Stripe用它一天迁完5000万行代码——Claude Fable 5 / Mythos 5最佳实践

Stripe用它一天迁完5000万行代码——Claude Fable 5 / Mythos 5最佳实践

老周聊架构
发布于 2026-06-12 18:33:44
发布于 2026-06-12 18:33:44
Stripe有一个5000万行的Ruby代码库,需要做架构迁移。团队评估:大约需要两个月。他们把任务丢给了Claude Fable 5。一天搞定。
2026年6月9日,Anthropic同时发布了两个模型:Claude Fable 5和Claude Mythos 5。
这不是常规的版本迭代。这是Anthropic第一次把Mythos级能力开放给普通用户。
先说几个关键数据:
- 几乎所有公开基准测试SOTA(State of the Art)
- 比Opus 4.8快25-30%,Token效率更高
- 科学家在80%的情况下偏好Mythos而非Opus级模型
- 药物设计加速10倍,14个蛋白质靶点中9个找到了强候选分子
- 基因组学:自主研究运行了整整一周,训练出的模型超越了Science期刊论文,且体积小100倍
但最有意思的不是它有多强,而是它的"护栏"设计—— Fable 5和Mythos 5是同一个模型,区别在于安全限制的开关。这是Anthropic第一次把"能力"和"安全"彻底解耦。
今天这篇文章,讲清楚Fable 5 / Mythos 5的技术能力、安全架构、以及实战中怎么用好它。
一、先搞清楚:Fable 5和Mythos 5到底是什么关系?
1.1 同一个模型,两套规则
这是最容易搞混的地方:Fable 5和Mythos 5的底层模型完全一样。
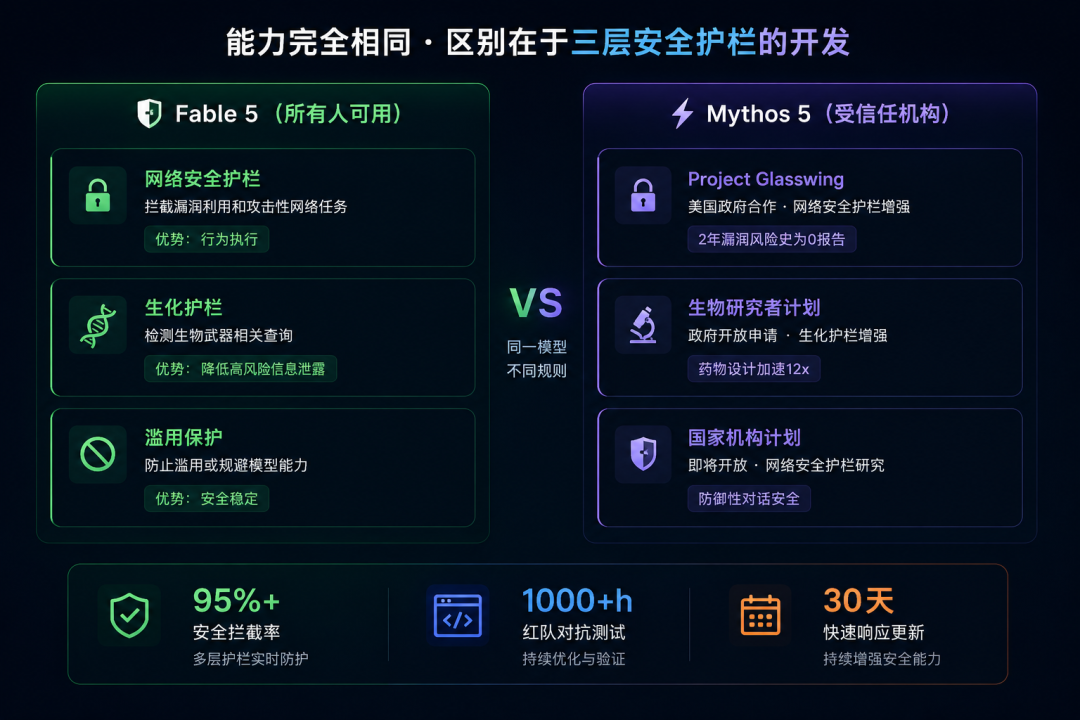
用人话说:Fable 5是带安全带的超跑,Mythos 5是取掉限速器的同款超跑——但只有拿到赛道许可证的人才能开。
1.2 为什么这个设计很重要?
