AI 月趋势:大模型不值钱了,最贵的是你的“上下文”

AI 月趋势:大模型不值钱了,最贵的是你的“上下文”

随机比特
发布于 2026-05-21 18:14:27
发布于 2026-05-21 18:14:27
上个月写《AI 娱乐圈:鹅厂十年开发的 AI Agent 探索之路》的时候,留了三个判断:Scaffolding 大于 Model、框架战争让位给协议和管控面战争、以及从 Task-Driven 向 Goal-Driven 的演进。当时我保守地估计,这些判断至少需要半年时间才能在行业里得到验证。
结果,只用了三十天。
前端被戏称为"娱乐圈"是因为工具层出不穷,而 AI 的"娱乐圈"属性,体现在它用令人窒息的物理速度,把"未来"压缩成了"上个月的新闻"。5 月 18 日,The Decoder 报道 Cursor Composer 2.5 在编程基准上追平 Claude Opus 4.7 和 GPT-5.5。一个 10 人出头小公司的 IDE 插件自研模型,硬生生把两家估值千亿的最强模型厂旗舰按在地上摩擦,而价格只有它们的零头。 同一周内,各种并购、发版、静默安装接踵而至。
模型能力趋同之后,竞争焦点从"谁的模型更聪明"不可逆地切到了"谁拥有开发者和用户的触达入口"。在这个疯狂的五月,我看到的最核心的真相是:引擎不再稀缺,跑道才是。
这篇是上个月的续篇。它不是新闻综述,而是把这 30 天里我亲身经历和持续观察的几十个事件,提炼成系统性的结构趋势。
本文约 10000 字,阅读约 25 分钟。同样建议收藏后分章节阅读。
- Cursor 自研模型为何能追平旗舰大厂?
- AI 计价单位从 Token 变成 USD,你的钱包准备好了吗?
- Vibe Coding 在生产环境交的惨痛学费
- Agent 为什么终于有了自己的"Dockerfile"?
- 面对 AI 的子任务掠夺,工位上的"密度警报"该怎么破?
···
目录
- 第一章:引擎不值钱了——模型大爆炸与价值倒转
- 第二章:入口圈地运动——四条跑道的厮杀
- 第三章:计价单位的质变——从 Token 到 USD
- 第四章:跑道上的收费站——AI 成本工程的诞生
- 第五章:信任税——Vibe Coding 在生产环境交的学费
- 第六章:Skills 范式——Agent 终于有了自己的 Dockerfile
- 第七章:密度警报——组织拓扑的一刀
- 第八章:我的两个安静决定——人机边界的再划分
- 第九章:三个预判,下个月见
···
第一章:引擎不值钱了——模型大爆炸与价值倒转
先来看看过去这三十天里,发布或开源的"重磅"模型清单:
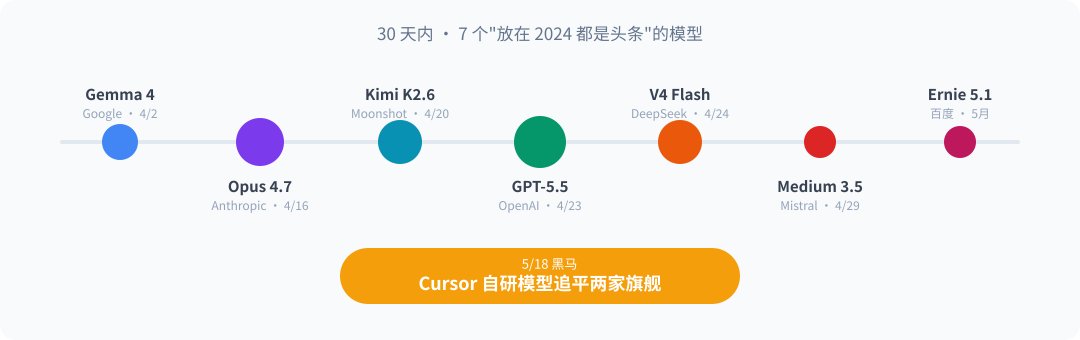
30 天模型大爆炸:任何一个放在 2024 都是头条
这份清单里的任何一个模型,如果放在 2024 年,都足以独占一周的科技头条。但在 2026 年 5 月的今天,它们扎堆发布,反而印证了一个残酷的事实:旗舰模型的能力差距,已经窄到撑不起它们之间的定价差距。
DeepSeek V4 的定价已经卷到了每百万 Token 输入 $0.14 的地步(Flash版本),连 antirez 亲自上手实战后都给出了极高的评价。而更具颠覆性的是 Cursor Composer 2.5。它用一个自研模型追平了两家最强旗舰。
这是怎么做到的?反直觉吗?其实不然。
上个月我抛出的第一个判断就是:Scaffolding > Model(脚手架大于模型)。 Cursor 的胜利,本质上是用 IDE 极度深度的上下文工程——代码图谱、项目感知、编辑历史树——弥补了其自研模型与 GPT-5.5 之间的原始算力差距。
当所有引擎马力趋同,决定一辆车能跑多快、跑多稳的,就是变速箱和底盘。 模型层正在以肉眼可见的速度商品化,就像 2015 年前后的云计算之争。当年大家还在比拼虚拟机的 I/O 性能,当差距缩小到个位数百分比时,竞争立刻变成了"谁的生态锁定更深"。
