Nat. Commun. | CAPTAIN: 同时理解单细胞RNA与蛋白的多模态基础模型

Nat. Commun. | CAPTAIN: 同时理解单细胞RNA与蛋白的多模态基础模型

DrugAI
发布于 2026-05-14 18:23:19
发布于 2026-05-14 18:23:19
蛋白质是细胞功能的最终执行者,决定了细胞真实的表型状态。尽管单细胞转录组数据已经广泛应用于细胞状态解析,但RNA表达本身并不能完整反映蛋白质层面的功能变化。目前的大多数单细胞基础模型仅基于转录组训练,因此对细胞状态的理解存在天然局限。为了解决这一问题,研究人员提出了CAPTAIN,一个基于RNA与蛋白共同测量数据预训练的多模态单细胞基础模型。CAPTAIN在超过420万个同时具有RNA和蛋白数据的单细胞上进行训练,覆盖人类和小鼠13种组织,并整合了382种标准化细胞表面蛋白。研究结果显示,CAPTAIN能够学习统一的RNA-蛋白联合表示,准确捕捉不同生物背景下的细胞状态,并在蛋白质补全、细胞类型注释、批次校正和细胞通讯推断等任务中展现出优异性能。更重要的是,CAPTAIN还能在零样本条件下推断未测量蛋白,并提出与COVID-19免疫动态相关的潜在新型细胞通讯假说。

