大模型智能体能力工程化:基于SKILL的原子化拆分、标准化封装与依赖调度体系设计.143
原创
大模型智能体能力工程化:基于SKILL的原子化拆分、标准化封装与依赖调度体系设计.143
原创
未闻花名
发布于 2026-06-20 11:35:59
发布于 2026-06-20 11:35:59
一、核心概念
1. 传统智能体的瓶颈
在SKILL架构出现之前,大模型智能体就像一体式定制手机:所有功能(打电话、拍照、导航、聊天)都写死在系统核心代码里。
- 想加一个“翻译”功能,必须修改手机底层系统,还可能导致原有功能崩溃;
- 想复用拍照能力给第三方应用,完全做不到,因为代码和系统强绑定;
- 功能边界模糊:大模型不知道什么时候该查数据、什么时候该生成文本,经常出现逻辑混乱、数据错误。

这就是传统智能体的四大工程死穴:
- 1. 强耦合:能力与核心代码深度绑定,牵一发而动全身;
- 2. 难扩展:新增功能必须修改底层逻辑,开发周期长、风险高;
- 3. 难复用:每个智能体都是定制开发,能力模块无法跨项目、跨场景复用;
- 4. 难维护:功能迭代无独立版本,问题排查成本极高。
2. SKILL架构核心定义
SKILL 架构是面向大模型智能体的能力解耦与编排架构,核心是两大技术动作:原子化拆分 + 标准化封装。
原子化拆分:把智能体的所有能力,拆解成最小可用、功能闭环的独立单元(SKILL单元)。这种拆分遵循单一职责原则,确保每个单元只负责一个明确的功能领域。
标准化封装:给每个SKILL单元统一数据格式、触发规则、依赖管理,让所有能力像乐高积木一样自由拼接。标准化确保了不同技能间的互操作性和可复用性。
核心概念说明:
- 输入输出Schema校验:给数据定规矩,比如规定输入必须是“用户 ID + 日期”,输出必须是“JSON 格式的统计结果”,避免技能间数据乱码;
- 触发规则:大模型判断什么时候调用哪个SKILL,支持关键词、上下文、意图、置信度多维度匹配,不是简单的关键词匹配;
- 技能依赖链:多个SKILL按逻辑顺序调用,比如”数据采集→数据清洗→数据分析→报告生成“,前一个的输出是后一个的输入;
- 标准化组装:无需写核心代码,通过配置SKILL的组合方式,快速搭建新智能体。
SKILL单元结构:一个标准SKILL单元 = 输入校验 + 核心逻辑 + 输出校验 + 触发规则 + 依赖声明。
单元模块详细介绍:
- 1. 输入校验:定义和验证输入参数的类型、格式、必填项等
- 2. 核心逻辑:具体的业务处理逻辑
- 3. 输出校验:验证并格式化输出结果
- 4. 触发规则:定义何时以及如何调用此技能
- 5. 依赖声明:声明所需的前置技能或外部服务
SKILL单元特征:它可以是最小功能,如手机号校验,也可以是复杂任务,如多步骤数据分析,但必须满足以下特性:
- 边界清晰:每个技能都有明确的功能边界和责任范围
- 独立运行:不依赖其他非声明的外部状态或服务
- 可单独迭代:可以独立测试、优化和更新
3. SKILL架构优势
3.1 技术优势
- 模块化程度高:便于维护和升级
- 复用性强:同一技能可在不同场景下重复使用
- 测试友好:每个单元可以独立测试
- 扩展性好:新增功能只需添加新技能即可
3.2 业务优势
- 快速组装:通过组合现有技能快速构建新功能
- 风险隔离:单个技能故障不会影响整体系统
- 团队协作:不同团队可并行开发不同技能
- 成本优化:减少重复开发,提高开发效率
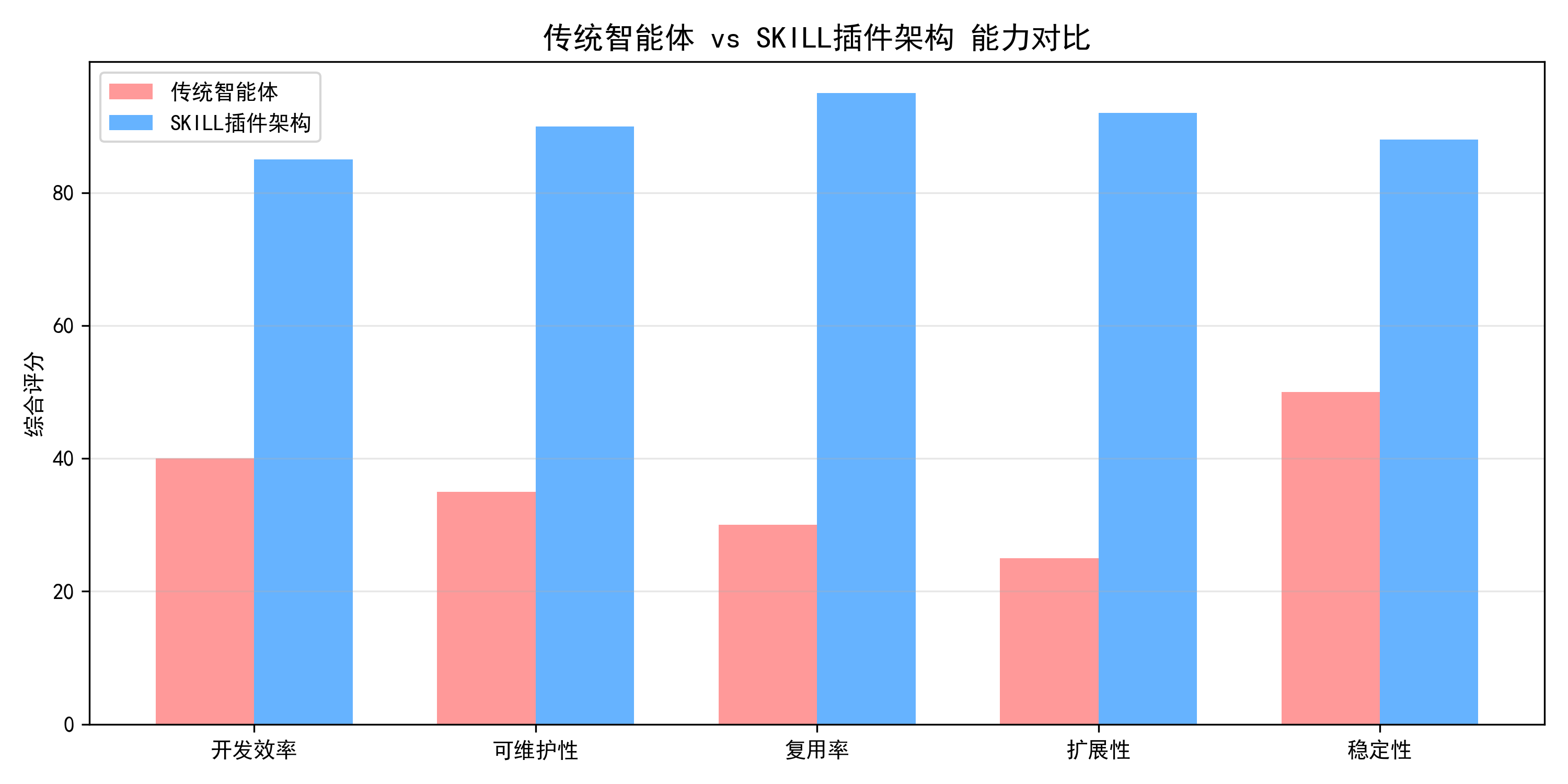
4. SKILL架构的核心价值
大模型本身是大脑,负责理解意图、生成逻辑,但不擅长执行具体功能、保证数据准确性。SKILL 架构给大模型装上了标准化手脚:
- 大模型只需要做决策:判断用户需要什么能力;
- SKILL 单元负责执行:精准完成具体功能,保证数据合规、逻辑正确;