在这个前提下,几乎所有 2026 年的旗舰开源模型(DeepSeek V4、Kimi K2.6、Llama 4 等)都不约而同地采用了稀疏 MoE(混合专家)架构。MoE 的本质是拿推理成本换参数规模——大家都在比拼如何把"聪明"的价格打下来。
把这件事再往前推一步,你会发现一个更深的结构性变化:AI 的价值链正在倒转。
过去,模型公司靠卖"智能"收费,工具和 SDK 都是倒贴白送的。现在?模型厂在拼命降价甚至开源,反而是工具层(IDE、浏览器、基础设施平台)开始筑起收费站。
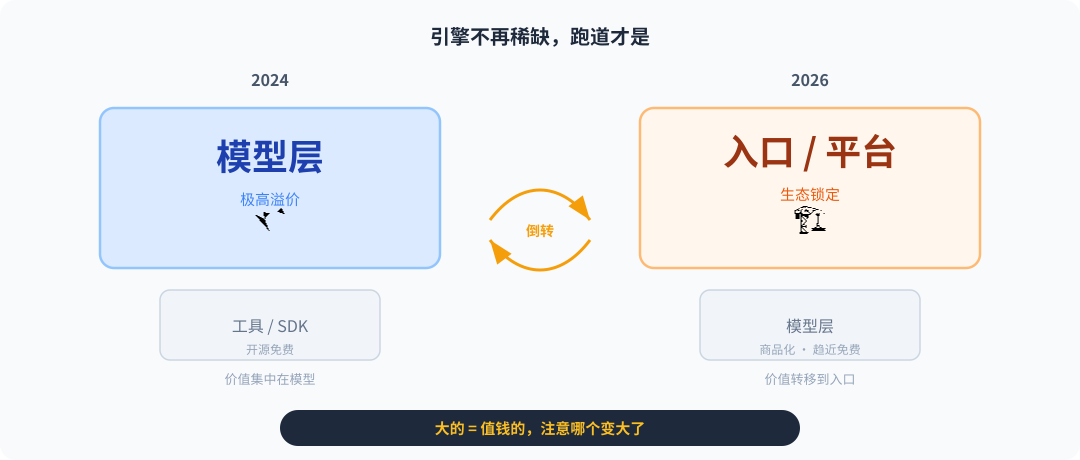
AI 商业模式倒转:引擎不再稀缺,跑道才是
这意味着一件对每一个开发者都无比现实的事:
你仓库根目录下的那份
CLAUDE.md或者.cursorrules,可能比它背后调用的那个千亿参数的大模型更值钱。
为什么?因为大模型你随时可以切走(今天用 Opus,明天切 DeepSeek),但是你日积月累攒下来的项目上下文、领域知识、架构约束和工作流配置,是谁也偷不走、且难以轻易替换的血肉。
工程建议: 别再去刷各种新模型的 Benchmark 榜单了,把你的业务上下文(CLAUDE.md / 项目说明书)写好。模型是流水打来的铁,你的上下文才是永远不变的营盘。
你最近一个月换了几次主模型?是出于什么原因?评论区聊聊。
···
第二章:入口圈地运动——四条跑道的厮杀
模型一旦商品化,随之而来的必然是跑马圈地。这个月,四条跑道上同时打响了刺刀见红的入口保卫战。

入口圈地运动:四条跑道的厮杀
第一条跑道:浏览器入口。 5 月 6 日,Hacker News 冲上 1404 分的热帖爆出:Chrome 在用户不知情的情况下,后台静默下载了 4GB 的 Gemini Nano 权重文件。随后 Google 被发现悄悄撤回了"端侧 AI 不会把数据发回服务器"的承诺。 浏览器是全球最庞大的软件分发渠道。当 Chrome 开始把模型作为基础设施静默分发时,它就不再仅仅是一个渲染引擎了,它变成了 AI 的"原生操作系统"和运行时。Mozilla 试图公开反对 Chrome 的 Prompt API,但在绝对的市场份额碾压面前,抗议显得苍白无力。
第二条跑道:IDE 入口。 Cursor 自研模型的崛起并非偶然,当一个 IDE 公司每个月交给 Anthropic 和 OpenAI 的 API 账单已经超过了自身的营收,自研模型就从"战略选项"变成了"求生本能"。 与此同时,OpenAI 开始反攻,把 Codex 塞进了 ChatGPT 移动端(含免费版),试图用 C 端流量降维打击。Google 也在内测全免费的 Antigravity IDE。现在的局面是:IDE 厂在疯狂搞模型,模型厂在拼命做 IDE。开发者选择工具的本质,早已不是"谁写代码更溜",而是"我这套工作流要锁死在哪个生态里"。
第三条跑道:SDK 和平台。 Anthropic 斥资收购了 Stainless(一个从 OpenAPI spec 自动生成多语言 SDK 的平台),背后的逻辑极其清晰:谁拥有了 SDK,谁就拥有了开发者的 import 语句。而 import,是这个世界上最深的锁定。 OpenAI 则搞出了 DeployCo 子公司,挨家挨户帮企业做 AI 私有化落地,俨然一副要抄 Palantir 剧本的架势。
第四条跑道:开源社区入口。 DeepSeek-TUI(被戏称为"DeepSeek 版的 Claude Code")登顶了 GitHub Trending。mattpocock/skills 单日暴涨 7429 个 Star,obra/superpowers 更是冲上了 19.4 万 Star。 开源社区的争夺从来不靠砸钱,而是靠"谁能率先成为默认选项"。一旦某种设定(比如 CLAUDE.md)成了项目标配,那它背后的工具就不再是工具,而是整个生态的咽喉。
工程建议: 选型时,优先选择那些不会死死锁定你工具链底层、且支持标准协议(如 MCP)的生态。保护好你的
import语句和入口控制权。
你的工作流现在被哪个大厂的生态锁得最深?
