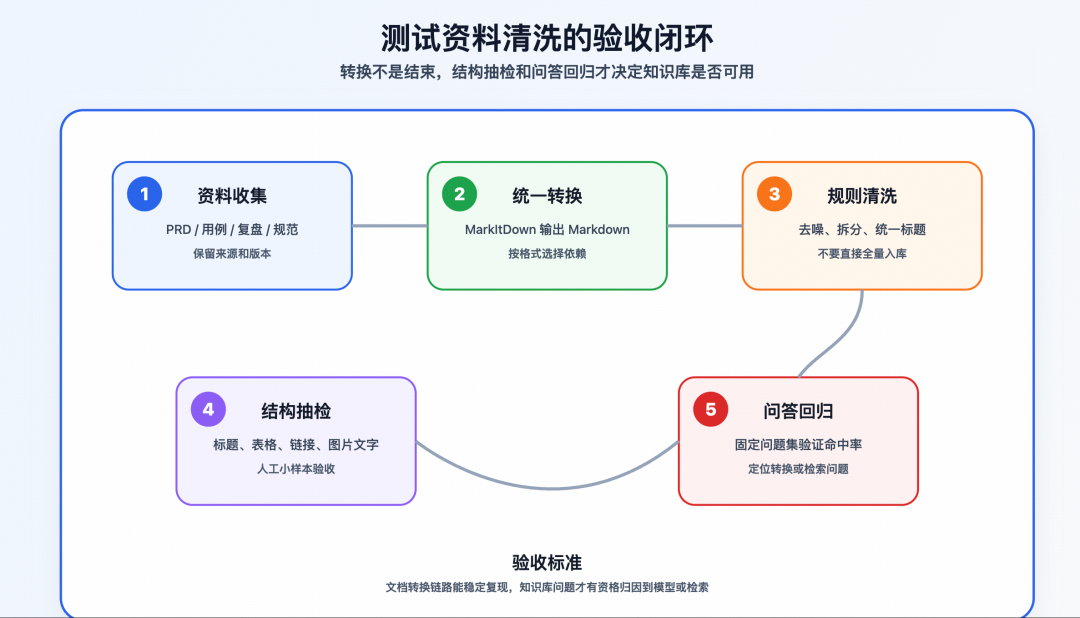
这里有两个细节很重要。
第一,转换后不要直接入库。你至少要抽样检查:
- 标题层级有没有乱
- 表格是否保留了关键列
- 跨页内容是否断裂
- 图片里的文字是否被漏掉
- Excel 多 Sheet 是否被正确表达
第二,转换结果要可回归。每次升级工具或换依赖后,固定拿一组样本文档重跑,比较 Markdown 输出差异。否则知识库结果变化时,你很难判断是模型问题、检索问题,还是文档转换问题。
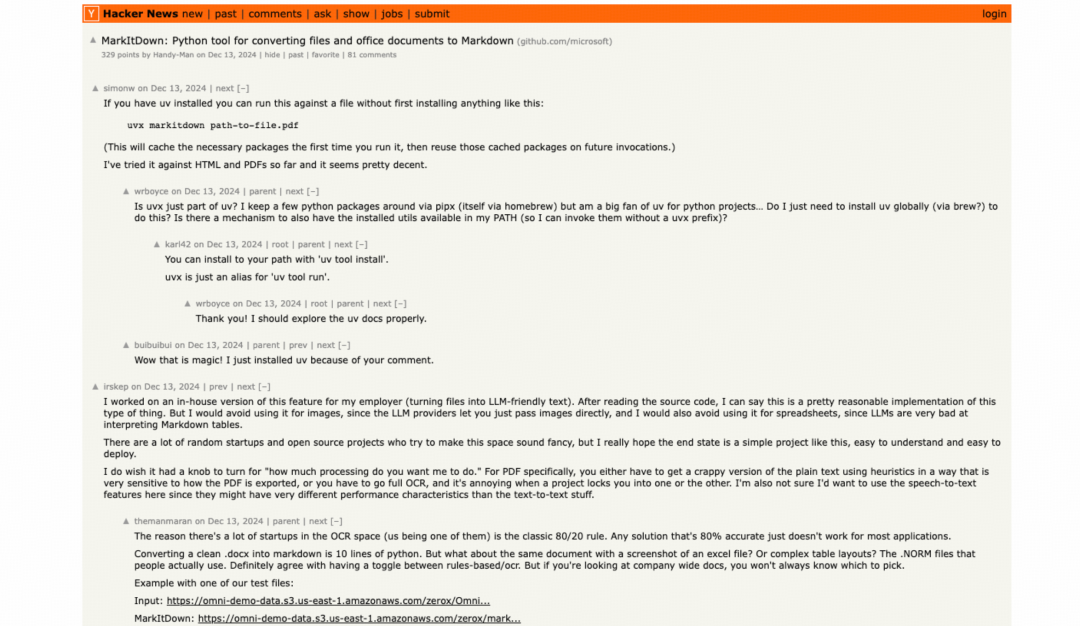
五、社区反馈怎么看?