单细胞测序技术的发展极大提升了研究人员解析细胞异质性的能力。随着Human Cell Atlas等大型计划推进,数亿个单细胞转录组数据已经被测定,为基础模型的发展提供了庞大数据基础。在此背景下,scGPT、Geneformer、CellPLM等单细胞基础模型相继出现,它们借鉴自然语言模型的Transformer架构,将基因表达视为“语言”,学习细胞状态的潜在语义表示。
然而,目前这些模型几乎全部依赖RNA表达数据,而蛋白质才是真正执行细胞功能的核心分子。尤其在免疫系统、发育过程以及疾病状态中,细胞表面蛋白往往比RNA更能直接反映细胞真实表型。例如,许多免疫细胞亚群只能通过表面蛋白区分,而RNA表达并不足以提供精确分类。
CITE-seq等技术实现了单细胞RNA与蛋白同步测量,使研究人员能够同时观察转录组与表面蛋白。然而,不同实验之间使用的蛋白抗体面板差异巨大,通常只检测几十到几百个蛋白,加上批次效应和多模态整合困难,使得跨数据集分析仍然极具挑战。
因此,研究人员希望构建一个真正“蛋白感知(protein-aware)”的单细胞基础模型,使其不仅理解RNA表达,还能够统一建模RNA与蛋白之间的关系,从而更完整地描述细胞状态。CAPTAIN正是在这一背景下提出的。
方法
研究人员首先构建了目前规模最大的单细胞RNA-蛋白联合数据集scT&P-4M。该数据集整合了249个公开数据集,共包含420多万个单细胞,覆盖人类和小鼠13种组织,统一标准化了382种细胞表面蛋白。