···
第三章:计价单位的质变——从 Token 到 USD
在讨论收费站怎么建之前,必须先看清这个月发生的一件惊悚的事:Agent 的行动半径发生了不可逆的质变。
仅仅在一个月前,我们对 Agent 边界的认知还是极其温和的:读读文件、改改代码、调个内部 CLI、跑一下单元测试。就算它全盘崩坏,大不了终端敲一行 git reset --hard,世界瞬间恢复清明。
但在 5 月 6 日,Cloudflare 发布了一条完整的 Agent 链路:Agent + Stripe + Domain + Pages。
这意味着什么?意味着一个 Agent 现在可以自己去跑去注册账户、绑定信用卡、买下域名、然后直接将服务部署上线。每一步操作,都是不可回滚的状态变更。信用卡扣了钱,账单就生成了;域名注册了,钱就没了;服务上线了,你的业务就直接暴露在了公网上。
更让人不寒而栗的是这套链路出厂的默认值。Cloudflare 自带了一个 Spending Cap(支出上限),每个供应商每月默认是 100 美元。这绝不是一个温情脉脉的"你可以选择给它配预算",而是粗暴的"它出厂就自带月度预算,你要么接受,要么手动调低"。当你调高那个数字的那一刻起,治理系统崩溃带来的真金白银的损失,责任就完完全全转移到了你手里。

Agent 计价维度的残酷质变
以前我们调 API 的心情像是拧水龙头,流的都是分分钱;现在给 Agent 赋权的心情,像是在给未成年的熊孩子刷信用卡副卡,一不小心它就去给你买辆跑车。
过去,我们给 Agent 配置一个 API Key,脑子里盘算的不过是"它这个月能跑多少个 Token,能调多少次 API"。从这一刻起,你需要思考的是:"它这个月能花掉我多少美元(USD)?"
计价单位从 Token/Call 变成了真金白银的 USD。
就在同一周,Anthropic 顺势推出了 Claude for Small Business,里面的 15 个 agentic workflow 包含了 payroll planning(工资规划)、invoice chasing(账单催收)、closing the month(月末结账)。每一个工作流,都直接把手伸向了钱箱。
过去 Agent 犯错,顶多给你返回一段编译不通过的烂代码;现在 Agent 犯错,代价是疯狂扣钱、耗尽云资源、甚至上线了一个充满漏洞的暴露服务。
这宣告了传统的 Agent 治理手段(依靠简单的留痕、observability 和 eval)已经完全破产。你现在需要的,是一套完整的资源治理系统。
# 以前的 Agent 配置 (天真时代)rate_limit:"1000/min"max_tokens:"100000"# 现在的 Agent 资源治理 (铁血时代)spending_cap:"$100/month"allowed_actions: ["read", "write_code"] require_human_approval: ["purchase_domain", "deploy_to_prod", "modify_payroll"] 工程建议: 必须立刻为你的 Agent 系统引入财务和资源维度的"熔断机制"。你不能只防死循环,你必须防破产。
你敢给现在的 Agent 绑定一张真实的信用卡吗?为什么?评论区聊聊。
···
第四章:跑道上的收费站——AI 成本工程的诞生
既然 Agent 能花大钱了,巨头们在跑道上立收费站也就显得理直气壮了。
5 月 13 日,Anthropic 宣布了一个影响深远的计费变更(6月15日生效):他们将 Agent SDK 计费彻底分拆。未来的订阅额度将被拆成两个隔离的池子:一方产品(比如官网对话和官方的 Claude Code)共用一个池,而 Agent SDK(第三方开源 Agent、命令行工具、GitHub Actions 等)单独放进另一个池,按 API 的昂贵费率计价,并且不可滚存。
社区里有大佬算了一笔账:按照典型的 agentic 复杂负载,这一波操作相当于等效涨价了 12 到 175 倍。曾经那种靠着几十块钱低价包月订阅,在本地狂跑高并发昂贵 Agent 负载的"算力套利"黄金窗口,被砰的一声重重关上了。
不仅是 Anthropic,4 月 27 日 GitHub Copilot 全面切换成了用量计费,不仅把 Opus 模型从标准 Pro 版里下架,个人版甚至直接暂停了新注册。AI 编程的"包月党黄金时代"就此落幕。 国内这边,5 月 4 日豆包推出了付费订阅(标准 68/加强 200/专业 500 元每月)。"To C 全免费"的国内大模型烧钱战也踩下了刹车。
再来看另一组数据:Uber CTO 透露,公司年度的 AI 预算在开年前几个月就被耗尽;Amazon 内部把 AI 用量做成了排行榜,逼得员工为了冲榜,开始用 AI 制造无意义的 AI 循环工作(社区戏称 tokenmaxxing);字节跳动 2025 年净利润下滑超 70%,而 AI 投入是最大的增量支出。
把这些事件拼图放在一起,一个清晰的判断浮出水面:AI 的免费午餐不仅已经结束,所有人都在变着法地大涨价。
往深一层看,这不仅仅是涨价,这是一次底层商业逻辑的身份切换。 过去三十年,互联网软件企业的成本曲线极其性感:研发费用当年消耗、当年入账,边际成本趋近于零,毛利 70% 起步。资本市场给出的也是 30-60 倍的高市盈率。 但是电网公司呢?重资产投入,极其漫长的十数年折旧,市盈率常年趴在 8-12 倍。

身份切换:从互联网软件 到 电网基础设施
AI 现在在做的,就是把电网公司的重资产支出结构,硬生生塞进了互联网企业的财报里。庞大的 GPU 集群、自建的超算数据中心、锁定十年的天价电力合约,每一项都是基础设施的核算口径。成本曲线彻底变了,但估值方法还没跟上。
字节的 70% 利润下滑,百度把 Ernie 降价 94%(因为即使亏着卖,也比数据中心空转折旧强),这都是电网的逻辑,不再是软件的逻辑。
这意味着什么?意味着在 2026 下半年,对我们这些开发者来说,最重要的核心技能已经不是怎么写出花里胡哨的 Prompt,而是**AI 成本工程(AI Cost Engineering)**。
你必须门儿清:哪些重度推理任务该切给旗舰(Opus),哪些轻量总结该路由给便宜的 DeepSeek V4,哪些流水线应该跑本地的 Llama,以及最关键的——哪些需求根本就不该用 AI。
工程建议: 开始在你的团队里建立并维护一张"模型路由表"。日常简单、高并发的任务坚决切向低成本模型,只有在极深层逻辑推演时才动用旗舰。做不到精细化路由,你的预算活不过三个月。
你所在团队的 AI 预算今年超标了吗?最后是怎么解决的?
