ResNet:用残差连接解锁深层网络的经典架构

ResNet:用残差连接解锁深层网络的经典架构

张仲岚同学
发布于 2026-06-12 14:18:42
发布于 2026-06-12 14:18:42

全文约9000字,预计阅读时间:25分钟
ResNet(Residual Network,残差网络)诞生于2015年,由何恺明等人提出,同年夺得ImageNet图像识别竞赛冠军,以152层的网络深度将Top-5错误率降至3.57%,超过人类水平。它解决的核心问题只有一个:为什么神经网络叠得越深,效果反而越差?这个问题在ResNet出现之前困扰了整个深度学习领域多年。ResNet给出的答案极其简单——一个加法、一条跳跃的线——但它对整个领域的影响延续至今,几乎所有现代视觉模型都以它为基础。
这篇笔记从零开始,把ResNet的核心思想和数学原理一步步讲清楚。每个概念都先解释"它在解决什么问题",再讲"它怎么解决的",涵盖从神经网络基础到反向传播数学的完整逻辑链。
前置概念:神经网络与CNN
为什么叫"神经网络"
神经网络(Neural Network)的命名来自对大脑工作方式的模仿。生物神经元的工作机制是:接收来自多个上游神经元的信号,对每个信号乘以一个"权重"(代表这条连接的重要程度),将所有信号加权求和,当总和超过某个阈值时,这个神经元"激发",向下游神经元发送输出信号。人工神经网络完全照抄了这个结构:
输入1 × 权重1 ┐
输入2 × 权重2 ├→ 加总 → 激活函数 → 输出
输入3 × 权重3 ┘
每个这样的计算单元叫做一个"神经元"。把大量神经元连成一张网,就是神经网络。网络按层组织:同一层的神经元接收相同的输入,输出传给下一层。深度(depth)指的是层数,层数越多,网络越深——这也是"深度学习"中"深度"一词的由来。理论上,层数越多,每一层都能在前一层的基础上提炼出更抽象的特征,网络的表达能力也随之增强。
卷积神经网络(CNN)是什么
CNN(Convolutional Neural Network,卷积神经网络)是神经网络的一个分支,专门为处理图像设计。神经网络家族很大,还包括处理文本和序列数据的RNN、当前大语言模型使用的Transformer等,而CNN是其中最擅长从图像中提取空间特征的那个。
CNN的核心操作是卷积:用一个小矩阵(卷积核,Kernel)在图像上滑动,每次覆盖一小块区域,把该区域的像素值与卷积核对应位置的数字逐个相乘后求和,得到一个新数值。这个过程覆盖整张图后,得到一张特征图(Feature Map)——记录这个卷积核在每个位置的响应强度,数值越大说明该位置越符合这个卷积核所寻找的模式。卷积核的数值不是人工设定的,而是通过训练自动学出来的:某个核可能学到"检测横向边缘",另一个学到"检测某种纹理",但这个分工是训练过程自发形成的,人不需要干预。
池化(Pooling)跟在卷积之后,用于压缩特征图的空间尺寸。最常用的最大池化(Max Pooling)取2×2区域内的最大值,空间尺寸减半,通道数不变。取最大值的逻辑是:特征图中数值较大的位置说明"这里有较强的特征响应",平均值会被周边弱响应稀释,取最大值能更清晰地保留"这个区域是否有、强度多大"的信息。
CNN通过反复执行"卷积→激活函数→池化",逐层把图像从原始像素压缩成越来越抽象的特征表示。浅层捕捉边缘、颜色等低级信息,深层捕捉形状、物体部件等高级语义,最终输出的特征向量被用于分类等任务。ResNet就是在CNN这个基础上演化出来的。
核心问题:网络越深越差
退化问题(Degradation Problem)