MarkItDown 在 Hacker News 上曾有过讨论。截图里可以看到一些实际使用和对比观点,例如有人提到可以通过 uvx markitdown path-to-file.pdf 快速运行,也有人提醒 Markdown 不一定适合所有复杂表格场景。
这类反馈适合用来判断工具边界:它不是“万能解析器”,但在面向 LLM 的文本抽取和结构保留上很有现实价值。
注意:社区评论只能作为使用反馈样本,不能写成官方承诺。
六、它和 Pandoc、Docling 怎么区分?
如果你已经用过文档转换工具,可以简单这样区分:
工具 | 更适合的方向 | 测试团队视角 |
|---|---|---|
MarkItDown | LLM / 索引 / 文本分析前的数据转换 | 适合快速把多格式资料变 Markdown |
Pandoc | 通用文档格式转换,偏发布和排版 | 适合高质量文档格式互转 |
Docling | 文档理解、布局和复杂 PDF 解析 | 适合更重的文档处理链路 |
自研脚本 | 固定格式、强业务规则 | 适合只处理少数内部模板 |
我的建议是:
- 如果目标是 RAG 入库和 AI 分析,优先试 MarkItDown
- 如果目标是正式文档排版,继续看 Pandoc
- 如果目标是复杂 PDF、版面分析、扫描件,评估 Docling 或云端文档理解服务
- 如果内部文档格式很固定,再考虑自研规则
七、使用时的 5 个坑
- 不要把转换成功等于知识库可用
转换只是第一步,后面还要做清洗、切分、索引和问答回归。
- 复杂表格要重点抽检
Markdown 表格并不总是适合复杂 Excel。关键字段、合并单元格、多 Sheet 都要单独验。
- 图片和扫描件不要默认可读
如果资料里有大量截图、扫描页、嵌入图片,要关注 OCR 插件或其他文档理解方案。
- 不要忽略安全边界
官方 README 提醒 MarkItDown 会以当前进程权限进行 I/O。处理不可信输入时,要做隔离和权限收敛。
- 不要追求高保真排版
它的目标是给文本分析和 LLM 使用,不是还原 Word/PDF 的视觉效果。

八、一个 1 周试点方案
第 1 天:选样本文档
各选 3 份:PRD、Excel 用例、PPT 评审材料、PDF 规范。
第 2 天:批量转 Markdown
用同一脚本输出到固定目录,保留原文件名和转换日志。
第 3 天:人工抽样检查结构
重点检查标题、表格、列表、链接、图片文字。
第 4 天:接入知识库或向量索引
不要一次性全量导入,先用小集合验证问答质量。
第 5 天:建立转换回归集
固定一批样本文档,每次工具升级或入库规则变化后重跑对比。
九、总结
MarkItDown 不是一个“看起来很 AI”的工具,但它补的是 AI 知识库落地里非常基础的一环:
先把测试资料稳定地转成 AI 可读文本,再谈检索、问答和用例生成。
对测试团队来说,它的价值在于:
- 降低多格式资料进入知识库的门槛
- 保留标题、列表、表格、链接等关键结构
- 让资料清洗可以脚本化、可回归、可对比
- 避免把文档解析问题误判成模型能力问题
如果你们正在做测试知识库、RAG 问答、需求自动分析或用例生成,MarkItDown 值得作为“资料清洗入口”先试一轮。
参考资料:
- Microsoft MarkItDown GitHub:https://github.com/microsoft/markitdown
- MarkItDown PyPI:https://pypi.org/project/markitdown/
- MarkItDown OCR Plugin:https://github.com/microsoft/markitdown/blob/main/packages/markitdown-ocr/README.md
- Hacker News 讨论:https://news.ycombinator.com/item?id=42410803
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号