···
第五章:信任税——Vibe Coding 在生产环境交的学费
抛开商战和收费,五月最让人揪心的是密集爆发的安全事故。这些事故揭示了 Vibe Coding(那种不写设计、直接让 AI 自由发挥的爽快开发模式)在生产环境里必须交的学费。
以前写代码叫“面向 StackOverflow 编程”,大不了就是跑不通报错;现在叫“面向幻觉 Debug”,你不仅不知道它写了什么,你甚至不知道它在刚才那 9 秒钟之内删掉了你什么。以前是代码有 bug,现在是系统有爆破危险。
4 月 28 日,某开发者用 Claude Code 仅仅花了 9 秒钟,就干净利落地删掉了一家 110 人规模公司的生产环境。这口锅该让 Agent 背吗?不。根本原因是这个组织从未在架构上设计过"破坏权预算"。没有二次确认,没有冷却期,没有任何机制拦截不可逆操作。AI 只是极其高效地执行了命令,暴露了原本就千疮百孔的系统。
5 月 6 日,Cursor 某款热门扩展被扒出可以窃取开发者的令牌。这同样不是 Cursor 有意作恶,而是 IDE 插件体系的设计前提(扩展不可信)与实际实现(扩展却能读取 .env,甚至注入 Prompt)之间的巨大缝隙。
到了 5 月 13 日,TanStack 的 42 个 npm 核心包遭遇劫持。The Decoder 披露有 AI Agent 在漏洞公开后仅仅花了 30 分钟,就把安全补丁逆向还原成了可用的 Exploit 工具。传统的 90 天漏洞修复披露窗口,在不知疲倦的 Agent 面前形同虚设,名存实亡。
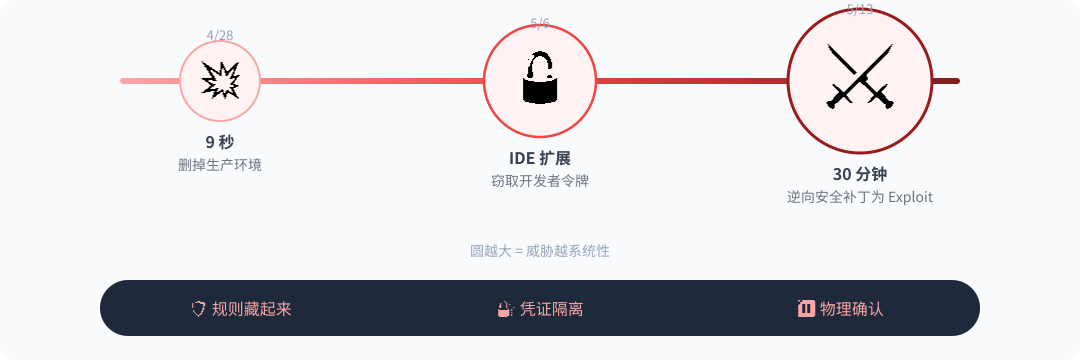
信任税:Vibe Coding 30 天安全事故升级
表面看,这些事故各自独立。但站在 Agent 系统架构的视角,它们全都是同一个逻辑谬误的不同切面:信任边界被画在了致命的错误位置上。
社区开始本能地自卫: Zig 语言核心团队明文规定,严禁提交"主要由 LLM 生成、且贡献者自身都未完全理解"的代码 PR。 Ghostty 离开 GitHub 转投自建基建,引发了对云端 AI 基础设施绑定的深度反思。 arXiv 全面收紧稿件规范,一旦发现由 AI 产生的"幻觉引用",直接禁投一年。
上篇我写过,Vibe Coding 就是一个美丽的陷阱:前三天快感爆棚,到了第 14 天,技术债会以 10 倍复利反噬。这个月血淋淋的事故,就是行业对这句话的集体背书。
在这个时代,有三条必须用血写成的硬原则: 1. 规则必须藏在模型摸不到的地方。 2. 凭证必须放在第三方代码碰不到的地方。 3. 破坏性操作必须有不可绕过的物理确认窗口。
如果做不到这三点,你的系统规模越大,爆炸时的当量就越惊人。
然而,换个角度想,"信任税"这个词不应该仅仅被视为一种沉没成本。信任正在从一种纯粹的成本,演变成一种极具溢价的产品。 就像十年前,云安全从一张枯燥的"合规检查清单",一步步进化成了价值连城的 SOC 2 认证和加密合规可用区。未来在 Agent 领域,谁能最先打包卖出"经过绝对验证的 Agent 沙箱执行环境",谁就能赚取 AI 时代最丰厚的安全红利。
工程建议: 今晚就去检查你的 Agent 工作流。三条硬红线:规则必须藏在模型摸不到的地方;凭证必须放在第三方代码碰不到的地方;破坏性操作必须有不可绕过的确认窗口。
你遇到过 Agent 差点(或者已经)搞挂生产环境的惊险时刻吗?