直觉上,CNN层数越多,特征提取的层次越丰富,模型越强大。这个直觉并非错的——在层数有限的范围内,加深网络确实能提升效果。但2015年的实验发现了一个反常现象:在CIFAR-10数据集上,56层的网络在训练集上的误差,竟然比20层的网络还要高。注意,这里说的是训练集误差,不是测试集误差。过拟合(overfitting)的表现是训练集效果好但测试集效果差;而这里是训练集效果本身就更差,说明更深的网络根本没有被训练好。何恺明等人把这个现象命名为退化问题(degradation problem)。
退化问题的反直觉之处在于:如果一个20层网络已经训练到较好的效果,那么一个56层网络,理论上只需要前20层复制20层网络的参数,后36层学出"什么都不做(恒等映射)",整体效果应该至少和20层网络持平。但实验结果告诉我们,这36层"多余的层"非但没有学出恒等映射,反而让整个网络的表现变差了。这说明:非线性函数叠加起来,学出"原样输出"这个行为,比想象中困难得多。
恒等映射(identity mapping)是一个简单到极致的函数:
,输出等于输入,什么都不改变,就像一块完全透明的玻璃。你可能觉得这应该很容易学——卷积层让所有权重为零,输出不就是零,加个偏置让输出等于输入不就行了吗?实际上,神经网络每一层都是多个非线性运算(卷积、批归一化、ReLU激活等)的叠加,这些运算组合在一起的行为非常复杂,通过梯度下降自动寻找到"恰好让输出等于输入"的参数组合,需要大量训练和近乎完美的优化条件,在实践中很难做到。这就是退化问题的本质。
梯度消失与梯度爆炸
退化问题还有一个更直接的成因,来自训练机制本身:梯度问题。梯度问题有两种方向相反的表现,要理解它们,需要先理解训练过程的两个阶段。
前向传播(Forward Propagation):数据从输入层开始,依次经过每一层的计算,最终产生预测结果。每一层的参数(卷积核里的数字)决定了这一层的计算方式。
反向传播(Back Propagation):用损失函数(Loss Function)衡量预测结果与真实标签的差距,得到一个数值
(损失值),
越大说明预测越差。然后,把这个"预测有多差"的信号从最后一层往前传,告诉每一层的参数应该往哪个方向调整——这个方向信息就是梯度(gradient)。
梯度的含义是:某个参数增加一点点时,损失
会怎么变化。梯度为正,说明这个参数增大会让损失增大,应该把它调小;梯度为负,说明这个参数增大会让损失减小,应该把它调大。梯度的绝对值大,说明这个参数对损失的影响大,应该大幅调整;接近于0,说明影响微乎其微,几乎不需要调整。
梯度是通过链式法则(chain rule)逐层计算的。损失
在最后一层计算,要把梯度传回第1层,需要经过每一层的导数连乘。以
层网络为例:
这里每个
代表第
层的局部导数。根据
的大小,会出现两种截然相反的病态情况:
梯度消失(Vanishing Gradient):若每层的局部导数
,多个小于1的数连乘,结果指数级趋近于0。最终,第1层(以及前面许多层)收到的梯度接近于0,这些层的参数几乎不会更新,形同没有被训练。层数越深,信号衰减越严重。
梯度爆炸(Exploding Gradient):若每层的局部导数
,多个大于1的数连乘,结果指数级趋向于无穷大。参数更新步长极大,训练过程剧烈震荡甚至发散,网络根本无法收敛。
两种问题共同的根源都是深层网络中梯度的"连乘效应"——层数越深,这个效应越失控。这就是深层网络训练不稳定的根本机制。
ResNet 的解法:残差块
核心结构与设计动机
ResNet 的解法出乎意料地简单。在每几层卷积旁边,加一条直接连通输入和输出的线(skip connection,跳跃连接),将输入
绕过卷积层,直接加到卷积层的输出上:
x ──────────────────────────→ (+) → 输出
↘ ↑
[卷积→BN→ReLU→卷积→BN] → F(x)
这个完整的结构叫做残差块(Residual Block)。其中:
是这个块的输入,来自上一层传来的特征;
是
