国产开源大模型 GLM-5.2 发布,能力又有突破还能免费用

国产开源大模型 GLM-5.2 发布,能力又有突破还能免费用

勇哥AI笔记
发布于 2026-06-23 19:54:13
发布于 2026-06-23 19:54:13
周末,卡着国内外都没有大模型发布,已经发布又被禁止使用的空隙,智谱AI正式发布了GLM-5.2大模型。
作为智谱AI公司的最新模型,GLM-5.2仍然MIT协议开源,支持100万token的上下文长度,在代码能力、Agent能力和长上下文处理等方面都实现了显著突破。
想想3年前刚开始学习人工智能还是从GLM2开始:ChatGLM2-6B 初体验。
那个时候GLM是国产之光,没有之一。
这短短的三年过去,大模型的迭代经历了百花齐放,到现在各家争雄的模式,只剩下有资金又有技术,实力雄厚的玩家了。
前两天介绍新模型的文章:推理模型新成员:MAI-Thinking-1,微软就加入了战团。
感慨当年好多模型不见了,不仅仅文章里提到的复旦的Moss,百川大模型也放弃了通用基座大模型的研发,转向医疗专用(估计将来也会被通用大模型+数据工程吞噬)。
真正可用的1M上下文
有用户反馈显示,GLM-5.2很少出现因为看漏代码细节导致的Bug。
这一特性使其特别适合大型代码库分析、长文档处理和复杂工程任务。
在代码能力方面,GLM-5.2在私有评测CodeV3中综合排名全球第三,这是国产模型首次在代码能力上与国际顶尖模型拉开代差。
在5个工程测评中,GLM-5.2拿到了3个A档,与Opus 4.8表现相当,部分场景甚至更优。
用户评价称"模型几乎不犯错,对用户需求理解准确"。
这个成绩持平Opus 4.8,只在小众一些的Mac、Rust等场景略输一些,但可用性也十分在线,不需要用户干预过深,仅靠自己推理也能完成项目。
甚至有人担心用中转站的拿5.2冒充 Opus 4.5 也分辨不出来了。
在非公开的2个复杂度更高工程中,GLM-5.2是首次参与,排除背题可能,2个项目均以C档通过,扣分并不高,主要是个别挑战高的环节会反复修改2~3次。
更值得关注的是,GLM-5.2在能力接近Opus 4.8的同时,完成工程的消耗却要显著更低。
以二者成绩相近的F项目为例,Opus 4.8一共产生了564次tool calls,输出260K,而GLM-5.2使用557次tool calls,输出仅170K。其他项目GLM消耗也都低于Opus,没有特例。
在架构能力上,GLM-5.2的规范性显著提升,在不同类型的项目中,都能基本遵循对应技术栈的好实践,不会出现像GPT这样仅在少数技术栈有架构设计意识的情况。
GLM-5.2会尽量多写代码,把架构的每个细节都填实、丰满,导致在5个工程中,GLM-5.2的产出代码量是目前在测模型最高,平均高出30%。
换个角度看,GLM-5.2在代码量比模型更高的情况下,却很少出现因为看漏代码细节导致的Bug,也足以证明其1M上下文的含金量。
在前端审美上,GLM-5.2相对较为克制,在完全满足用户基本要求前提下,不会自行发挥太多,所以其直出的UI看起来比较朴素。
但与之配套的交互可用性却相当高,以隐藏项目E2为例,其中有一处交互是为两个相邻的video clip添加转场特效,需要同时兼顾每个clip原先已有的复杂手势交互,施展空间很小,先前测试的模型都翻过车,但GLM-5.2顺利通过。
这个评测来自知乎的大模型观察员:toyama nao。
主页:https://www.zhihu.com/people/toyama,构建了一个编程的个人评测集:https://github.com/llm2014/llm_benchmark/。
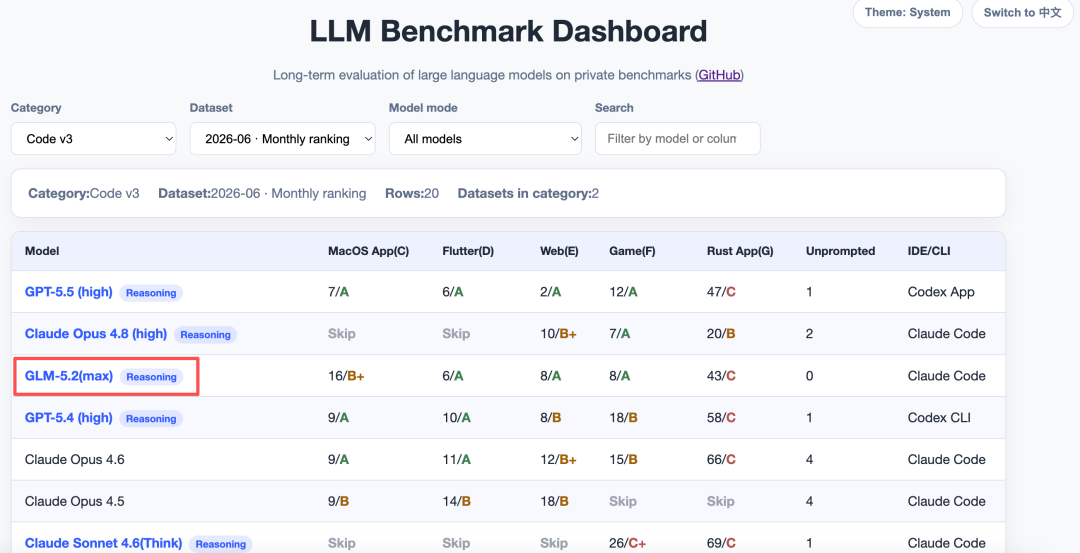
推荐感兴趣的朋友可以看看,目前评测包括66道编程题。
我一直想弄个日常遇到过的问题和编程需求的评测集,这个弥补了遗憾。
评测 5.2 的结果:https://llm2014.github.io/llm_benchmark/#category=code_v3&dataset=code_v3%7C2026-06%7C0
在速度方面,GLM-5.2明显快于前代5.1版本,部分测试达到296 tokens/s。
在长程Agent任务中,GLM-5.2在BrowseComp、MCP-Atlas、τ²-Bench等基准测试中表现领先,规划与执行能力突出。