- 最终实现:大模型通用能力 + SKILL 标准化能力 = 高可用、可工程化的智能体。
二、SKILL架构基础
1. 五大核心组件
1.1 原子SKILL单元:最小执行载体
- 定位:智能体能力的最小颗粒度,不可再拆分;
- 特性:功能闭环、独立运行、无外部依赖,是最基础SKILL;
- 示例:文本生成SKILL、数据库查询SKILL、API对接SKILL、参数校验SKILL。
1.2 Schema校验模块:数据安全底座
- 作用:统一所有 SKILL 的输入输出数据格式;
- 技术实现:Python的Pydantic库、YAML/JSON Schema;
- 价值:技能间通信零误差,杜绝数据类型错误、字段缺失。
1.3 触发调度引擎:大模型决策入口
- 作用:接收大模型的意图判断,精准匹配并调用对应SKILL;
- 匹配维度:关键词、用户意图、上下文对话、置信度阈值;
- 优势:复杂场景下不混淆,比如用户说”帮我分析数据“,不会调用文本生成SKILL。
1.4 依赖管理中心:能力组合核心
- 作用:管理SKILL之间的调用关系、第三方服务依赖;
- 能力:支持单向依赖、链式依赖、并行依赖;
- 示例:报表生成SKILL → 依赖数据分析SKILL → 依赖数据采集SKILL。
1.5:版本与迭代管理器:维护保障
- 作用:每个SKILL独立版本控制,更新不影响其他能力;
- 价值:修复一个SKILL的bug,无需重启整个智能体,迭代成本降低90%。
2. 基础运行原理
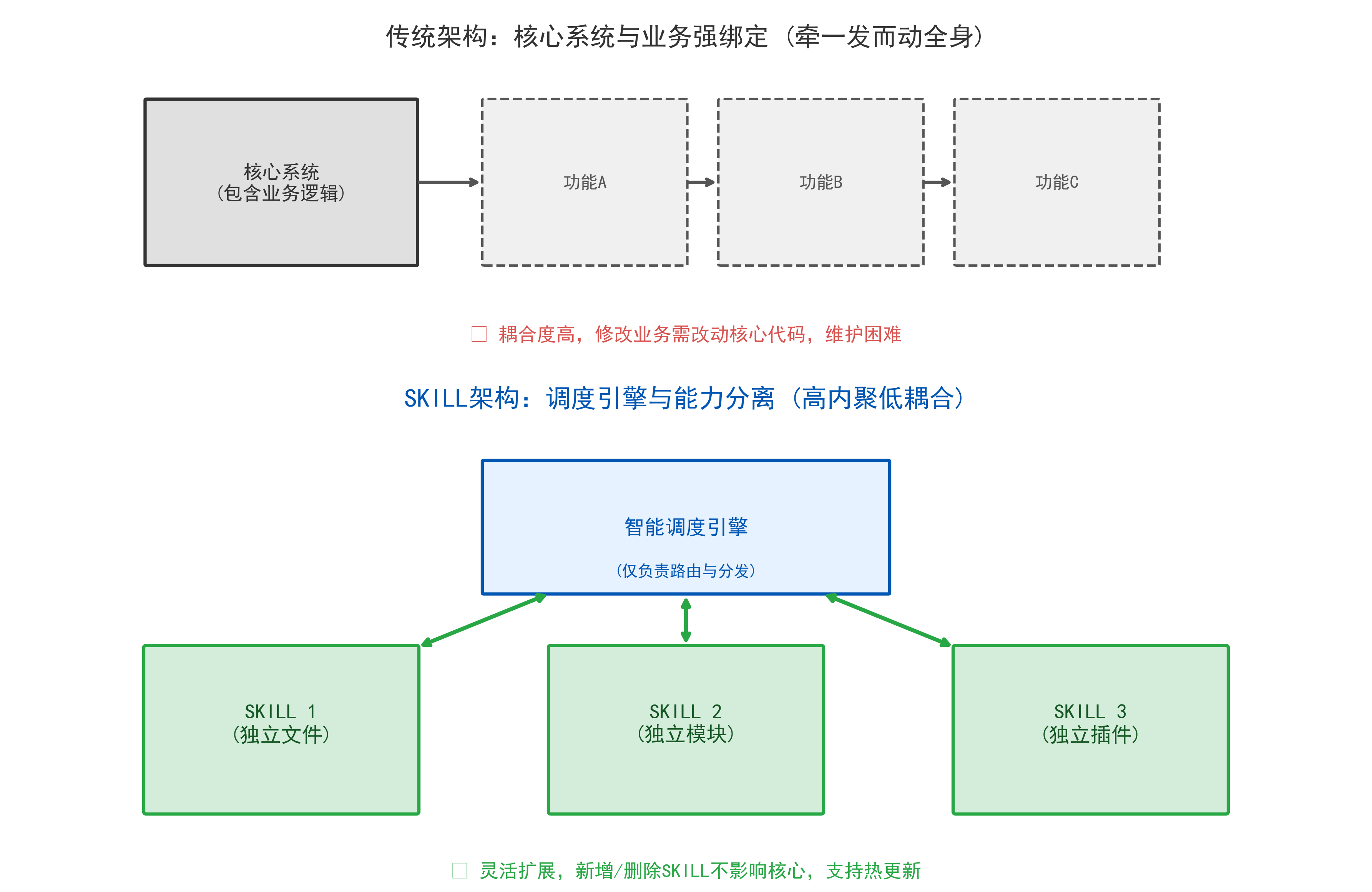
2.1 解耦原理:能力与核心代码分离
传统架构:核心系统 → 功能A → 功能B → 功能C(强绑定) SKILL架构:调度引擎 ↔ SKILL1 ↔ SKILL2 ↔ SKILL3(松耦合)
- 核心系统只负责调度,不承载任何业务能力;
- 每个 SKILL是独立文件、独立模块,新增、删除SKILL,不影响核心代码。
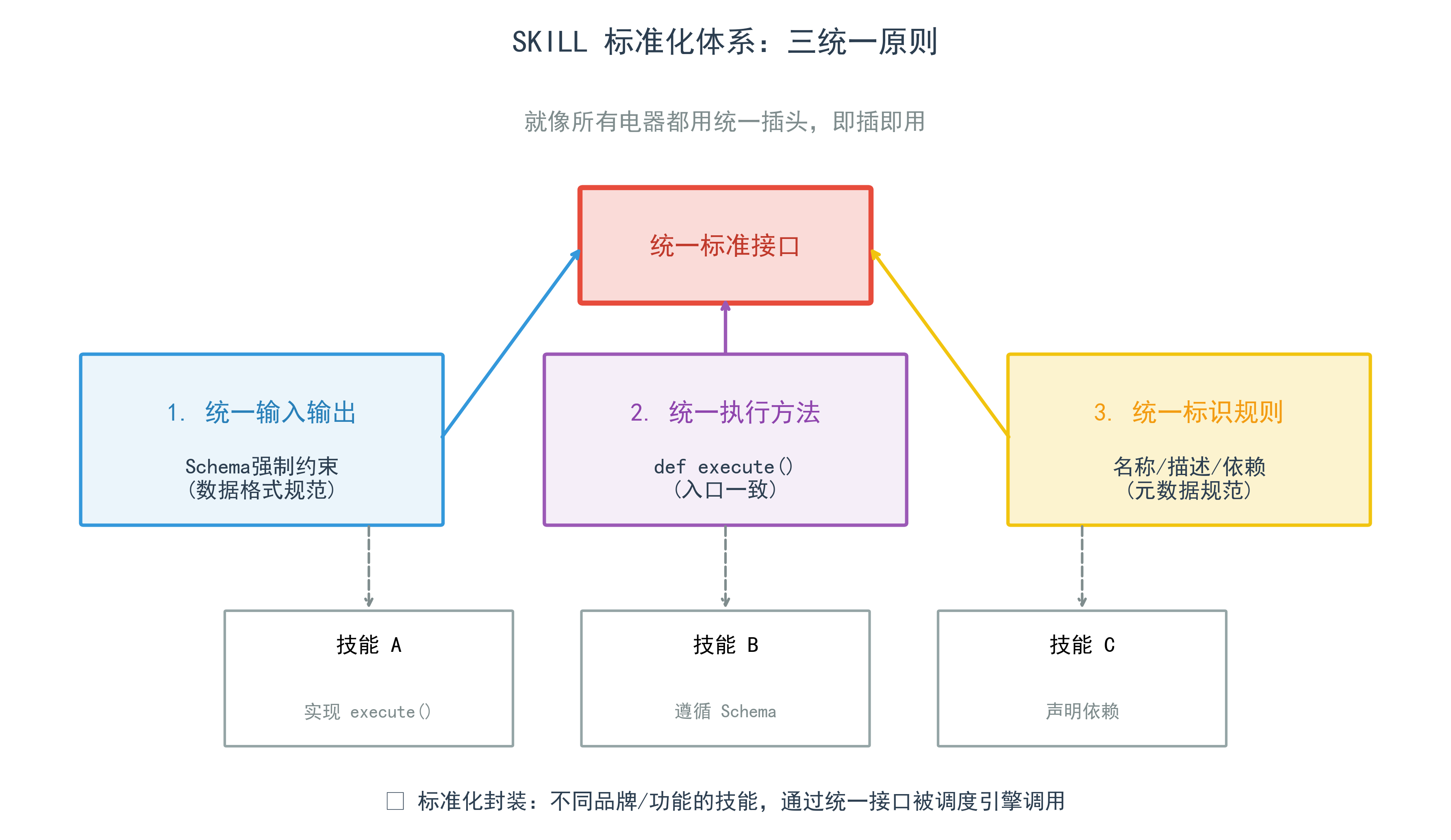
2.2 标准化原理:统一通信协议
所有 SKILL 遵循三统一:
- 1. 统一输入输出:用Schema强制约束;
- 2. 统一执行方法:所有SKILL都有execute()方法;
- 3. 统一标识规则:SKILL名称、描述、依赖声明格式一致。
这就像所有电器都用统一插头,不管什么品牌,都能直接使用。
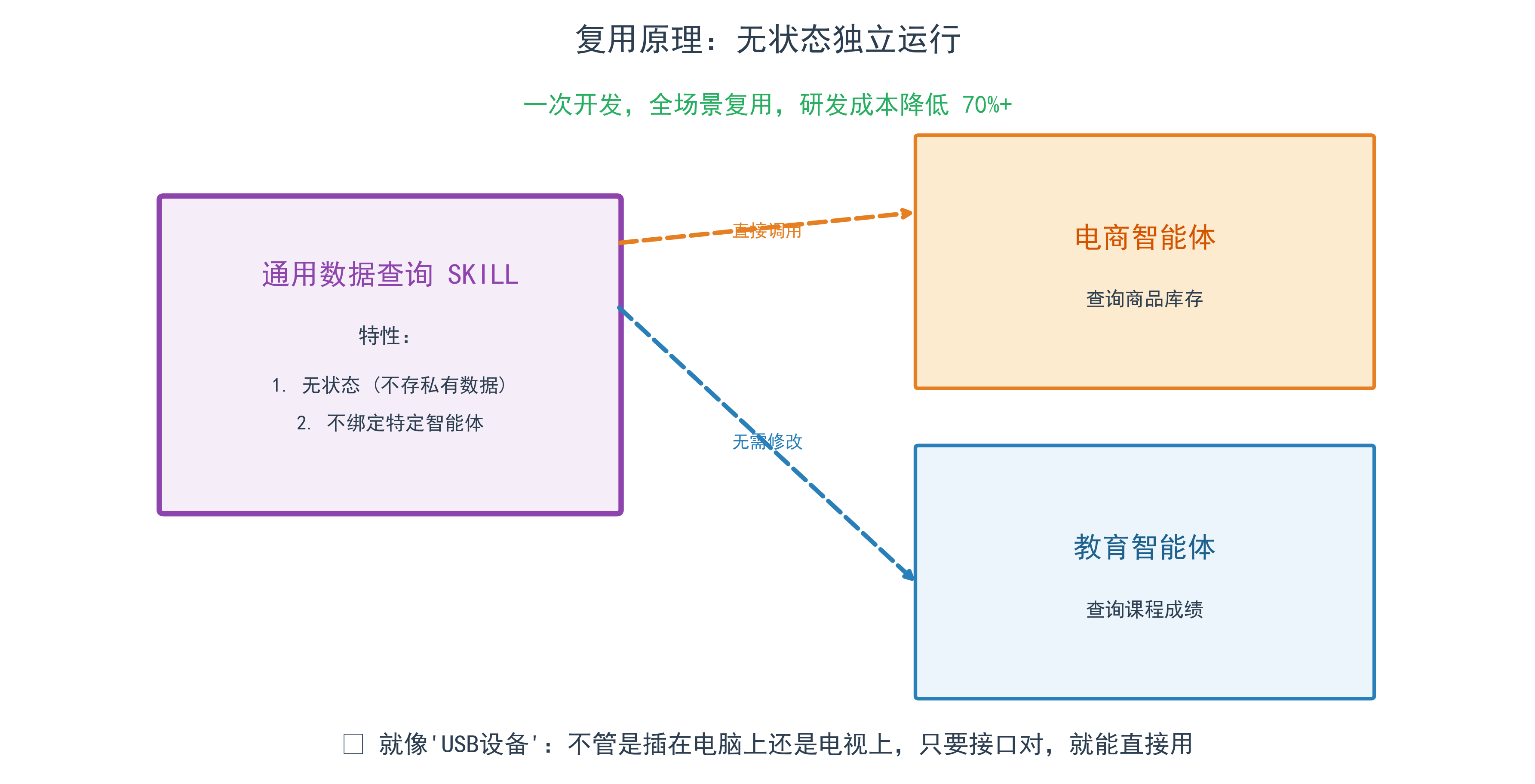
2.3 复用原理:无状态独立运行
SKILL单元不绑定任何智能体、不存储私有数据,只要符合标准,就能在任何项目中调用:
- 电商智能体的”数据查询SKILL“,可直接给教育智能体使用;
- 一次开发,全场景复用,研发成本降低70%以上。
2.4 扩展原理:独立迭代升级
每个 SKILL 有独立版本号:
- v1.0:基础查询功能;
- v1.1:增加缓存优化;
- v2.0:支持多数据源查询。
更新时,只替换单个SKILL文件,无需重启智能体,无风险、高效率。
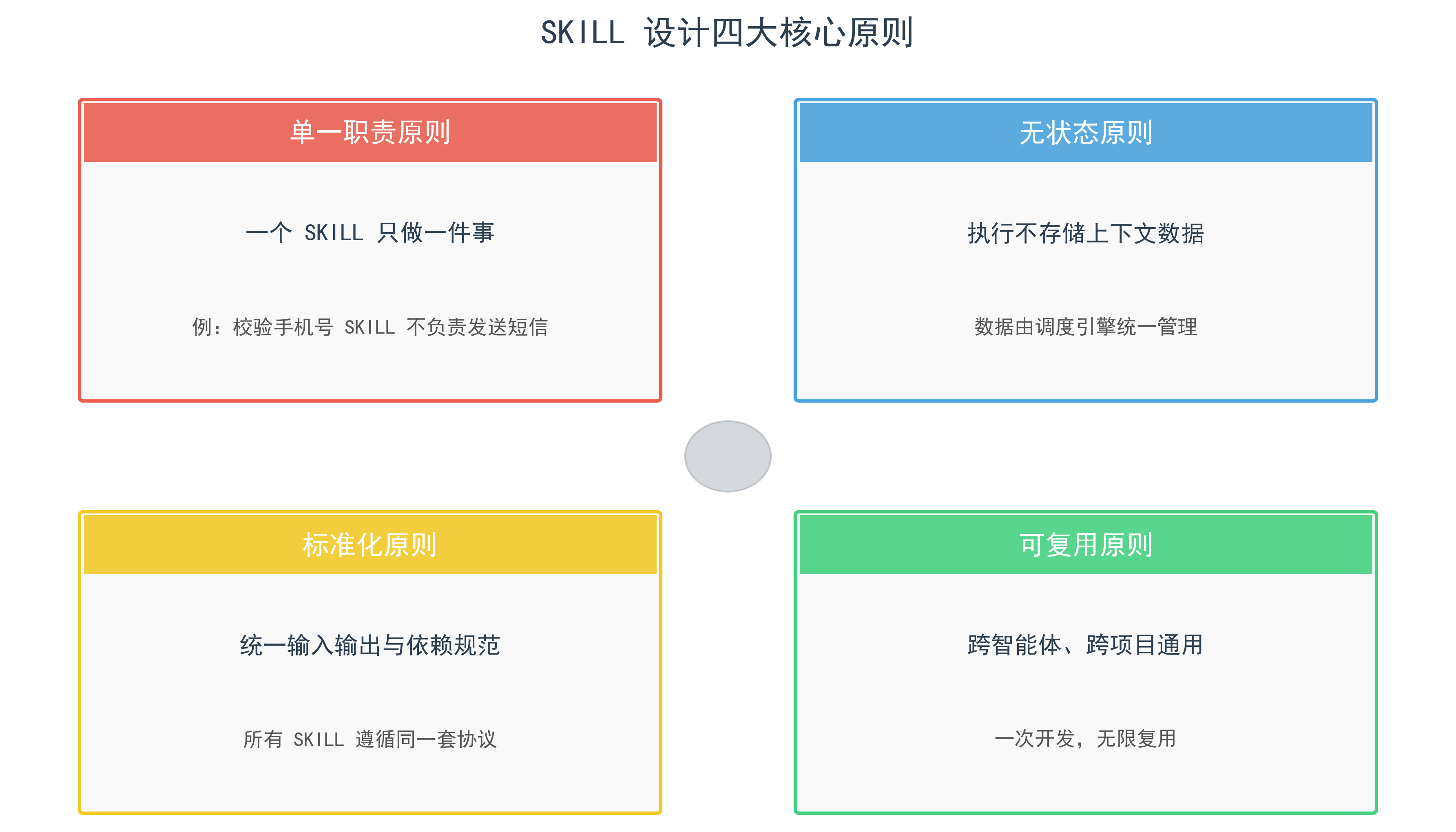
3. 四大设计原则
- 1. 单一职责原则:一个SKILL只做一件事,比如校验手机号SKILL不做短信发送;
- 2. 无状态原则:SKILL执行不存储上下文数据,数据由调度引擎统一管理;
- 3. 标准化原则:所有SKILL遵循统一的输入输出、触发、依赖规范;
- 4. 可复用原则:SKILL跨智能体、跨项目通用,一次开发,无限复用。
4. 实施细节考虑
- 粒度平衡:技能拆分不宜过细或过粗
- 性能考量:过多技能调用可能影响响应速度
- 版本管理:需要良好的技能版本控制系统
- 监控运维:建立技能运行状态的监控体系
5. 示例:Schema标准化封装
示例主要展示了基于Pydantic的SKILL标准化封装,核心设计如下:
- 输入层:参数校验与类型约束,DataQueryInput 定义了 user_id(最小3字符)、query_date(日期格式)、query_type(可选)
- 执行层:原子化业务逻辑,DataQuerySkill.execute() 完成数据查询并返回结构化结果
- 输出层:标准化响应格式,DataQueryOutput 统一返回 status/data/error_msg 三字段
from pydantic import BaseModel, Field
from typing import Optional
# ----------------------
# 步骤1:定义SKILL输入标准(Schema校验)
# ----------------------
class DataQueryInput(BaseModel):
# 必传参数:用户ID,字符串类型,最小长度3
user_id: str = Field(min_length=3, description="用户唯一标识")
# 必传参数:查询日期,格式YYYY-MM-DD
query_date: str = Field(pattern=r"^\d{4}-\d{2}-\d{2}$", description="查询日期,格式:YYYY-MM-DD")
# 可选参数:查询类型
query_type: Optional[str] = Field(default="default", description="查询类型")
# ----------------------
# 步骤2:定义SKILL输出标准(Schema校验)
# ----------------------
class DataQueryOutput(BaseModel):
# 执行状态:成功/失败
status: str = Field(description="执行状态")
# 返回数据
data: dict = Field(description="查询结果数据")
# 错误信息(执行失败时返回)
error_msg: Optional[str] = Field(default=None, description="错误信息")
# ----------------------
# 步骤3:基础SKILL封装(原子化单元)
# ----------------------
class DataQuerySkill:
# 技能标识(标准化命名)
skill_name = "data_query_skill"
# 技能描述(给大模型理解用)
skill_description = "根据用户ID和日期,查询用户业务数据"
def execute(self, input_data: dict) -> dict:
"""
SKILL核心执行方法
:param input_data: 输入参数(字典)
:return: 输出结果(字典)
"""
try:
# 1. 输入参数校验(标准化强制校验)
validated_input = DataQueryInput(**input_data)
# 2. 核心业务逻辑(原子功能)
result = {
"user_id": validated_input.user_id,
"query_date": validated_input.query_date,
"content": "用户当日业务数据:订单数5,消费金额200元"
}
# 3. 输出结果校验
validated_output = DataQueryOutput(
status="success",
data=result
)
# 返回标准化数据
return validated_output.model_dump()
except Exception as e:
# 异常标准化返回
return DataQueryOutput(
status="failed",