以前的做法是:强模型只给政府/企业用,弱模型给公众用。
Anthropic的做法不同:给所有人同样强的模型,但在敏感领域加软件护栏。 95%以上的使用场景不受影响,只有涉及网络安全攻击、生物武器、模型蒸馏时才会触发。
这意味着:你用Fable 5写代码、做分析、搞研究,体验和Mythos 5完全一样。
二、能力全景:几乎所有基准测试SOTA
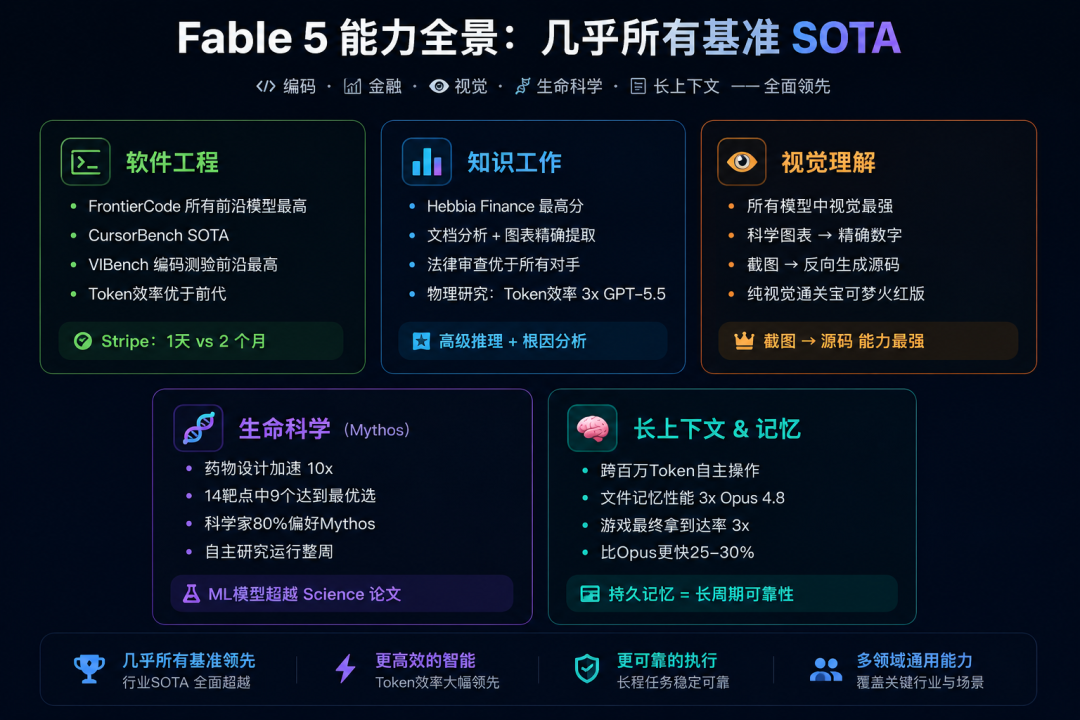
2.1 编码能力
Fable 5在FrontierCode(Devin团队出的评测)上拿下所有前沿模型最高分,CursorBench SOTA,ViBench端到端编码基准最高。最炸裂的实战案例:Stripe用它1天完成了原本预计2个月的5000万行Ruby代码库迁移。
Fable 5在编码上的提升不仅是"更准",更关键的是更省Token。同样的任务,它比之前的Claude版本用更少的Token完成,这直接影响成本和速度。
2.2 知识工作
Hebbia Finance Benchmark所有前沿模型最高分。文档分析能精准提取图表数字,概念推理支持高级推理+根因分析。
法律领域的盲审测试中,Fable 5表现优于所有对手模型。在物理学研究中,Token效率是GPT-5.5的3倍。
2.3 视觉能力
Fable 5的视觉能力是当前所有模型中最强的:
- 从科学图表中精确提取数字
- 从截图反向重建Web应用源代码
- 仅靠视觉就通关了宝可梦火红版(只需要极少的外部辅助)
最后一条听起来像是在搞笑,但它证明了一个严肃的能力:长时间、多步骤、视觉驱动的自主决策。 一个游戏通关需要数百个连续决策,每个决策都基于屏幕画面。这比任何基准测试都更能体现Agent的实际能力。
2.4 长上下文 & 记忆
Fable 5支持跨百万Token的自主操作,文件记忆性能是Opus 4.8的3倍,游戏最终章到达率提升3倍。
Fable 5的文件记忆系统(file-based persistent memory)是一个重要特性:它不是简单的上下文窗口,而是能在极长的任务中持续维护和检索信息。
2.5 生命科学(Mythos 5限定)
这是Mythos 5最震撼的能力领域:
- 药物设计:设计过程加速约10倍,匹配或超越专业人类操作员
- 蛋白质靶点:14个测试靶点中9个找到强候选分子
- 分子生物学:产出新颖假说,科学家80%偏好Mythos vs Opus级
- 假说验证:一个假说被独立研究证实
- 基因组学:自主研究运行一整周;汇编138个物种的数百万单细胞数据;训练的ML模型超越Science论文且小100倍
基因组学的结果尤其惊人: 模型自主进行了一周的研究,自己收集数据、自己设计实验、自己训练机器学习模型——最终结果超越了发表在Science上的人类研究,而且模型大小只有原论文的1%。
三、安全架构:护栏是怎么工作的?