CAPTAIN采用双编码器Transformer结构:RNA编码器负责学习转录组特征,蛋白编码器负责学习蛋白质特征,两者通过跨模态注意力机制进行融合,从而生成统一的细胞嵌入表示。RNA编码器还引入了基因调控网络、基因家族、共表达关系以及启动子序列等先验生物学知识,并继承了scGPT预训练权重。
在训练目标上,CAPTAIN同时优化三项任务:RNA掩码重建、蛋白表达预测以及蛋白表达区间估计。通过这种多任务联合训练,模型能够同时学习RNA内部关系以及RNA与蛋白之间的跨模态映射关系。
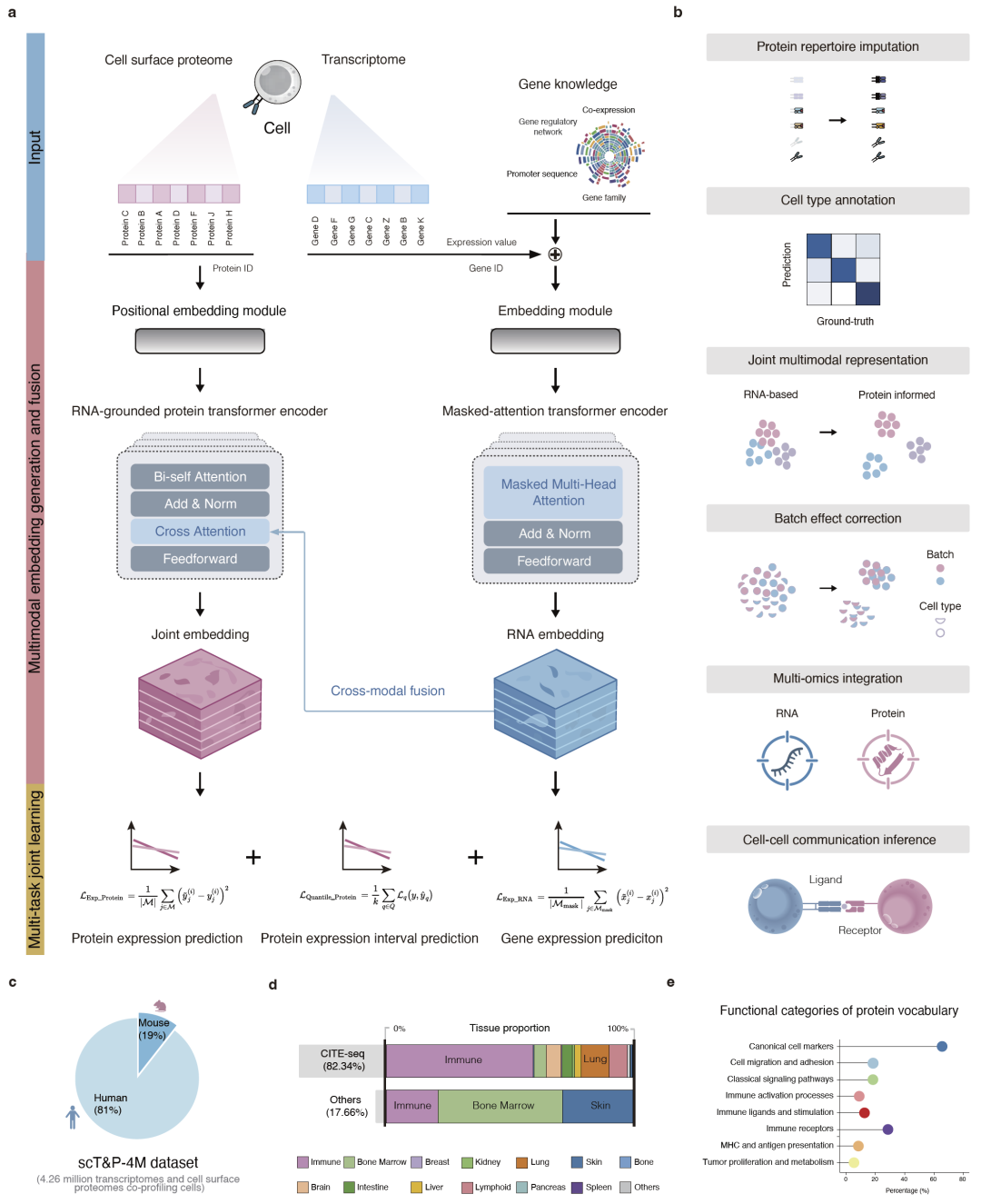
图1:CAPTAIN模型总体架构与多模态预训练流程图。
结果
CAPTAIN建立统一的RNA-蛋白细胞表示
研究人员首先验证了CAPTAIN是否能够学习统一的多模态细胞表示。结果显示,CAPTAIN通过跨模态注意力机制成功将RNA与蛋白信息映射到统一嵌入空间中,并能够跨组织、跨平台以及跨物种泛化。
与传统仅基于RNA训练的模型不同,CAPTAIN将蛋白视为“一级公民”,而不是辅助预测目标。这使模型能够真正学习RNA与蛋白之间的系统对应关系,并形成更加符合生物学意义的细胞状态表示。
研究人员还特别强调,CAPTAIN使用的382种标准化蛋白词汇表解决了不同实验抗体面板不一致的问题,使模型能够跨研究稳定泛化。