data={},
error_msg=str(e)
).model_dump()
# ----------------------
# 测试:调用原子SKILL
# ----------------------
if __name__ == "__main__":
# 初始化技能
skill = DataQuerySkill()
# 标准输入
test_input = {
"user_id": "U12345",
"query_date": "2026-04-08"
}
# 执行并输出
output = skill.execute(test_input)
print("SKILL执行结果(正确):\n", output)
test_input = {
"user_id": "U12345",
"query_date": "2026年04月08日"
}
# 执行并输出
output = skill.execute(test_input)
print("SKILL执行结果(错误):\n", output)代码说明:
- Schema 强制校验:用Pydantic定义输入输出规则,任何不符合格式的参数都会拦截并报错,保证数据安全;
- 原子化设计:每个SKILL独立封装,修改查询逻辑不影响其他代码,实现原子化;
- 标准化接口:输入输出完全标准化,可被任何其他SKILL或调度引擎调用。
- 自描述能力:skill_name + skill_description 供大模型理解功能意图
输出结果:
SKILL执行结果(正确): {'status': 'success', 'data': {'user_id': 'U12345', 'query_date': '2026-04-08', 'content': '用户当日业务数据:订单数5,消费金额200元'}, 'error_msg': None} SKILL执行结果(错误): {'status': 'failed', 'data': {}, 'error_msg': "1 validation error for DataQueryInput\nquery_date\n String should match pattern '^\\d{4}-\\d{2}-\\d{2}$' [type=string_pattern_mismatch, input_value='2026年04月08日', input_type=str]\n For further information visit pydantic.dev/2.12/v/string_pattern_mismatch"}
三、执行流程
1. 流程说明
结合以上示例,我们扩展成多个SKILL集成的模式,了解完整的执行流程:

步骤 1:用户输入(原始请求) 用户:帮我查询 U12345 用户 2026-04-08 的业务数据,然后生成一份分析报告
步骤 2:大模型意图理解(大脑决策) 大模型解析出:
- 用户需要两个能力:数据查询 + 报告生成;
- 执行顺序:先查询,后生成;
- 关键参数:user_id=U12345,query_date=2026-04-08。
步骤 3:触发调度引擎匹配SKILL 调度引擎根据大模型的意图,匹配两个标准化SKILL:
- 1. data_query_skill(数据查询)
- 2. report_generate_skill(报告生成)
步骤 4:SKILL依赖链执行
- 1. 执行data_query_skill,返回标准化查询结果;
- 2. 调度引擎把查询结果作为输入,传给report_generate_skill;
- 3. 执行报告生成SKILL,完成复杂任务。
步骤 5:结果返回用户 返回最终的分析报告,全程无数据错误、无逻辑混乱。
2. 应用实践
通过以上Schema标准化封装的示例,我们根据流程进行扩展成多SKILL,展示链式编排能力以及依赖链执行;