···
第六章:Skills 范式——Agent 终于有了自己的 Dockerfile
在纷繁复杂的商战和层出不穷的安全事故背后,有一股安静却意义深远的工程浪潮正在汹涌成型。这也是上个月我做出的最后一个预测的完美落地。
上篇我提到,从 Task-Driven(任务驱动)走向 Goal-Driven(目标驱动),需要五个铁打的前置条件:目标清晰、边界清晰、状态可见、过程有迹、权限可控。这个月,随着 Claude Code v2.1.139 的发布,带出了 Agent View 和正式的 /goal 命令,Goal-Driven 从 PPT 上的概念图,真正落到了冷冰冰的命令行里。
但更底层的技术地震并不在这几个命令上,而在于社区对 Agent 上下文工程 的共识爆发。
前文提到过,mattpocock/skills 仓库单日狂涨 7429 个 Star,Addy Osmani 发布的 agent-skills 同样斩获 3.3 万 Star。Latent Space 在 5 月 13 日发了一篇标题极具煽动性的雄文:"The End of Finetuning"(微调的终结)。文章核心观点是:传统的模型微调时代,正在被"超长上下文 + 丰富的工具调用 + Skills 编排"无情取代。
什么是 Skills 范式? 它的核心思路颠覆了以往的习惯:我们不再试图通过笨重昂贵的微调去让模型"学习"业务逻辑,而是直接写一份高度结构化的声明文档,明明白白地告诉模型当前所处的业务环境是什么。
你项目根目录下的 CLAUDE.md 就是最典型的例子。它是一份详尽的项目说明书,Agent 只要读完,瞬间就能掌握这个仓库的代码规范、测试跑法、架构约定和各种禁忌。
这听起来是不是非常耳熟?没错,这就是 Docker 的逻辑。
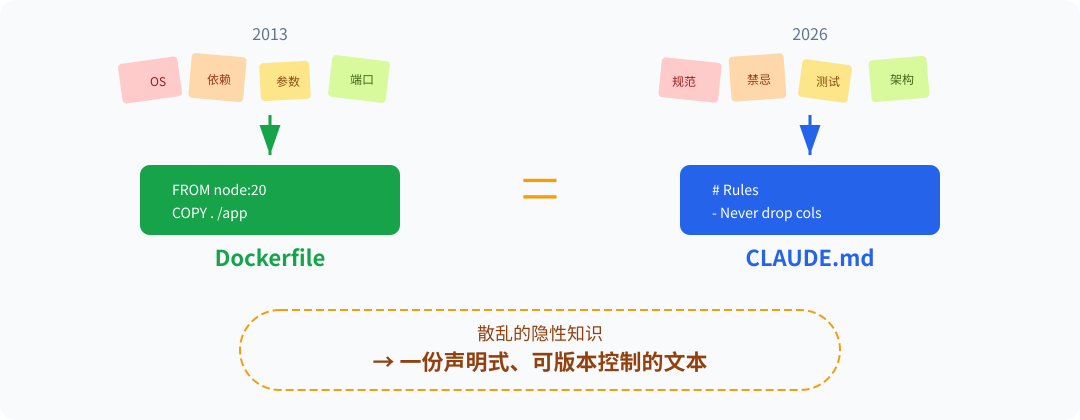
架构史的同构映射:Agent 终于有了 Dockerfile
2013 年之前,我们要部署一个应用,得苦哈哈地手动配 OS、装依赖、调环境参数。然后 Dockerfile 横空出世,把所有环境配置浓缩成了一份版本可控、可复用、可组合的文本。
现在,Skills 就是 Agent 时代属于上下文工程的 Dockerfile。
# 典型的一个 Skill 声明 (类 Dockerfile 范式) name: "Database Migration Skill" description: "How to safely run schema changes in this project" rules: - "Always backup before running ALTER" - "Never drop columns in v1, deprecate them first" - "Review the exact query against `schema_lint.sh`" 上篇我说 "Scaffolding > Model",而 Skills 范式正是这个论断在工程上的极致表达。框架(如 LangChain)解决的是 "Agent 该怎么跑"的流程问题,而 Skills 解决的则是 "Agent 在跑的时候脑子里该装哪些常识" 的上下文问题。
后者,才是决定 Agent 最终产出是工业级成果还是精美垃圾的核心变量。
工程建议: 放弃用微调来解决业务常识问题,那是一条昂贵的死胡同。开始建立你项目的 Skills 库,用长上下文和声明式的约束文档来精确指导 Agent。
你们团队现在是迷信微调多,还是开始拥抱类似 Skills 的上下文工程了?