经过块内两层卷积处理后的结果;
是将卷积输出与原始输入相加,作为这个块的最终输出。这里的加法是逐元素相加(element-wise addition):两个相同形状的特征图,每个对应位置的数字直接相加,形状不变。
设计的直觉是:与其让卷积层从头学出完整的输出,不如让它只学"需要在输入基础上补充什么"。原始输入
已经包含了一定的信息,卷积层的任务是找到"还差什么",而不是"全部从零构建"。这个任务的难度远低于前者,尤其是在"理想答案接近输入本身"的情况下。
残差的含义
理解"残差"(Residual)这个词需要引入一组符号,把设计逻辑说清楚。
设这个块的输入是
,这个块在理想情况下应该输出什么,记为
。
是一个人为设定的概念——它代表"这个块的目标输出",训练开始前我们并不知道它长什么样,它是随着训练逐步逼近的目标。在普通CNN中,卷积层的任务就是直接学出
:给我
,产生
。这个任务需要卷积层从当前输入出发,凭借自身的运算能力,学出任意复杂的输出形式。
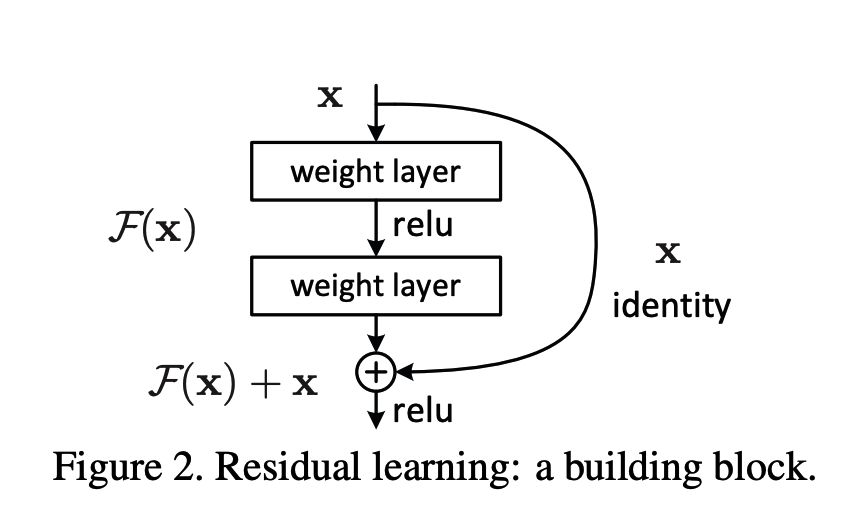
ResNet论文《Deep Residual Learning for Image Recognition》中的原理图↑
doi:https://doi.org/10.48550/arXiv.1512.03385
ResNet的改动是:既然
已经通过skip connection直接保留了,卷积层不需要再操心
的部分,只需要学"
与
之间的差距",即:
这个差值
就是残差,含义是"在现有输入的基础上,还需要补充什么才能得到理想的输出"。将等式变形得到:
,这正是残差块的输出公式。
这里容易产生一个误解:既然任务是学
,是不是训练目标就是让
越来越小、趋近于0?这个理解是错误的。
趋向于0只是一种特殊情况,发生在"这一层确实不需要对输入做任何改变"的时候——即
的情况。在大多数情况下,这一层是需要学习到有效特征变换的,
应该是一个有意义的非零值。将任务从"学
"变成"学
"的价值,不是让学习目标变小,而是让学习目标的起点变了:原来是从零开始学一切,现在是在
基础上学补充的部分,后者更容易。
为什么解决了退化问题
退化问题的根源是:深层网络的卷积层无法学出恒等映射
。引入残差块之后,恒等映射对应的学习目标变成了
——让卷积层的输出接近于全零向量。与学出恒等映射相比,让一堆卷积权重产生接近零的输出,在优化上容易得多:梯度下降可以轻松地把权重拉向零附近。
更关键的保证是:就算卷积层在这个块里什么都没学好,
,这个块的输出还是
,等于原样输出,网络的整体性能不会因为这一块而变差。这个性质从根本上保证了"深层网络不会比浅层更差":最坏情况是平手,不会退步。而在实践中,只要卷积层学到了哪怕一点点有用的残差,整体效果就会更好。这就是ResNet能突破深度限制的核心机制。
Batch Normalization:对抗梯度问题的另一手
残差块解决了退化问题,但梯度消失和梯度爆炸的根源——每层局部导数大小不可控——还需要另一个机制来约束:Batch Normalization(批归一化,BN)。
BN的操作发生在卷积之后、激活函数之前:把这一层输出的数值,在当前批次(batch)内做归一化,使均值为0、方差为1,再通过可学习的缩放参数
和平移参数
恢复表达能力:
这样做的效果是:把每层的激活值拉回一个稳定的数值范围,避免某些层输出值过大(导致梯度爆炸)或过小(导致梯度消失)。无论网络多深,每一层的输入分布都被约束在合理区间,连乘效应被大幅削弱。
BN还带来了一个额外好处:它本身就有一定的正则化效果,使模型在训练时对噪声更鲁棒。这让ResNet可以完全丢弃 Dropout——在ResNet之前,Dropout 是对抗过拟合的标配手段,但BN的引入使其变得多余,去掉它还能让网络学得更充分。