相比旧示例有以下核心增强:
- 1. 多SKILL链式编排能力:
- 旧示例仅展示单个SKILL调用,新代码实现了调度引擎(SkillScheduler):
- 数据查询SKILL → 报告生成SKILL 的完整链路,SKILL间数据自动传递,query_result 作为 report_input
- 2. SKILL组合复用模式:
- 调用方式从简单示例的直接调用升级为通过调度引擎编排
- 数据流转升级为SKILL间自动传递
- 3. 更完整的工程化结构
- ReportGenerateSkill:展示SKILL如何消费其他SKILL的输出
- SkillScheduler.run_pipeline():统一入口管理多SKILL执行顺序
- 链路状态追踪:每个步骤的成功/失败都有明确日志
from pydantic import BaseModel, Field
from typing import Optional
# ----------------------
# 步骤1:定义SKILL输入标准(Schema校验)
# ----------------------
class DataQueryInput(BaseModel):
# 必传参数:用户ID,字符串类型,最小长度3
user_id: str = Field(min_length=3, description="用户唯一标识")
# 必传参数:查询日期,格式YYYY-MM-DD
query_date: str = Field(pattern=r"^\d{4}-\d{2}-\d{2}$", description="查询日期,格式:YYYY-MM-DD")
# 可选参数:查询类型
query_type: Optional[str] = Field(default="default", description="查询类型")
# ----------------------
# 步骤2:定义SKILL输出标准(Schema校验)
# ----------------------
class DataQueryOutput(BaseModel):
# 执行状态:成功/失败
status: str = Field(description="执行状态")
# 返回数据
data: dict = Field(description="查询结果数据")
# 错误信息(执行失败时返回)
error_msg: Optional[str] = Field(default=None, description="错误信息")
# ----------------------
# 步骤3:基础SKILL封装(原子化单元)
# ----------------------
class DataQuerySkill:
# 技能标识(标准化命名)
skill_name = "data_query_skill"
# 技能描述(给大模型理解用)
skill_description = "根据用户ID和日期,查询用户业务数据"
def execute(self, input_data: dict) -> dict:
"""
SKILL核心执行方法
:param input_data: 输入参数(字典)
:return: 输出结果(字典)
"""
try:
# 1. 输入参数校验(标准化强制校验)
validated_input = DataQueryInput(**input_data)
# 2. 核心业务逻辑(原子功能)
result = {
"user_id": validated_input.user_id,
"query_date": validated_input.query_date,
"content": "用户当日业务数据:订单数5,消费金额200元"
}