···
第七章:密度警报——组织拓扑的一刀
技术在重塑架构,同时也开始重塑我们身边的工位。
5 月 7 日,Cloudflare 毫不手软地一次性裁掉了 1100 多人,约占员工总数的 20%。创始人在公开信里写得非常直白且冰冷:"这不是为了单纯的降本增效,也与员工的绩效无关。这是为了重新定义一家高速增长的公司,在 agentic AI 时代到底该怎么运转。"
要知道,在此前的三个月里,Cloudflare 内部的 AI 各种使用量暴涨了 600%。这不是一家现金流撑不住的落魄公司,这是一家主动拿起手术刀,把自己的组织拓扑切了一大块的狂飙巨头。
这种事并不新鲜。如果你把时间拨回上世纪 90 年代,美国的电话客服中心走过一模一样的轨迹。当 IVR(按键语音导航,"查询余额请按1")刚出来的时候,并没有哪家公司立刻大规模砍掉客服人员。最初,只是那些"查余额、改密码、问账单"等高频、标准化的子任务被 IVR 悄悄"抠走"了。 当这种抠走达到了一定的密度,一个客服每天能接到的"真正需要人类情感和复杂判断"的电话数量锐减,这个时候,编制才会被一刀刀砍下。当年砍掉的不是"客服"这个光鲜的岗位名称,而是被 IVR 吞噬的那一半工作量所对应的"人头"。
今天,LLM 就是 2026 年的 IVR。 唯一的区别是,这一次它能抠走的子任务密度极高,覆盖极广。
AI 抢走的从来不是一个完整的、体面的岗位角色;它抢走的,是你每周必须要做的 50 件事里,那 30 件低于 5 分钟上下文的子任务。
剩下那 20 件呢?判断极其罕见的边界情况、跨系统定位极难复现的根因、或者给团队定下半年的宏观方向——这些事 AI 确实做不了,但问题是,这 20 件事的工作量,已经撑不起你原来的全职编制了。
这是一道冰冷残酷的管理学算术题:老板给你发工资,是按"完整编制"算的,绝不是仅仅为你那"40% 不能被委托的复杂判断"买单。当你的工位上 60% 的产出被大模型悄无声息地抠走后,养你一个人的成本,在财务报表上就算成了两个人。这不是什么经济学原理不答应,这是底层的组织拓扑结构不答应。
于是,荒诞的一幕出现了。就像 Amazon 把 AI 用量做成了强制的内部排行榜,导致员工开始用 AI 去制造毫无意义的 AI 工作一样。管理学有条铁律:度量什么就会扭曲什么。当"把工作甩给 AI"本身变成了 KPI 时,员工的自保本能被彻底激发。
以前公司裁员,HR 还需要绞尽脑汁给你找个绩效垫底的理由;现在的裁员理由极其极客:不好意思,你的岗位上下文厚度不够,不配拥有独立的人类线程。
我这里有一份自检清单。你可以打开下周的日历,或者你的 TAPD(需求管理系统),把你手头的活儿按具体动作一条条列出来,然后冷酷地问自己一个问题:
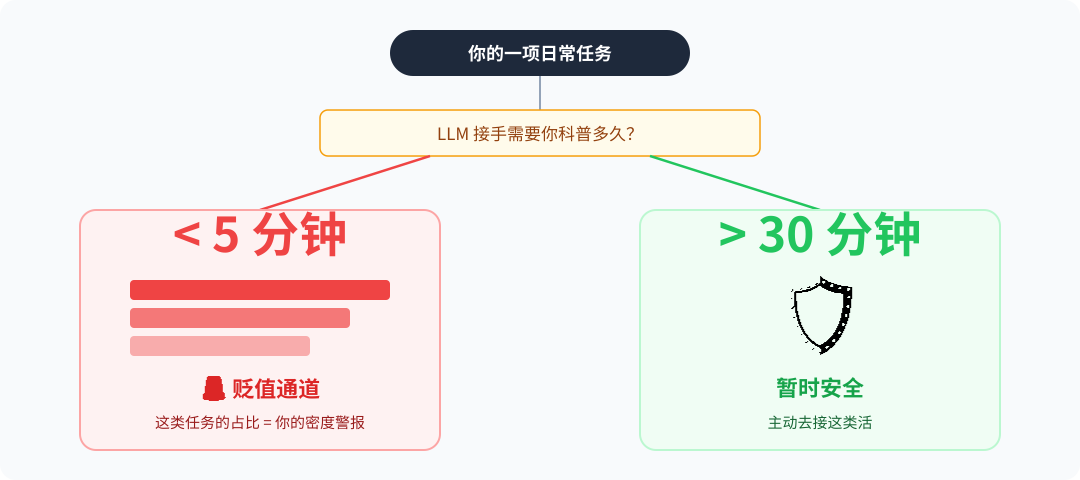
程序员自救指南:“密度警报”工位自查表
"这件事如果换成 LLM 来做,它需要吸收多长时间的专属上下文?"
- 高于 30 分钟人工细致讲解 = 你的工位暂时安全。
- 低于 5 分钟就能把上下文全交代清楚 = 这项工作已经在极速的贬值通道里。
那一堆"低于 5 分钟"子任务在你工作里的占比,就是你工位上方正在狂闪的"密度警报"。
非工程建议: 打开日历,按动作列出清单。问自己:这件事换 LLM 来做,需要的人工上下文是不是低于 5 分钟?如果是,想办法去承担那些需要深厚系统历史认知和跨团队斡旋的脏活累活。
你的日常工作里,有多少比例是"低于 5 分钟上下文"就能让 AI 接手的?