3.1 三层护栏
Fable 5相比Mythos 5,开启了三层安全护栏:网络安全护栏(触发时拒绝执行)、生化护栏(触发时降级到Opus 4.8回答)、蒸馏保护(触发时拒绝配合)。
第二条很有意思: 不是直接拒绝,而是悄悄切换到Opus 4.8来回答。这意味着用户仍然能得到回答,但回答的能力被限制在了上一代模型的水平。
3.2 护栏的触发率
Anthropic公布了一个关键数据:
平均触发率:不到5%。95%以上的会话不受任何影响。
1000+小时的外部红队测试没有找到通用越狱方法。
3.3 数据留存政策
Mythos级模型有一个特殊要求:
- 所有流量保留30天(仅用于安全审计,不用于训练)
- 人工访问需要日志记录
- 30天后在大多数情况下删除
这是能力与安全的交换条件。 你获得了Mythos级的能力,代价是30天的流量留存。对大多数场景来说这不是问题,但如果你处理的是极度敏感的数据(比如律师-客户特权通信),需要注意这一点。
四、定价与可用性
Fable 5是目前最贵的通用模型——输入10美元/百万Token,输出50美元/百万Token。 比Mythos Preview的价格低了一半以上。
但考虑到它的Token效率更高(同样任务用更少Token),实际成本差距可能没有标价看起来那么大。和DeepSeek R1比,价格是它的23倍——但能力维度完全不同。
老周的建议:如果你想免费体验Fable 5,抓紧6月22日之前的窗口期。 23号之后就要额外付费了。
Mythos 5的获取渠道:Project Glasswing合作伙伴可解除网络安全护栏;生物研究者计划即将开放申请,可解除生化护栏;网安机构计划即将开放,可解除网络安全护栏。
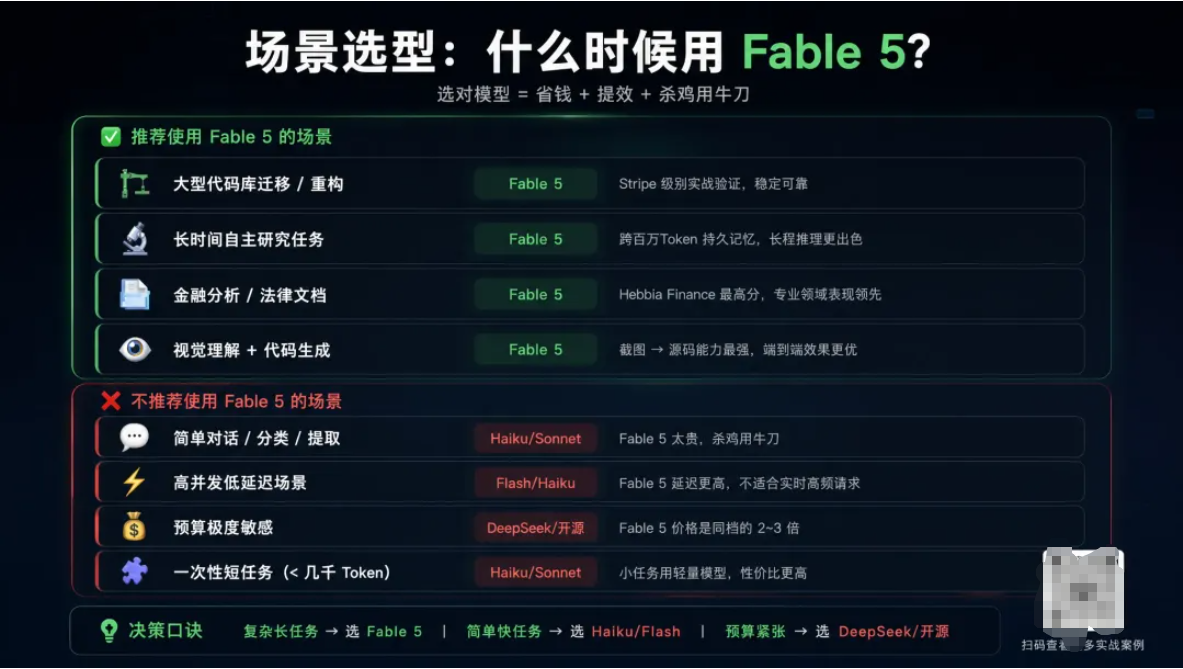
五、最佳实践:怎么用好Fable 5?