残差块(skip connection)+ BN 是 ResNet 真正的双引擎:前者解决退化,后者稳定梯度,两者缺一不可。
多个残差块的串联
首尾相连的流水线
ResNet 的完整网络由多个残差块首尾相连构成,上一个块的输出直接作为下一个块的输入,形成一条特征提取的流水线:
这里的下标表示经过了几个残差块之后的特征。
是第一个块的输入(可能是原始图像经过首层卷积之后的特征),
是第一个块的输出兼第二个块的输入,以此类推。这不是递归关系——递归是同一个函数反复调用自身;这里是不同的块依次处理,每个块有自己独立的参数,数据单向往前流动,不会回头。
把递推关系展开,可以看到最终输出的完整构成:
最终输出等于原始输入
加上所有残差块学到的补充信息之和。每个块只做加法,任何一块的输出都保留了之前所有层累积的信息,不存在某一层把前面的特征全部覆盖或丢弃的可能。信息只会越来越丰富,绝不会减少。这与普通CNN的情况形成对比:普通CNN每层输出是一个全新的张量,原始输入的信息随着层数加深会被不断变换,有可能在某一层被大幅改变甚至丢失。
值得注意的是,每个残差块的
并不是原始图像本身,而是到达这个块时的当前特征——它已经包含了前面所有块处理过后的累积信息。随着网络加深,特征越来越抽象,也越来越丰富。
信息累加的直观含义
用素描修改稿做类比。第一个块拿到原始素描(
),识别出"需要加深轮廓线",在原稿基础上加上了这个改动,产生
。第二个块接过
,识别出"需要补充阴影",加上阴影产生
。第三个块再加上纹理细节。每一步都在原有成果上叠加新的补充,最终的画是所有改动累积的结果,第一版素描的线条始终保留在最终版本中,没有被抹去。这就是残差块串联的工作方式,也是它比普通CNN更能保留特征的直观原因。
数学原理:梯度为什么不会消失
损失函数与参数更新的完整流程
在理解梯度如何流动之前,先把训练的完整流程说清楚。
训练神经网络的目标是:找到一组参数(所有卷积核里的数字),使网络的预测尽可能准确。训练过程循环执行以下四步:第一步,前向传播,把一批图像输入网络,依次经过每一层的计算,得到预测结果(比如每个类别的概率分布);第二步,计算损失,用损失函数(如交叉熵)比较预测结果与真实标签的差距,得到一个标量
,
越大说明预测越差;第三步,反向传播,计算
对网络中每个参数的梯度(偏导数),这个梯度告诉我们每个参数应该向哪个方向调整、调整多少;第四步,参数更新,用梯度下降法调整所有参数:
,其中
是学习率,控制每次调整的幅度。
梯度(gradient)的含义是:某个参数增加一个极小量时,损失
的变化量与该极小量的比值,即偏导数
。梯度为正,说明参数增大会导致损失增大,应该调小;梯度为负,说明参数增大会让损失减小,应该调大。梯度的绝对值大,说明这个参数对损失影响显著,需要较大幅度调整;绝对值接近0,说明几乎没有影响,不需要怎么动。
链式法则与梯度的逐层传递
梯度计算的数学基础是微积分中的链式法则(chain rule):若
,则
。神经网络是多层函数的复合,损失
对某个参数的梯度,等于沿着从该参数到
的计算路径上每一步局部导数的乘积。
以一个极简的残差块为例说明具体的计算过程。设
(卷积操作简化为标量乘法,
是参数),残差块的输出为
,损失函数为
。
计算参数
的梯度:
只通过一条路径影响
,即
,直接用链式法则:
其中
是因为
,对
求偏导,
是常数,结果为1;
是因为
,对
求偏导,
是常数,结果为
。
计算输入
的梯度:
这里是残差块数学上最关键的地方,也是最容易产生困惑的地方。
在
中出现了两次:一次在
内部(
,
在这里),一次直接加在后面(
公式中的那个裸
)。因此,
通过两条独立的路径影响了
,进而影响了
:
- 路径一(卷积路径):
- 路径二(skip connection路径):
(直接加进去)
根据加法的导数法则:若