···
第八章:我的两个安静决定——人机边界的再划分
在外面行业吵得沸沸扬扬的时候,作为一个每天还必须亲自下场写代码的开发者,这个月我悄然做出了两个改变日常工作方式的不起眼的决定。
我的两个安静决定:人机边界的再划分
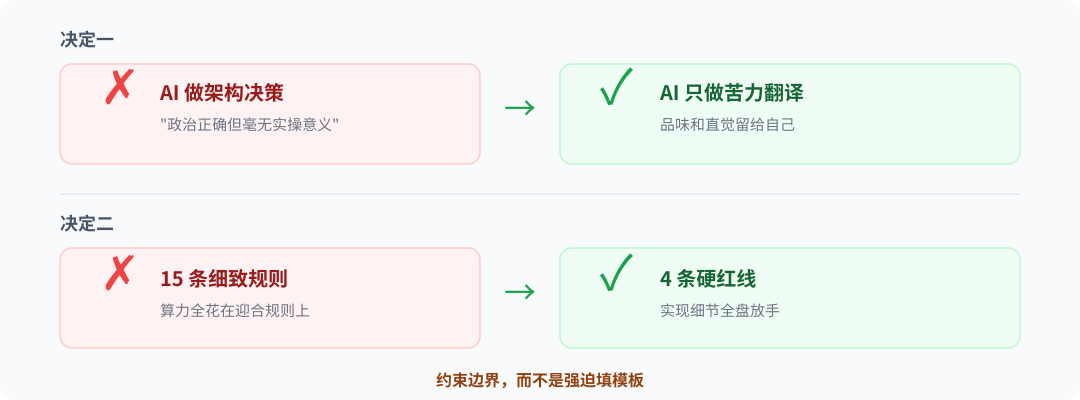
第一个决定:让 AI 停止做架构决策,退回代码翻译。
以前,我总是痴迷于让 Agent 帮我做技术选型、重构复杂模块架构。然而,跑了一段时间后我无奈地发现:在"品味"和"技术前瞻性判断"上,AI 实在太糟了。
让它分析到底该用哪种并发模型,它能给你列出洋洋洒洒八百字、符合所有维基百科真理的对比表,但得出的结论往往是"政治正确但毫无实操意义"。
于是,我切断了这个越界的赋权。现在我的工作流变成了:让 AI 去干那些信息密度极高、规则绝对明确的苦力活(比如把老接口翻新成 TypeScript、补齐海量的单测代码、处理正则转换),而把需要审美、品味、直觉和复杂商业判断的架构决策,死死攥在自己手里。品味是一种只可意会不可言传的隐性知识,目前你根本无法通过一堆 Prompt 把它传授给大模型。
这不是人类的退让,这是最为高效的系统分工。
第二个决定:把 Agent 的 Prompt 从繁琐的"评分标准模板"改成了极简的"兜底红线"。
之前,我在给 Agent 编写 Prompt 时,密密麻麻地塞了十几条代码生成规则,企图让它完美无缺。结果呢?规则定得越细致,它的产出就越死板。它所有的算力都在为了"迎合满足规则"而工作,而不是为了"把这个业务逻辑写出彩"而创造。
我痛定思痛,挥刀砍掉了所有细枝末节的"怎么写",只留下四条不可逾越的硬红线:绝不允许使用未验证的魔法黑盒库、绝不能改变原有的入参出参结构、严禁硬编码秘钥、必须抛出带上下文的异常。至于实现细节,全盘放手。
奇迹发生了,产出的代码质量和灵动性立刻跃升了一个大台阶。
这里蕴含着一条对所有开发者都普适的铁律:给高级 AI 的指令,应当是约束其行为边界,而不是强迫它填写死板的模板。 只有在宽广的边界内自由驰骋,智能才会有创造性;死盯着模板填空,得到的永远只有毫无生气的合规性。这跟 Skills 范式的底层逻辑如出一辙——一份优秀的 CLAUDE.md 告诉 Agent 的是"在这个仓库里绝对不能干什么",而不是手把手教它"第一步干啥第二步干啥"。
工程建议: 给你配置的 Agent 写 Prompt 时,少写"你应该怎么做",多写"你绝对不能做什么"。留下足够的留白空间,你才能收获真正的智能红利,而不是死板的填空题答卷。
你在写 Prompt 的时候,是更喜欢巨细无靡的模板,还是划定底线的规则?
···
第九章:一点前瞻 ——下个月可能会发生的 3 件事
上个月我抛出的三个判断,在这个波澜壮阔的三十天里被现实逐一验证。今天,我再留下三个更为具体、更具杀伤力的预判,我们下个月来复盘。
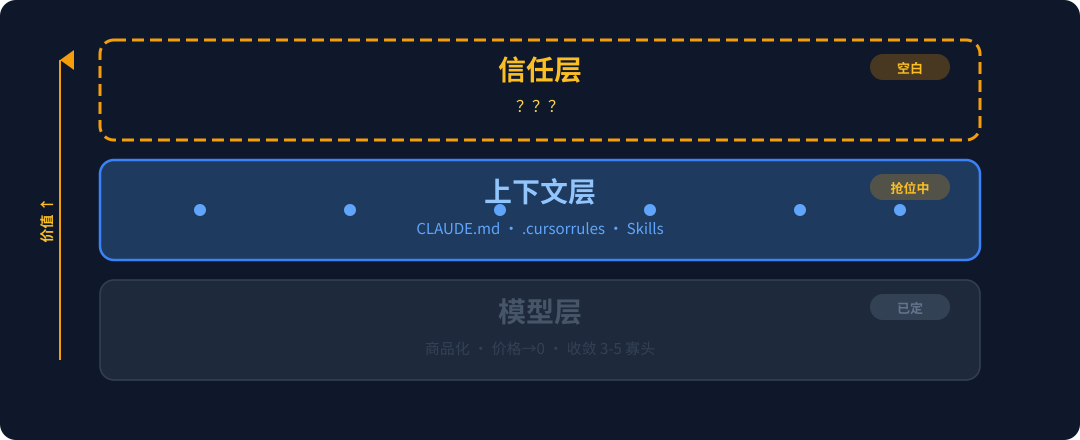
趋势一:AI 技术栈将彻底分裂为三层,并各自独立展开残酷竞争。
预判一:AI 技术栈彻底分裂为三层
回顾五月的混战,本质上是三个物理层在剧烈重组:
- 模型层:不可逆的商品化,价格一路狂奔向零。MoE 架构直接碾平了旗舰性能的绝对差距。这一层的玩家最终会快速收敛到 3-5 家寡头。
- 上下文层 (Context Layer):无论是
CLAUDE.md、.cursorrules还是copilot-instructions.md,形态千变万化,本质如一:告诉 Agent 你的业务到底是什么。这一层沉淀的价值正在迅速超越模型层本身,因为模型如衣服随时可换,但上下文是你的肉身。Skills 范式的全面爆发,就是上下文层独立出来的最强信号。 - 信任层 (Trust Layer):这目前是一片令人不安的混沌。这块拼图包含了执行沙箱(Agent 到底能碰哪些命令)、审计日志(操作如何无损回溯)、供应链验证(调用的三方工具是否带毒)以及权限声明(类似于 K8s 的 PSP)。这四块拼凑起来,才是完整的信任层。而在三大层中,只有信任层至今还没有属于自己的、被广泛接受的"Dockerfile"。下一个百亿级的基础设施大机会,就藏在这片空白里。
下个月看点:上下文层是否会出现跨大厂工具的标准化开源提案?信任层是否会跑出一个拥有统治力的开源框架?