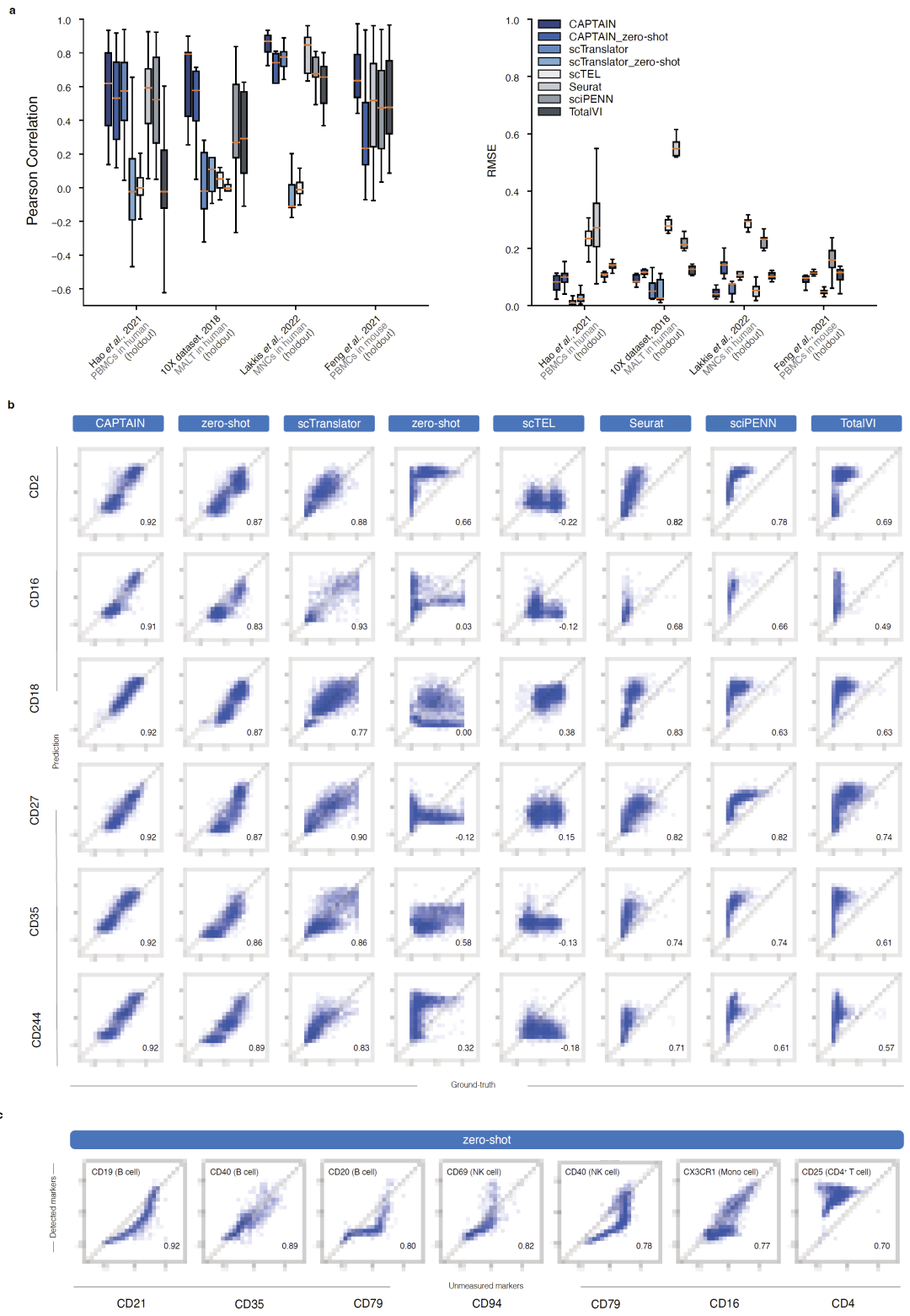
图2:CAPTAIN学习统一RNA-蛋白嵌入空间的示意图。
CAPTAIN实现高精度蛋白补全与零样本预测
研究人员重点评估了CAPTAIN从RNA预测蛋白的能力。结果显示,在多个CITE-seq数据集上,无论是微调模式还是零样本模式,CAPTAIN均显著优于Seurat、TotalVI、sciPENN、scTranslator和scTEL等现有方法。
尤其值得注意的是,CAPTAIN能够在完全没有见过特定蛋白测量数据的情况下,仅根据RNA表达推断其蛋白表达。例如,CD21、CD79、CD4和CD94等蛋白虽然在目标数据集中完全未测量,但CAPTAIN依然能够准确推断其表达模式,并正确对应B细胞、CD4 T细胞和NK细胞等经典免疫细胞类型。
研究人员认为,这种“零样本蛋白扩展”能力意味着CAPTAIN可以将传统CITE-seq几十个蛋白的检测能力,扩展到382个统一蛋白空间,从而极大丰富单细胞蛋白组信息。
CAPTAIN显著提升细胞类型注释能力
研究人员进一步评估CAPTAIN在细胞类型注释中的表现。结果显示,在PBMC CITE-seq数据集上,CAPTAIN实现了96.1%的整体分类准确率,大部分细胞类型精度超过90%。