,则
。两条路径对
的影响叠加相加,因为它们都独立地贡献了
对
的变化率。计算如下:
其中
(路径一,卷积路径的贡献),
(路径二,skip connection的贡献,任何量对自身的导数都是1)。
因此:
为什么这个+1根本性地改变了梯度的行为
现在把单个残差块的结论推广到整个网络,对比普通CNN和ResNet的梯度行为。
普通CNN(没有skip connection):从第
层往回传到第1层,梯度需要经过每一层的导数连乘:
每个
是一个小于1的数(经过激活函数和权重初始化后通常如此),连乘几十次后,结果指数级趋近于0。层数越深,梯度越小,前面的层越学不动。
ResNet:每经过一个残差块,梯度表达式中出现
而不是
:
无论
多小,只要不等于
,
就不会是0。连乘
不会像连乘
那样趋向于0,前面的层始终能收到有效的梯度信号。
这个"+1"从哪里来?它来自skip connection在正向传播时直接将
相加这个操作。正向时,加法让
以原始形式出现在输出里;反向时,这个
对自身的导数是1,沿skip connection传回去,不经过任何卷积层,不经过任何可能衰减梯度的运算,原封不动。skip connection 在反向传播中相当于给梯度开了一条高速公路:不管卷积路径的梯度衰减到多小,高速公路上的梯度始终完整地传回去。两条路径的梯度之和,永远不会是0。
这就是ResNet对反向传播贡献的本质:在链式法则的每一项里,永久性地加入一个1,使得无论网络多深,梯度都不会消失到0。
整体结构
ResNet-18 的完整层次
ResNet是一个纯编码器,将输入图像逐步压缩成低维的抽象特征向量,再输入全连接层进行分类。以ResNet-18为例,完整结构如下:
输入图像(224×224×3,RGB三通道)
↓ 7×7卷积,stride=2,64个卷积核 → BN → ReLU → 3×3最大池化,stride=2
(56×56×64)
↓ 残差块组1:2个Basic Block,64通道,不降采样
(56×56×64)
↓ 残差块组2:2个Basic Block,128通道,stride=2降采样
(28×28×128)
↓ 残差块组3:2个Basic Block,256通道,stride=2降采样
(14×14×256)
↓ 残差块组4:2个Basic Block,512通道,stride=2降采样
(7×7×512)
↓ 全局平均池化(Global Average Pooling)
(1×1×512,即512维向量)
↓ 全连接层(Fully Connected Layer)
(类别数,如ImageNet的1000类)
层数计算:1(首层7×7卷积)+ 4组 × 2块 × 2层卷积 + 1(全连接)= 18层,"ResNet-18"名字由此而来。ResNet-34、ResNet-50、ResNet-101、ResNet-152分别对应34、50、101、152层,层数越多,特征提取能力越强,但计算成本也越高。
以34层为例,计算方法是:1个首层卷积 + 第2组3个残差块×2层 + 第3组4个残差块×2层 + 第4组6个残差块×2层 + 第5组3个残差块×2层 + 1个全连接层 = 34。这里只计算卷积层和全连接层,BN、ReLU、池化等不计入层数。
五种 ResNet 变体的完整配置
论文给出了5种标准配置,它们的核心区别在于:层数 ≤ 34 用 Basic Block(两层3×3卷积),层数 ≥ 50 用 Bottleneck Block(1×1 + 3×3 + 1×1 三层卷积)。
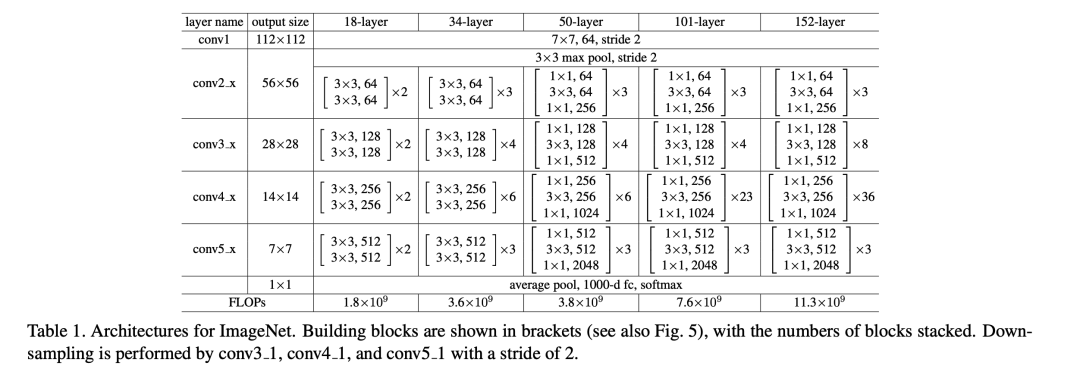
图片来自《Deep Residual Learning for Image Recognition》