趋势二:6 月 15 日 Agent SDK 计费池的分拆,将直接引爆生产级的"模型路由"需求。
Anthropic 这一刀极其狠辣,把第三方 agentic 负载从订阅池踢出去按高昂的 API 费率计价。但这不会逼走真正的开发者,反而会逼迫他们立刻开始极其认真的模型路由 (Model Routing):极其简单的文字处理立刻切给 DeepSeek V4 Flash(仅需 $0.14),中等复杂度的任务丢给 Mistral,唯有遇到极深的复杂逻辑推演,才会咬牙调用 Opus 4.7。
这不是什么小打小闹的成本优化技巧,这标志着一门全新工程学科的诞生。就像当年微服务架构的繁荣催生了服务网格(如 Istio / Envoy)一样,Agent 负载极其恐怖的成本压力,将直接催生出 "模型网格 (Model Mesh)"——一套能够根据实时查询复杂度和预算上限,自动将任务分配给最合适模型的底层路由基础设施。
下个月看点:6月15日之后,那些主打极低成本的 API(如 DeepSeek V4)流量是否会出现跳升?第一个好用的生产级模型路由中间件是否会杀出重围?
趋势三:端侧 AI 将在六月拿到真正的操作系统级战略地位。
Chrome 静默强推 Gemini Nano 仅仅是个狂野的前奏。随着 Google I/O 2026 的开幕,外界高度预期 Android 17 会直接把 Gemini Intelligence 强行揉进操作系统的核心服务层。如果 Apple 在 6 月的 WWDC 上紧紧跟进,将大模型推理能力深度集成进 Core ML 框架之中,那么,"通过网络去调云端 API"将不再是开发 AI 应用的默认第一选择。
开发者将被迫面临一个关乎生死的架构路线大分叉:到底是端侧优先,还是云端优先?
这个分叉的后果,将比单纯的模型之争大出几个量级。端侧模型直接啃噬的是用户的本地物理算力,它不产生任何云端 API 调用。对于那些目前靠卖 API 调用次数苟活的模型公司(比如 OpenAI 和 Anthropic 的通用 API 业务)来说,这意味着直接被掐断了接触用户的终极分发渠道。
下个月看点:Apple 在 WWDC 上是否会发布足以改变格局的系统级 AI 推理框架?Android 17 的底层智能引擎,是对所有开发者完全开放,还是将其牢牢闭锁在 Google 自家的应用护城河内?
···
结语:Agent 不再是工具,正在变成环境
上篇我总结的三个判断——Scaffolding > Model、框架向协议演进、从 Task 走向 Goal——本质上是在描述 Agent 如何完成工程化。但五月的事实粗暴地把进度条向前推了一大截:这不仅是维度,这已经是三个正在物理分离的独立生态层。
模型在商品化,上下文在急剧标准化,而信任层依旧在黑暗中摸索。这三层进化进度的落差,造就了当下 AI 行业最惊心动魄的结构性机会:模型层的大门已经对创业者重重关上,上下文层正处于惨烈的跑马抢位期,而信任层,还是一片生机盎然的空白。
但这个月教给我的,远比这冰冷的三层架构要深刻得多。
上篇结尾我写下"增强自己而非替代自己"。这话背后藏着一个傲慢的假设——我们以为"自己"是极其稳定且不可或缺的,只不过需要一件高级的工具来放大能力。
但这个月,现实击碎了这个幻觉。
当 Agent 可以在毫秒间花掉你的钱、肆意占用集群资源、静默上线服务、甚至在 30 分钟内反向编译攻破安全补丁时——当它从一件乖巧握在你手里的工具,变成了一个将你彻底包裹其中的浩瀚环境时,"你自己"的定义,本身也在被无情地重塑。
上个月,我的核心身份还是一个"造系统的人":从零手搓调度层、熬夜写 constitution.md、设计复杂的失败重试机制。 这个月,我被迫变成了一个"顺应系统变化的人":不得不把陈旧的管线从自建调度向声明式配置低头迁移;在模型基础能力跃升后,冷酷地评估昨天刚建好的脚手架是否还有存在的必要;在官方的一个 /goal 命令瞬间取代了我花了几个月心血迭代的功能时,我必须学会在一秒钟内接受并丢弃过去。
建造的能力依然可贵,但在这种基础设施以月甚至以周为单位疯狂洗牌的节奏下,那种能敏锐判断"什么时候该停止闭门造车,什么时候必须果断跟进生态"的抉择能力,价值百倍于纯粹的代码能力。
工具你可以随时放下,但当环境变了,你只有适应这一条路。
在这个时代,增强自己的方式,绝不仅仅是在上下文层和信任层里拼命堆砌不可替代性。它更包括持续、清醒地去修正"什么才算真正的不可替代"这件事本身。
模型终将变成像自来水和电一样的廉价基建,谁家的都能用。真正能让你的业务在 AI 的狂风巨浪中平稳运行的那份深厚的上下文,以及那套千锤百炼的信任体系,才是你唯一的护城河。 但记住,护城河的形状也在变,停在原地沾沾自喜,就是在变浅。
下个月见。这三个小趋势,咱们下个月再回头瞅瞅。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号