QAgent:模块化搜索代理实现交互式查询理解

QAgent:模块化搜索代理实现交互式查询理解

梯度不陡
发布于 2026-05-18 19:50:43
发布于 2026-05-18 19:50:43
面对复杂查询,传统RAG系统常常陷入"检索即弃"的僵局,而现有搜索智能体又难以兼顾精准检索与系统集成能力。这项研究提出的QAgent框架,通过模块化设计和创新的两阶段训练策略,成功解决了这一双重困境。它不仅实现了对复杂问题的动态理解与自适应检索,更在作为系统子模块时展现出卓越的泛化性能,为知识密集型任务提供了全新的解决方案。
引言:3秒看懂QAgent有多强
传统检索增强生成系统在处理复杂查询时,准确率下降高达60%;现有搜索智能体的泛化能力普遍低于50%。面对多步推理任务,检索瓶颈成为显著挑战。
该论文提出QAgent,一个专注于查询理解的模块化搜索智能体。通过引入多轮交互决策机制与创新的两阶段强化学习方法,该框架实现了精准语义检索,在复杂问答场景中表现优异,并支持即插即用集成至现有系统。
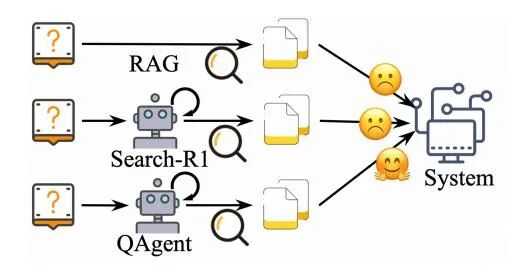
为什么传统搜索不够聪明
传统检索增强生成(RAG) 系统通常采用固定的 “检索-阅读”范式,其僵化的工作流程难以处理现实场景中涉及多步与复杂推理的问题。该论文指出,这类系统在决定何时检索以及检索什么方面存在明显局限,导致无法为复杂查询构建精准的搜索路径。
尽管引入了查询优化、规划与反思等策略,现有搜索智能体仍难以利用反馈实现持续迭代与性能优化。其缺乏有效的优化方法,限制了智能体能力的进一步发展,阻碍了自主进化。
实际部署中,搜索智能体面临严峻挑战。由于常作为子模块嵌入复杂系统,它们必须适应整体系统需求。然而,查询的复杂性可能导致基于原始查询直接检索的信息无效,而系统复杂性又迫使智能体聚焦于信息检索能力,而非信息利用能力,形成目标冲突。
基于强化学习(RL) 训练的智能体(如Search-R1)在自主推理方面取得了一定进展,但该论文指出,这些方法在效率与泛化性方面仍存在不足,限制了其作为可靠子模块在真实场景中的实际适用性。
QAgent的核心突破
该论文提出的QAgent框架在查询理解技术上实现关键突破,其核心在于多轮交互的模块化架构与创新的两阶段强化学习训练策略。该研究将复杂查询建模为随机序列决策过程,智能体通过规划、搜索、反思的循环与检索系统持续交互,自主优化查询策略,从而超越传统固定分解模式,展现出更强的灵活性与适应性。
在训练策略上,作者首先采用端到端强化学习,以严格格式与答案精确匹配作为奖励依据,同步优化检索与信息利用能力。然而,单一训练方式易导致模型后期偏向信息利用,削弱其作为专用检索模块的泛化能力。为此,该研究引入第二阶段广义强化学习,使用冻结的生成器基于检索结果生成答案并计算奖励。这一设计将优化目标与智能体生成能力解耦,迫使其聚焦于提升查询优化与信息检索质量。该两阶段策略有效规避了奖励黑客问题,确保QAgent在复杂系统中作为高效、通用子模块的部署能力。