层组 | ResNet-18 | ResNet-34 | ResNet-50 | ResNet-101 | ResNet-152 |
|---|---|---|---|---|---|
conv1 | 7×7, 64, stride 2 | ← | ← | ← | ← |
conv2_x | [3×3, 64] × 2 | [3×3, 64] × 3 | [1×1,64; 3×3,64; 1×1,256] × 3 | ← | ← |
conv3_x | [3×3, 128] × 2 | [3×3, 128] × 4 | [1×1,128; 3×3,128; 1×1,512] × 4 | [...]×4 | [...]×8 |
conv4_x | [3×3, 256] × 2 | [3×3, 256] × 6 | [1×1,256; 3×3,256; 1×1,1024] × 6 | [...]×23 | [...]×36 |
conv5_x | [3×3, 512] × 2 | [3×3, 512] × 3 | [1×1,512; 3×3,512; 1×1,2048] × 3 | ← | ← |
全连接 | 1000-d softmax | ← | ← | ← | ← |
参数量 | 1100万 | 2100万 | 2500万 | 4440万 | 6000万 |
可以看到,ResNet-50虽然层数比ResNet-34多16层,但参数量只多了约400万,原因正是Bottleneck结构把3×3卷积的通道数从256压缩到64来计算,大幅节省了参数。
与 VGG-19 的对比
理解ResNet需要知道它的对照物。论文在提出ResNet-34时,用了VGG-19作为基准参照。VGG-19是当时主流的深层网络,有19层,参数量约1.4亿,全程使用3×3卷积堆叠但没有任何跳跃连接。
ResNet-34在VGG-19架构基础上,做了两件事:一是把所有连续卷积块之间加上shortcut connections,二是去掉全连接层之间的冗余参数(用全局平均池化替代三层全连接)。结果:ResNet-34只有2100万参数,是VGG-19的约1/7,但深度更深、效果更好。这个对比直接说明了残差结构带来的参数效率提升。
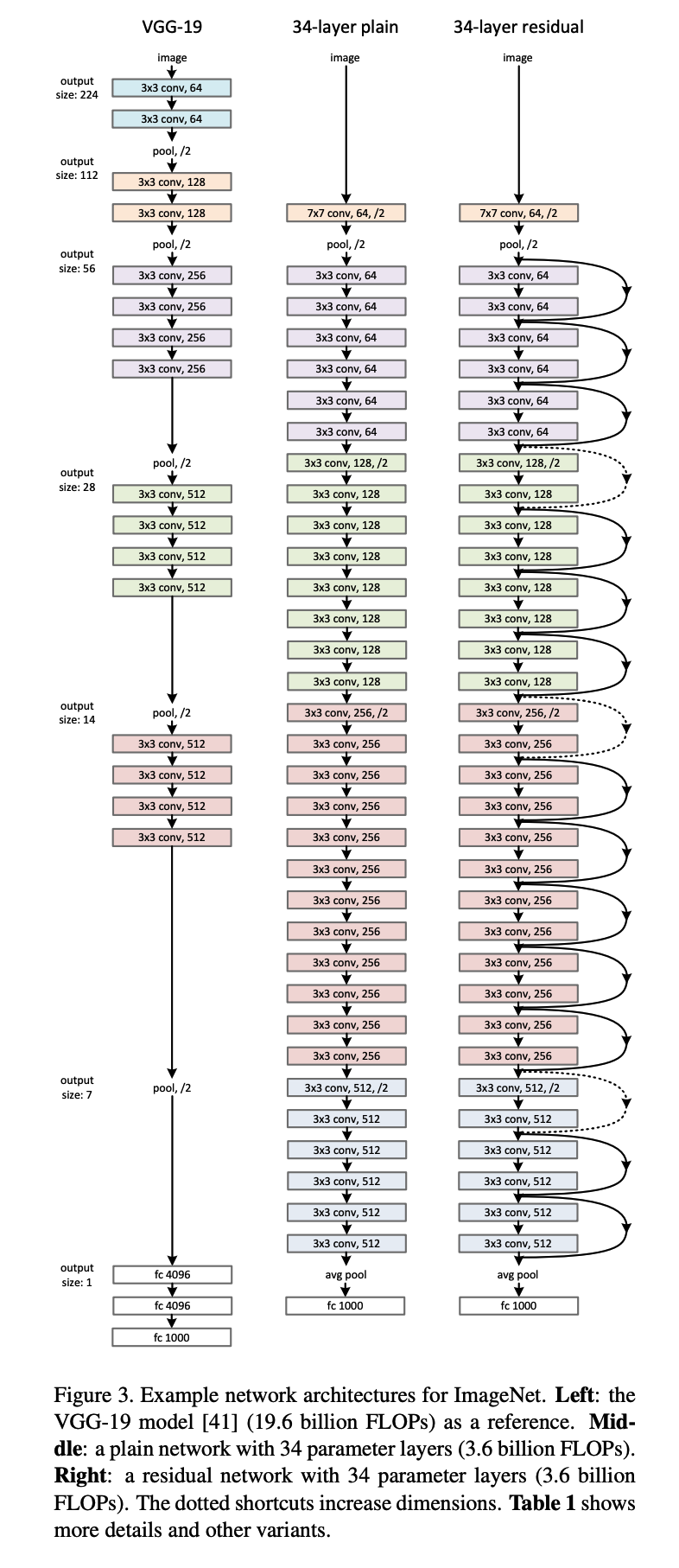
图片来自《Deep Residual Learning for Image Recognition》
空间压缩与通道增加的设计逻辑
随着网络加深,特征图的空间尺寸依次减半(224→56→28→14→7),通道数依次翻倍(64→128→256→512)。这个设计不是随意的,有明确的工程逻辑。
空间减半的目的是增大感受野。感受野(Receptive Field)是指特征图上某个位置能"看到"的原图区域大小。空间越压缩,每个格子代表的原图区域越大,能整合更宏观的上下文信息——浅层特征图每个格子只能看到局部的边缘,深层特征图每个格子能看到整个物体的轮廓。空间压缩通过在卷积时使用stride=2(步幅为2)实现,即卷积核每次移动2格而不是1格,输出尺寸自然减半。
通道翻倍的目的是补偿信息容量。特征图的总信息容量与
(高×宽×通道数)成正比。空间尺寸减半后,
缩小到原来的四分之一,如果通道数不变,总容量会大幅缩水。通道翻倍后,总容量变为原来的一半,虽然仍有损失,但幅度可接受。同时,深层需要表达更复杂的语义特征(从边缘到物体部件到整体语义),更多的通道数能容纳更丰富的特征模式。
维度不匹配的处理:当残差块的输入输出通道数不同时(如从64通道到128通道的转换),skip connection不能直接相加,因为两者形状不匹配。这种情况下,skip connection上会加一个1×1卷积(调整通道数)并配合stride=2(调整空间尺寸),使