更重要的是,CAPTAIN在精细免疫细胞亚群分类中优势明显。例如,在13种T细胞亚群数据集中,CAPTAIN成功区分CD4和CD8亚群,并达到0.73的Macro-F1分数,而Seurat仅为0.61,scGPT甚至只能将所有T细胞错误分类为CD4 naive T细胞。
研究人员指出,这说明仅依赖RNA表达难以解析高度相似的免疫细胞,而蛋白感知预训练显著增强了细胞表型解析能力。
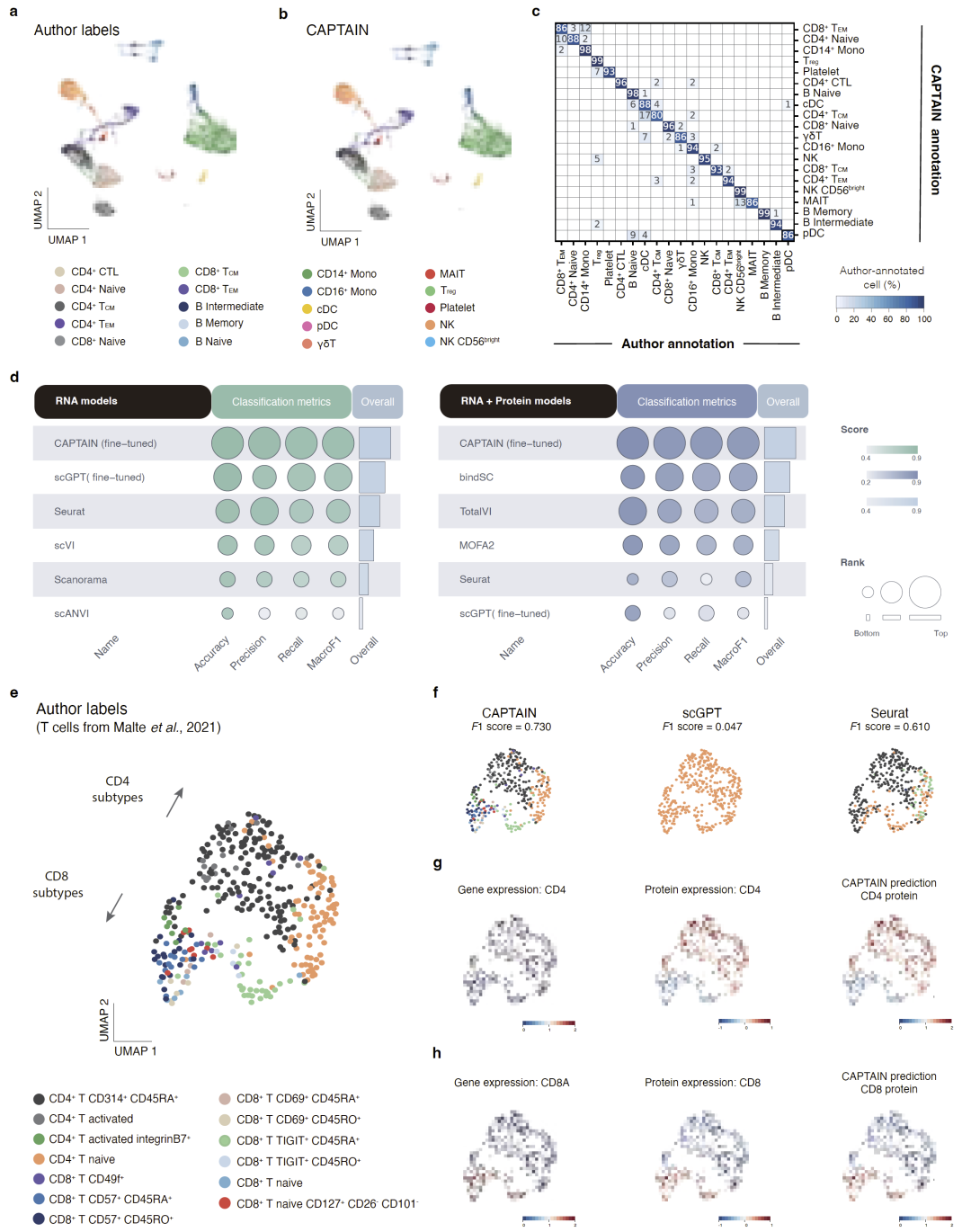
图3:CAPTAIN在细胞类型注释与T细胞亚群分类中的表现。
CAPTAIN实现跨平台多组学整合
研究人员随后测试了CAPTAIN在批次校正和多组学整合中的能力。CAPTAIN不仅成功整合不同批次PBMC和BMMC数据,还实现了CITE-seq、ECCITE-seq和TEA-seq三种不同多组学平台之间的统一嵌入。
尤其在超过60,000个细胞的大规模跨平台整合中,CAPTAIN依然能够有效消除技术差异,同时保留真实生物学结构。相比scVI、Harmony等方法,CAPTAIN在保留细胞亚群边界方面表现更优。
研究人员强调,这种能力对于未来构建真正统一的单细胞多模态图谱具有重要意义。
CAPTAIN实现蛋白感知的细胞通讯推断
最后,研究人员利用CAPTAIN进行蛋白感知的细胞通讯分析。传统细胞通讯方法通常仅依赖RNA表达推断配体-受体相互作用,而CAPTAIN能够先预测受体蛋白表达,再结合RNA中的配体信息进行推断。