# 3. 输出结果校验
validated_output = DataQueryOutput(
status="success",
data=result
)
# 返回标准化数据
return validated_output.model_dump()
except Exception as e:
# 异常标准化返回
return DataQueryOutput(
status="failed",
data={},
error_msg=str(e)
).model_dump()
# ----------------------
# 步骤4:报告生成SKILL(接收查询结果,生成报告)
# ----------------------
class ReportGenerateInput(BaseModel):
query_result: dict = Field(description="数据查询结果")
report_type: str = Field(default="summary", description="报告类型")
class ReportGenerateOutput(BaseModel):
status: str = Field(description="执行状态")
report: str = Field(description="生成的报告内容")
error_msg: Optional[str] = Field(default=None, description="错误信息")
class ReportGenerateSkill:
skill_name = "report_generate_skill"
skill_description = "根据查询数据生成业务报告"
def execute(self, input_data: dict) -> dict:
try:
validated_input = ReportGenerateInput(**input_data)
query_data = validated_input.query_result
# 生成报告
report_content = f"""
【业务数据报告】
用户ID: {query_data.get('user_id')}
查询日期: {query_data.get('query_date')}
数据摘要: {query_data.get('content')}
生成时间: 2026-04-08
报告类型: {validated_input.report_type}
""".strip()
return ReportGenerateOutput(
status="success",
report=report_content
).model_dump()
except Exception as e:
return ReportGenerateOutput(
status="failed",
report="",
error_msg=str(e)
).model_dump()
# ----------------------
# 步骤5:调度引擎(串联多个SKILL)
# ----------------------
class SkillScheduler:
"""SKILL调度引擎:负责SKILL链式调用"""
def run_pipeline(self, user_input: dict) -> dict:
"""
执行完整流程:数据查询 → 报告生成
"""
print("="*50)
print("调度引擎启动:数据查询 → 报告生成")
print("="*50)
# 步骤1:执行数据查询SKILL
print("\n步骤1:执行 data_query_skill")
query_skill = DataQuerySkill()
query_result = query_skill.execute(user_input)