的维度与
对齐后再相加。1×1卷积只改变通道数,不提取空间特征,额外引入的参数量最小。
两种残差块设计
Basic Block(用于ResNet-18/34):结构简单,两层3×3卷积,适合较浅的网络。
x → Conv3×3 → BN → ReLU → Conv3×3 → BN → (+x) → ReLU → 输出
Bottleneck Block(用于ResNet-50/101/152):引入"先降维再升维"的结构,大幅节省计算量,使更深的网络成为可能。
x → Conv1×1(降维,如256→64)→ BN → ReLU
→ Conv3×3(在64通道上提取特征)→ BN → ReLU
→ Conv1×1(升维,如64→256)→ BN
→ (+x) → ReLU → 输出
Bottleneck的核心逻辑是:3×3卷积是参数量最大的操作,如果让它作用在64通道上而不是256通道上,参数量减少到原来的
。两个1×1卷积负责通道变换,参数量很小。整个Bottleneck Block的参数量远低于两个3×3卷积直接作用于256通道,但感受野和表达能力相当。这使得ResNet-50虽然层数是ResNet-34的1.5倍,但计算成本并没有同比增加。
为什么这个设计有效
ResNet 可以理解为所有深度子网络的集成
有研究将ResNet的多个skip connection展开分析,发现整个ResNet等价于大量子网络的集成(Ensemble)。以3个残差块为例展开
,这个展开式实际上包含了"只走skip connection不经过任何卷积"(相当于0层网络)、"经过1个残差块的卷积"(相当于浅层网络)、"经过2个残差块"……直到"经过所有残差块"的所有可能路径,最终输出是这些路径输出的叠加。
这个视角解释了一个现象:即使极深的层因梯度过小而训练不充分,整体效果仍然好。因为有大量浅层子网络(经过较少残差块的路径)学到了有效特征,它们的输出构成了最终输出的主要部分。深层子网络只是锦上添花,即使效果差也不会拖累整体。这种"内置集成"的性质,使ResNet在训练早期(梯度还没完全传到深层时)就能有较好表现,训练稳定性远超普通深层CNN。
与 Highway Network 的对比
ResNet 有一个几乎同期提出的前辈:Highway Network(2015年)。两者的出发点完全相同——都是为了让梯度能顺畅地传过深层网络——但实现方式有根本差异。
Highway Network 借鉴了LSTM的门控机制,引入了一个可学习的门控函数
(值域在0到1之间),控制原始输入
有多少比例可以通过:
当
时,输出就是
(完全通过);当
时,输出就是
(完全由卷积决定)。网络自己学习
,动态调整每个位置的信息流比例。这个设计确实能让深层网络训练,但带来了额外的参数(
本身也是需要学习的)和更复杂的优化动态。
ResNet的设计更激进:直接去掉门控,固定地把
100% 加进来。这样做引入零额外参数,梯度流动更简洁——"+1"项没有任何学习的参数,永远以固定形式存在,不依赖于
是否被学好。事实证明,这个更简单的方案效果更好。
ResNet 胜出的核心教训:在相同目标下,更简单的方案往往更有效。去掉门控、直接相加,不仅没有损失任何能力,反而因为消除了门控参数引入的优化复杂性,让梯度传播更干净、训练更稳定。
与 UNet 的关系
ResNet 和 UNet 都使用了跳跃连接,思路表面相似,但设计目标和实现方式有本质区别。
ResNet 的 skip connection 跨度很短,通常只跨越2-3层,目的是解决梯度消失和退化问题,让深层网络能被有效训练。连接方式是相加(
),两份特征图对应位置的数字相加,形状不变,不增加通道数。