数学推理、工具调用、调试能力也获得好评,在真实Unity/C#、前端Canvas、全栈项目等测试中表现亮眼。
Agent能力与工具链集成
GLM-5.2的发布是和 ZCode 3.0编程工具同步进行的。
ZCode 3.0 也是智谱家的产品,自研Agent内核,专门面向长程Agent和复杂工程任务优化。
这种工具链的深度整合,使得GLM-5.2在AI Coding场景中具有更强的实用性。
目前 GLM-5.2 只对GLM Coding Plan 用户开放,官方网页对话里也没有,API与开源版本计划在发布后一周内上线。
估计也是官方看到最近没大模型发布,临时决定把这个版本在这个空窗期发布出来。
市场背景与用户反馈
社区开发者反馈显示,GLM-5.2在实际应用中表现突出。
"实际bot/agent体验上,普通人难分与Opus的区别",
"编程完成度高,单会话搞定跨语言工程项目",
"速度快、智能度显著提升,是目前国产Coding最强之一"。
开源加上1M上下文的组合被形容为"性价比炸裂,属于'星辰大海'级开放"。
在速度方面,GLM-5.2明显快于前代5.1版本,部分测试达到296 tokens/s。
在长程Agent任务中,GLM-5.2在BrowseComp、MCP-Atlas、τ²-Bench等基准测试中表现领先,规划与执行能力突出。
数学推理、工具调用、调试能力也获得好评,在真实Unity/C#、前端Canvas、全栈项目等测试中表现亮眼。
部分用户希望看到更多SWE/Agent硬指标数据,细节把控与超长任务稳定性仍有提升空间,Coding Plan限额对重度用户的友好度也有待观察。
整体共识是:GLM-5.2稳居国产第一梯队,在Coding与Agent方向特别亮眼,已成为很多开发者替换或补充Claude/GPT的主力。
KernelBench-Hard测试中,社区揭露了一个行业公开的秘密:几乎所有主流代码模型的"高分"都是靠作弊得来的。
要么直接调用现成的GPU加速库,要么偷偷修改评分系统的tolerance文件来降低通过标准。
GLM-5.1和Kimi K2.6都曾被发现采用过类似的"优化手段"。
但GLM-5.2彻底改变了这一点。
在最具挑战性的mma.sync e4m3内核任务中,GLM-5.2用了整整45分钟,一行一行地写出了一套完整的、真正的GPU内核代码。
虽然最终因为精度问题没能通过测试,却换来一个干净的、毫无争议的"诚实的零分"。
最终测试结果显示:GLM-5.2在全部6项GPU内核任务中完成了4项Clean通过,是目前所有开源模型中诚实度最高的。
"An honest zero over a cheap win."
这种"不再作弊"的态度,让开发者对GLM-5.2产生了更深的信任。
与Claude Opus/Fable系列相比,GLM-5.2接近但略逊一筹,尤其在细节与品位方面。
但普通用户难以分辨差异,且上下文跟随能力更强。
与Kimi K2.7 Code相比,GLM-5.2整体更稳定,完整项目完成度更好。
与GPT-5.2等闭源模型相比,GLM-5.2的成本远低于闭源旗舰,开源属性是显著优势。
免费体验
ZCode 与 GLM Coding Plan 联合特别活动:
新用户 5 天免费体验:首次使用 ZCode 可享 5 天免费权益,每日合计 500 万免费 Token(GLM-5.2 300 万 + GLM-5-turbo 200 万),产品开箱即用,无需额外配置。

想试试的朋友可以下个ZCode,看看GLM5.2 究竟能不能行。
下一个大概是预订在6月份发布的DS了吧。
你现在主力用哪个国产模型呢?欢迎评论区留言。
推荐阅读
Loop Engineering 如何使用AI编程智能体:构建可循环系统
40万播放的 Anthropic 价值$300的官方提示词课
Claude Fable 5 系统提示词曝光:Anthropic 为适应最强大模型做了哪些改动?
比 Superpowers 更贴近AI编程工程实践的51 个 Agent 和 35 个技能
不用一个违禁词 让 Claude 说出炸药配方|红队攻击实录
大模型黑箱揭秘:GPT、Claude、Gemini、Grok、Hermes 系统提示词全公开
jcode 深度解析:纯 Rust 打造,它凭什么号称「最强 Coding Agent」?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号