5.1 场景选型
5.2 编码最佳实践
实践一:大规模代码迁移
Stripe的案例给出了模板:
1 1. 让Fable 5先读懂整个代码库的架构
2 2. 制定迁移计划(它的规划能力远超Opus)
3 3. 分批执行迁移,每批后自动运行测试
4 4. 失败时自主诊断和修复关键点:不要一次丢一个文件,丢整个项目让它理解全局。 Fable 5的长上下文和记忆能力是它最大的差异化优势。
实践二:利用Token效率优势
Fable 5比之前的Claude版本更省Token。实际做法:
- 不需要过度详细的System Prompt——它理解力更强,简洁指令即可
- 减少Few-shot示例的数量——它的zero-shot能力更强
- 对于复杂任务,让它自己规划步骤,而不是你在prompt里写死步骤
5.3 研究与分析最佳实践
实践三:利用文件记忆做长周期任务
Fable 5的file-based memory让它可以在极长任务中维护状态。最佳实践:
1 1. 在任务开始时创建一个"研究日志"文件
2 2. 让模型在每个阶段将关键发现写入日志
3 3. 在后续阶段让模型先回顾日志再行动
4 4. 这比纯靠上下文窗口的效果好3倍实践四:视觉分析流水线
Fable 5的视觉能力可以构建强大的自动化流水线:
1 PDF报告 → Fable 5提取图表数据 → 结构化JSON
2 竞品截图 → Fable 5分析UI模式 → 生成类似代码
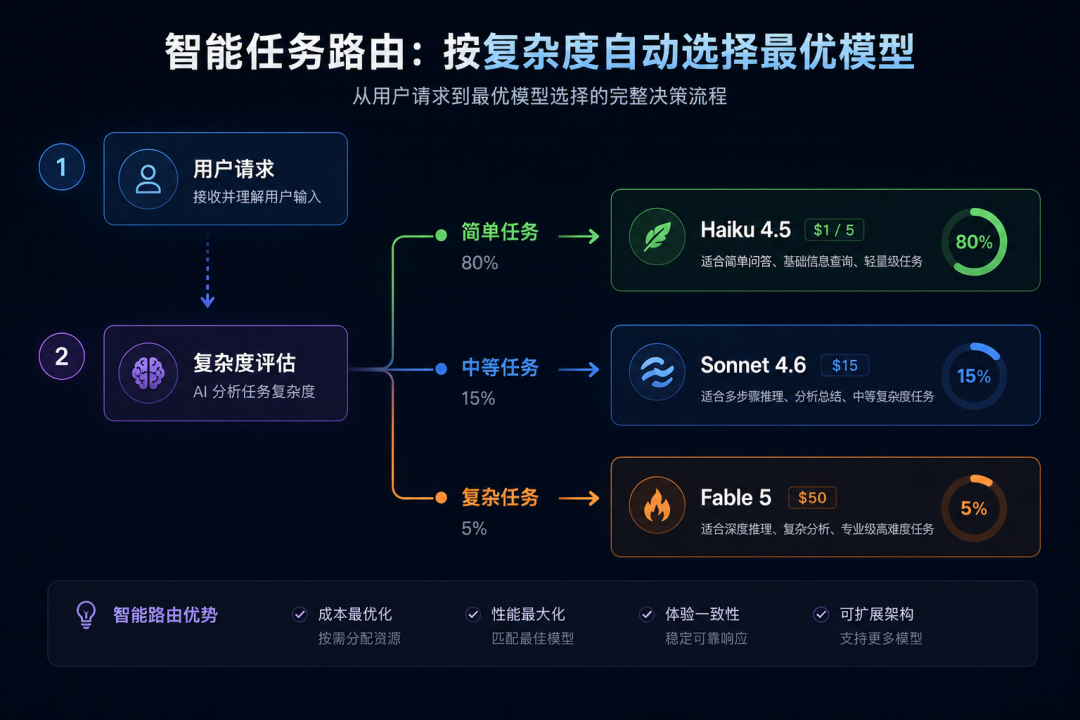
3 手绘原型 → Fable 5理解意图 → 完整前端代码5.4 成本优化策略
策略一:路由分层
策略二:Prompt精简
Fable 5理解力更强,你可以:
- 把System Prompt从2000字压缩到500字——节省75%输入Token
- 用简短指令替代详细步骤描述
- 减少上下文注入量,让它自己搜索需要的信息
策略三:结果缓存
1. 生 Prompt Caching(省输入)
:把固定不变的部分——System Prompt、长文档、few-shot 示例——放在 prompt 前缀并标记缓存。后续命中同一前缀的调用,这部分输入按大幅折扣计费。这是和策略二配合最紧的一招:精简之外,剩下的固定内容用缓存兜住。
2.应用层结果缓存(省整次调用)
:对完全相同的查询(做好归一化:去空格、统一大小写、去无关参数),直接返回上次存的答案,连 API 都不调。最适合 FAQ、固定报表、模板类请求。