UNet 的跳跃连接跨度很长,将编码器某一层的完整特征图保存下来,直接传递给对称位置的解码器层。目的是让解码器在恢复空间分辨率时,能拿回编码器在该分辨率下保留的完整空间细节(边缘、纹理等),弥补池化操作造成的空间信息损失。连接方式是拼接(Concatenate),在通道维度上合并,通道数会翻倍,后续用卷积融合。
两者不是替代关系,而是针对不同问题的不同解法,可以同时使用。ResU-Net等变体直接将UNet编码器里的普通卷积块替换为ResNet残差块,同时获得两者的优势:残差块保证梯度传播,UNet的跳跃连接保证空间细节恢复。
优缺点
优点
解决了核心训练难题:skip connection + BN 的组合,系统性地消除了深层网络的退化和梯度消失/爆炸问题,使超过100层的网络能被有效训练。
更容易训练:梯度可以通过跳跃连接直接传播到浅层,允许使用更大的学习率,收敛更快,过拟合风险更低。
强大的特征表示能力:残差块让每层专注学习"增量",网络能更细腻地捕捉输入输出之间的关系,在图像分类、目标检测、语义分割等任务中表现全面领先。
参数效率高:以ResNet-34为例,2100万参数,比VGG-19的1.4亿参数少约85%,但效果更好。Bottleneck设计进一步压低深层变体的参数量。
极强的可扩展性:通过调整残差块的数量和通道宽度,可以在ResNet-18到ResNet-152乃至更深之间灵活扩展,同一框架适配从移动端到数据中心的不同算力需求。
缺点
计算资源需求高:深层ResNet(如ResNet-101/152)需要较高的显存和计算量,训练时间长,在资源受限的嵌入式或移动设备上部署困难。
对大规模数据依赖:模型越深,对训练数据量的需求越高。在小规模数据集上,深层ResNet容易过拟合,需要强力的数据增强和正则化来弥补。
维度不匹配引入额外复杂度:当残差块的输入输出通道数或空间尺寸不一致时,需要额外的1×1卷积做对齐,虽然参数量小,但增加了网络设计的复杂性,也可能造成轻微的特征失真。
在极小数据集上泛化能力有限:ResNet的设计假设是大数据场景。当训练样本非常有限时,浅层网络或专门为小数据设计的架构往往表现更稳健。
总结
把 ResNet 的完整逻辑串一遍。
问题来源:普通CNN叠深了会退化,原因有两个。一是深层网络的非线性运算组合无法自然地学出恒等映射,多余的层非但没有帮助反而引入噪声;二是反向传播中梯度经过每一层的局部导数连乘后趋向于0,前面的层无法收到有效训练信号。
ResNet的解法:在每个残差块里,用skip connection把输入
直接加到卷积输出上:
这一个加法同时解决了两个问题。
效果一(解决退化):卷积层只需学残差
,最坏情况
,输出等于输入
,网络不会因为这一块而变差。"网络再深也不退步"这个性质得到了保证。
效果二(解决梯度消失):
在
中出现两次,对
求导时通过加法法则得到两条路径的贡献之和,skip connection那条路径贡献固定的"+1":
这个"+1"不经过任何卷积,反向传播时原封不动地传回,使得无论网络多深,梯度连乘式中都保留这个不消失的项,前面的层始终能收到有效梯度。
多块串联的结果:多个残差块首尾相连,信息逐块累加:
最终输出是原始特征加上所有块学到的补充之和,信息只增不减,不存在丢失问题。
ResNet 的价值不是在相同层数下比普通CNN更准,而是解除了网络深度的上限,使训练100层乃至1000层的网络成为可能,且效果随深度真正提升。它出现后,整个深度学习视觉领域开始放心地构建极深网络。几乎所有现代视觉模型——目标检测(YOLO、Faster RCNN)、图像分割(UNet变体、DeepLab)、医学影像分析——都以ResNet或其变体作为特征提取的骨干编码器。理解ResNet,是理解现代深度学习视觉架构的必经之路。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号