在PBMC数据集中,CAPTAIN成功识别22个配体-受体相互作用,其中18个获得文献支持,验证率达到81.8%,显著优于CellChat、CellPhoneDB等传统方法。
研究人员进一步将CAPTAIN应用于COVID-19数据,发现随着疾病加重,血小板到单核细胞的通讯逐渐增强,尤其是S100A9-CD36信号轴在重症患者中显著激活。此前研究表明,该通路与COVID-19炎症反应密切相关。CAPTAIN还通过蛋白对接模拟验证了这一相互作用在结构上的合理性。
这说明CAPTAIN不仅能够恢复缺失蛋白信息,还能够发现传统RNA方法难以捕获的蛋白驱动通讯机制。
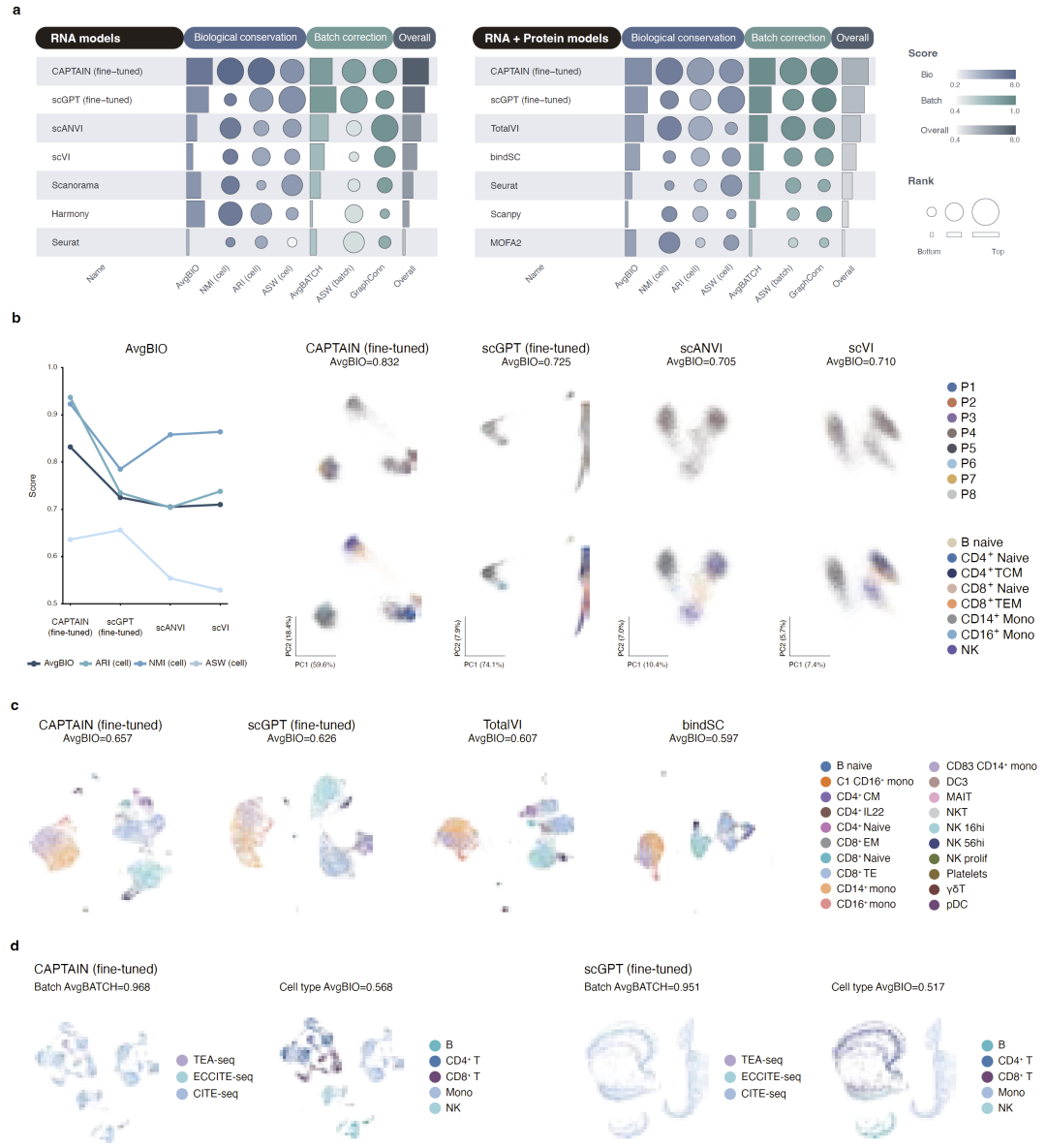
图4:CAPTAIN在多平台整合中的表现。
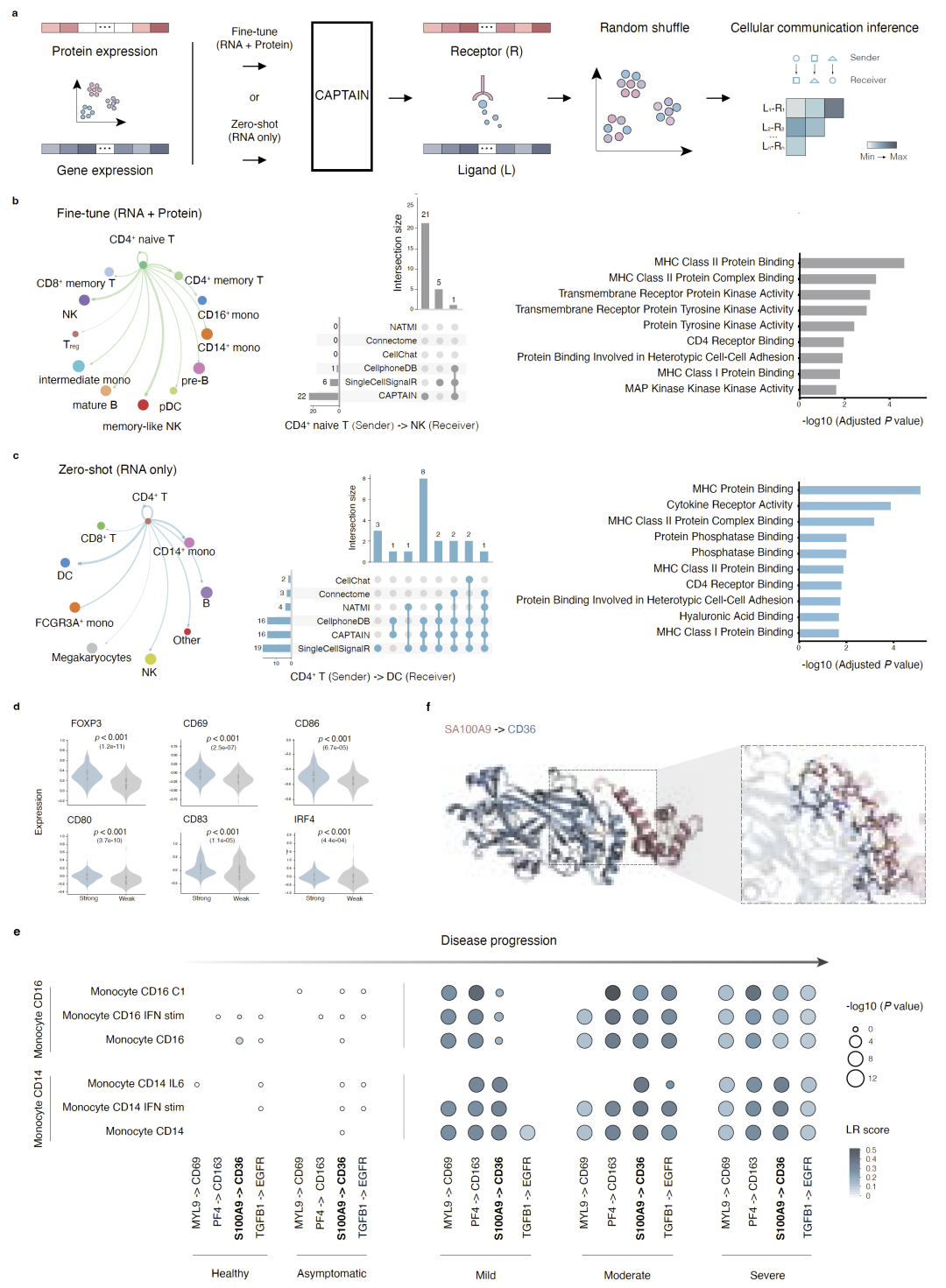
图5:CAPTAIN驱动的蛋白感知细胞通讯推断与COVID-19免疫相互作用分析。
讨论
该研究提出了CAPTAIN,一个真正意义上的“蛋白感知”单细胞基础模型。与传统单细胞基础模型相比,CAPTAIN最大的突破在于首次将蛋白作为核心建模对象,而不仅仅是下游预测目标。
研究结果显示,CAPTAIN不仅能够准确预测蛋白表达,还能够实现高精度细胞类型注释、跨平台多组学整合以及蛋白驱动的细胞通讯推断。这意味着未来即便实验中没有测量蛋白,也可以利用CAPTAIN从RNA中恢复丰富的蛋白信息。
此外,研究人员特别强调,当前单细胞多组学领域仍然存在明显数据偏倚。例如,大多数数据集中主要测量CD类免疫蛋白,而大量非CD蛋白仍然缺乏足够数据。因此,CAPTAIN目前的零样本能力仍然受到现有蛋白词汇表限制。未来随着更多组织和更丰富蛋白面板的出现,CAPTAIN的能力还有巨大提升空间。
总体而言,CAPTAIN代表了单细胞基础模型从“RNA时代”迈向“RNA+蛋白多模态时代”的重要一步。研究人员认为,随着未来更多多组学数据不断积累,类似CAPTAIN这样的模型有望成为解析细胞状态、疾病机制以及细胞间动态互作的重要基础设施。
整理 | DrugOne团队
参考资料
Ji, B., Hu, T., Wang, J. et al. CAPTAIN: a multimodal foundation model pretrained on co-assayed single-cell RNA and protein. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-72882-y

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号