if query_result["status"] != "success":
print(f"数据查询失败: {query_result['error_msg']}")
return {"status": "failed", "error": "数据查询失败"}
print("数据查询成功,返回标准化结果")
# 步骤2:调度引擎传递结果,执行报告生成SKILL
print("\n步骤2:调度引擎传递结果 → report_generate_skill")
report_input = {
"query_result": query_result["data"],
"report_type": "summary"
}
report_skill = ReportGenerateSkill()
report_result = report_skill.execute(report_input)
if report_result["status"] != "success":
print(f"报告生成失败: {report_result['error_msg']}")
return {"status": "failed", "error": "报告生成失败"}
print("报告生成成功")
print("="*50)
return {
"status": "success",
"query_data": query_result["data"],
"report": report_result["report"]
}
# ----------------------
# 测试:完整流程
# ----------------------
if __name__ == "__main__":
# 用户输入
user_input = {
"user_id": "U12345",
"query_date": "2026-04-08"
}
# 调度引擎执行完整流程
scheduler = SkillScheduler()
result = scheduler.run_pipeline(user_input)
print("\n最终输出:")
print(result)输出结果:
================================================== 调度引擎启动:数据查询 → 报告生成 ================================================== 步骤1:执行 data_query_skill 数据查询成功,返回标准化结果 步骤2:调度引擎传递结果 → report_generate_skill 报告生成成功 ================================================== 最终输出: {'status': 'success', 'query_data': {'user_id': 'U12345', 'query_date': '2026-04-08', 'content': '用户当日业务数据:订单数5,消费金额200元'}, 'report': '【业务数据报告】\n用户ID: U12345\n查询日期: 2026-04-08\n数据摘要: 用户当日业务数据:订单数5,消费金额200元\n生成时间: 2026-04-08\n报告类型: summary'}
四、技术细节
1. 多维度触发规则实现
传统智能体只支持关键词匹配,比如只有输入”查询数据“才调用对应功能。SKILL架构支持4维精准匹配:
class SkillTrigger:
"""SKILL触发规则引擎(多维度匹配)"""
def match_skill(self, user_intent: dict, context: dict) -> str:
"""
匹配最佳SKILL