3. 语义缓存(谨慎用于相似查询)
:用 embedding 计算查询相似度,超过高阈值(比如 0.95+)才复用。务必设白名单——只在"措辞变了但答案不变"的场景开启,时效类、含具体数值/日期的查询一律绕过。
六、Fable 5 vs 竞品:值不值这个价?
Fable 5值不值50美元/百万输出Token?
- 如果你的场景是大型代码库操作、长周期研究、复杂文档分析——值。Token效率的提升和任务完成率的提升可以覆盖价格差距
- 如果你的场景是日常编码、简单问答、内容生成——不值。Sonnet 4.6甚至Haiku 4.5就够了
- 如果你预算敏感——先用6月22日前的免费窗口验证效果,再决定是否购买积分
一个实用的判断标准:如果这个任务用Opus 4.8需要反复尝试3次以上才能成功,用Fable 5可能一次就行——算上重试的Token成本,Fable 5反而更便宜。
七、安全与合规注意事项
7.1 护栏触发场景
虽然95%的会话不受影响,但以下场景需要注意:
7.2 30天数据留存的影响
对大多数团队来说,30天留存不是问题。但如果你处理以下数据,请注意:
- 律师-客户特权通信
- 医疗隐私数据(HIPAA)
- 国家安全相关信息
- 涉及商业机密的对话
建议:敏感数据在发送给API前做脱敏处理。 这不是Fable 5特有的建议——任何第三方API调用都应该这么做。
写在最后
Claude Fable 5的发布,标志着AI行业进入了一个新阶段:最强的模型不再是实验室的专属。
以前,"最强模型"意味着只有少数研究机构或政府合作伙伴能用。Anthropic用Fable 5打破了这个惯例——把Mythos级的能力直接给所有用户,同时通过精确的护栏设计控制风险。
95%的场景不受影响,5%的敏感场景被精确拦截。 这比"要么全开要么全关"的二元策略高明太多了。
从实用角度看,Fable 5最大的价值不是"跑分最高"——而是在长时间、跨百万Token的复杂任务中表现稳定。Stripe的5000万行代码迁移、一周的自主基因组学研究——这些不是5分钟能完成的基准测试,而是需要模型持续数小时甚至数天保持高质量输出的真实场景。
这才是Fable 5真正拉开差距的地方。
一句话总结:Fable 5不是"更好的聊天机器人",而是"更可靠的AI工程师"。它的价值不在单次对话,而在长周期的自主执行。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号