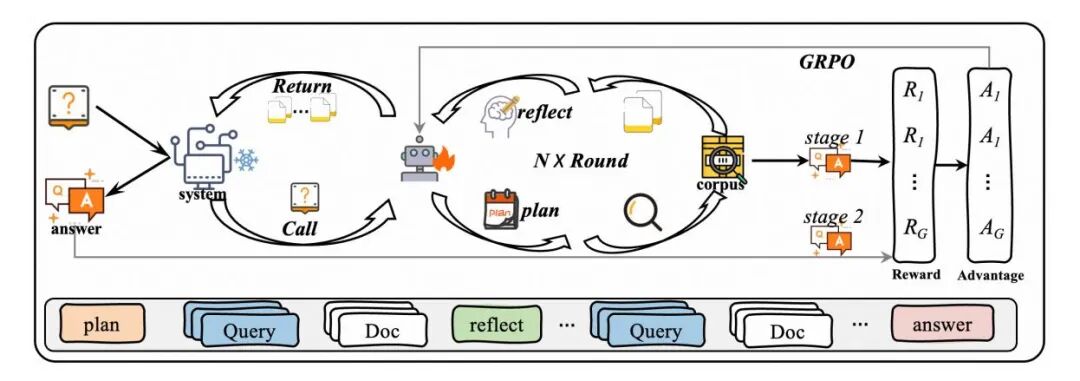
性能表现有多惊艳
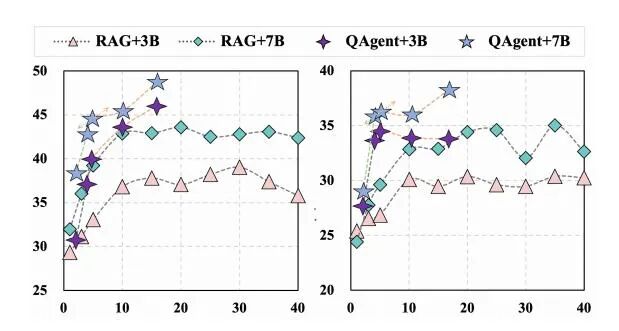
在复杂问答任务中,QAgent实现了29.43%的端到端准确率,超越现有最优方法0.52个百分点,F1分数达到33.23%,领先优势扩大至2.66个百分点。在主流数据集上的横向对比显示其全面性能优势:HotpotQA准确率达37.60%,显著高于Search-R1的35.00%和传统检索的23.20%;在2WikiMultiHopQA上准确率为38.20%,同样领先所有对比方法。 作为系统子模块时,QAgent展现出更强的泛化能力。配合7B生成器后,其在HotpotQA上的准确率跃升至42.40%,比Naive RAG高出6.4个百分点,平均准确率达31.94%,超越端到端优化的Search-R1达4.59%。该设计使复杂系统仅需配备轻量级QAgent即可实现检索质量的大幅提升,无需重新训练整个流水线。 消融实验证实,两阶段训练策略有效提升了模型在分布外数据集上的泛化性能:配合7B生成器时准确率从26.95%提升至31.94%。这种设计保证了QAgent作为独立组件时的稳定表现,为实际部署提供了可靠保障。
训练技巧大揭秘
该论文采用两阶段强化学习训练策略,旨在提升搜索智能体作为系统子模块的泛化能力。第一阶段实施端到端训练,直接优化答案正确性与格式规范,其奖励函数结合了格式奖励与严格精确匹配。尽管初期可能导致样本浪费,该方法有效保障了训练的稳定性与最终性能。
第二阶段为泛化训练,用于应对智能体在端到端训练中过度优化信息利用、从而削弱检索核心能力的问题。此阶段引入冻结的生成器,基于检索结果生成答案并计算奖励。其奖励设计更为宽松,取消格式约束,采用非严格精确匹配与命中奖励结合的方式,引导模型聚焦于信息检索质量的提升。
工程实现基于GRPO算法,通过组相对优势计算与KL散度约束确保策略更新的稳定性。两阶段训练协同作用:第一阶段奠定能力基础,第二阶段通过改变奖励信号源,系统性地增强智能体作为专用检索工具的泛化性与鲁棒性。
结语:智能搜索的未来
该研究采用两阶段强化学习方法,将智能搜索体在复杂问答任务中的泛化性能显著提升,作为子模块集成后,其平均EM值较传统方法高出5.35%。凭借其模块化设计,该框架能够与多种检索器和生成器实现即插即用,为构建高效智能问答系统提供了可行路径。
当前系统在大规模模型适配与段落多样性控制方面仍有优化空间,面对不同检索器偏好时,其鲁棒性仍需持续改进。作者指出,未来可进一步探索多模态检索扩展与工业级流水线部署,结合动态奖励机制增强系统的实用价值。随着轻量级搜索智能体逐渐成为系统标配,人机协作的边界或将迎来新的定义。
论文地址:https://arxiv.org/abs/2510.08383 开源地址:https://github.com/OpenStellarTeam/QAgent
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号