:param user_intent: 大模型识别的用户意图
:param context: 对话上下文
:return: 匹配的SKILL名称
"""
# 1. 关键词匹配(基础)
keyword_match = "数据查询" in user_intent["text"]
# 2. 意图匹配(核心,大模型输出)
intent_match = user_intent["intent"] == "data_query"
# 3. 上下文匹配(历史对话)
context_match = context.get("last_skill") == "data_prepare"
# 4. 置信度匹配(大模型识别可信度≥0.8)
confidence_match = user_intent["confidence"] >= 0.8
# 多维度综合判断
if intent_match and confidence_match:
return "data_query_skill"
elif keyword_match and context_match:
return "data_query_skill"
else:
return "default_skill"应用价值:复杂场景下,如用户模糊提问、上下文关联任务场景可精准调用SKILL,不混淆、不错误。
2. 技能依赖链调度实现
class SkillDependencyScheduler:
"""SKILL依赖调度引擎"""
def __init__(self):
# 定义依赖链:报告生成 → 依赖 → 数据查询
self.dependency_chain = {
"report_generate_skill": ["data_query_skill"]
}
def run_chain(self, skill_name: str, input_data: dict) -> dict:
"""执行依赖链"""
# 1. 获取当前SKILL的依赖
dependencies = self.dependency_chain.get(skill_name, [])
# 2. 先执行所有依赖SKILL
dependency_result = {}
for dep_skill in dependencies:
dep_instance = DataQuerySkill()
dependency_result = dep_instance.execute(input_data)
# 依赖执行失败,直接返回
if dependency_result["status"] == "failed":
return dependency_result
# 3. 依赖执行成功,执行目标SKILL
target_skill = ReportGenerateSkill()
final_result = target_skill.execute(dependency_result["data"])
return final_result执行逻辑:自动按依赖顺序执行,前一个SKILL失败则终止,保证任务逻辑正确性。
五、总结
SKILL架构本质上就是把传统耦合严重、改一点动全身的智能体,彻底改成了插件化、可拼装、易维护的工程化系统。它通过原子化拆分把每个功能拆成独立 SKILL模块,再用标准化封装统一输入输出、触发规则和依赖管理,直接解决了传统智能体扩展难、复用低、维护麻烦的痛点,真正做到了像搭乐高一样搭建智能体。
好的AI架构从来不是堆功能,而是解耦、规范、可扩展。大模型负责理解和决策,SKILL负责执行和落地,分工清晰才是落地的关键。初次接触建议大家先吃透基类和注册机制,再动手写简单插件,逐步尝试依赖链和热更新。不要一上来就追求复杂流程,先把单个SKILL做标准、做稳定,后续组合起来自然流畅。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号